C++语言
1. 说一下C++和C的区别?
设计思想上:C++是面向对象的语言,而C是面向过程的结构化编程语言。
语法上:C++具有封装、继承和多态三种特性;C++相比于C,增加了许多类型安全的功能,比如强制类型转换;C++支持范式编程,比如模板类、函数模板等
- C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现过程(事务)控制),而对于C++,首要考虑的是如何构造一个对象模型,让这个模型能够契合与之对应的问题域,这样就可以通过获取对象的状态信息得到输出或实现过程(事务)控制。
2. 说一下C++中的const关键字?
作用
- 修饰变量,说明该变量不可以被更改;
- 修饰指针,分为指向常量的指针(常量指针,pointer to const)和自身是常量的指针(指针常量,const pointer),表示无法通过该指针对数据进行更改
- 修饰引用,指向常量的引用(reference to const),用于形参类型,即避免了拷贝,又避免了函数对值的修改;
- 修饰成员函数,说明在该成员函数内不能修改成员变量。
- 默认仅在文件内有效
注意
在 C++ 中,const 成员变量不能在类定义处初始化,只能通过构造函数初始化列表进行,并且必须有构造函数。(现在好像可以了,但是如果在类const成员定义时赋值,那么初始化列表将不会再次将其初始化,也就是失效)
因为 const 数据成员 只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其 const 数据成员的值可以不同。所以不能在类的声明中初始化 const 数据成员,因为类的对象没被创建时,编译器不知道 const 数据成员的值是什么。
与define的比较
- 类型不同。宏定义是字符替换,没有数据类型的区别;const常量是常量的声明,有类型区别,需要在编译阶段进行类型检查。
- 存储方式不同。宏定义是直接替换,不会分配内存,存储于程序的代码段中;const常量需要进行内存分配,存储于程序的数据段中,并在堆栈分配了空间。
- 修饰函数的返回值:如给“指针传递”的函数返回值加const,则返回值不能被直接修改,且该返回值只能被赋值给加const修饰的同类型指针。
const只修饰其后的变量,至于const放在类型前还是类型后并没有区别。如:
const int a和int const a都是修饰a为const;
如果有指针运算符*,那么从右往左将变量与*看成一个整体,如
int const * const p1,p2; p2是const,是前一个const修饰的,*p1也被前一个const修饰,而p1被后一个const修饰。
3. 说一下常量指针和指针常量?
区分技巧:把const读作常量,把星号*读作指针,例如:
int * const p 就是指针常量(const pointer),p是常量,初始化后不能再指向其它变量
int const * p 就是常量指针(pointer to const),*p是常量,不能通过*p更改其指向的内容
常量指针:顾名思义就是一个指向常量的指针,该常量不可通过该指针更改(其它方式可以更改),但该指针可以指向其它位置。
指针常量:顾名思义就是一个指针类型的常量,必须在声明的同时对其初始化。指针所指向的位置不可改变,但指针所指向的位置处的内容可以改变。
{
//定义变量
int a=1;
//定义常量
const int b=2;
//定义常量指针,可不初始化
const int *ptr1=&a; //*ptr1是常量
//定义指针常量,必须初始化
int* const ptr2=&a; //ptr2是常量
//错误,不能把常量的地址赋给指针变量
int *ptr3=&b;
//正确,可以把常量的地址赋给常量指针
const int* ptr4=&b; //*ptr4是常量
//错误,间接引用常量指针不可以修改内存中的数据
*ptr1=3;
//正确,间接引用指针常量可以修改内存中的数据
*ptr2=4;
//正确,常量指针可以指向其他变量
ptr1=&b;
//错误,指针常量不可以指向其他变量
ptr2=&b;
//常量指针常量,既不可以间接引用修改内存数据,也不可以指向别的变量
const int * const ptr5=&a; //ptr5和*ptr5都是常量
//错误,不可以间接引用修改内存数据
*ptr5=5;
//错误,不可以修改指向的对象
ptr5=&b;
}
4. 说一下static关键字有什么用?
4.1 修饰普通变量
修改变量的存储区域(生命周期)或作用域,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
静态全局变量:全局变量本身就是静态区,因此仅仅改变其作用域。作用域缩小为当前文件,其它文件即使使用extern声明也不能使用该变量。
静态局部变量:仅改变存储区域。作用域仅为局部作用域,当定义它的函数或语句块结束时其作用域也随之结束,但是它始终驻留在全局数据区,直到程序运行结束,和静态全局变量一样。
4.2 修饰普通函数
表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定义为 static。修改的是作用域。
4.3 修饰成员变量
修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。对一个类的多个对象来说,静态数据成员只分配一次内存,供所有对象共用,包括派生类的成员对象。所以,静态数据成员的值对每个对象都是一样的,它的值可以更新。修改的是存储区域。
4.4 修饰成员函数
修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。与普通函数相比,静态成员函数由于不是与任何的对象相联系,因此它不具有this指针。从这个意义上讲,它无法访问属于类对象的非静态数据成员,也无法访问非静态成员函数,它只能调用其余的静态成员函数。修改的是存储区域。
注意:不可以同时用const和static修饰成员函数。
5. 说一下this指针?
-
this指针是一个隐含于每一个非静态成员函数中的特殊指针。它指向调用该成员函数的那个对象。 -
当对一个对象调用成员函数时,编译程序先将对象的地址赋给
this指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式使用this指针。 -
当一个成员函数被调用时,自动向它传递一个隐含的参数,该参数是一个指向这个成员函数所在的对象的指针。
-
this指针被隐含地声明为:ClassName *const this,这意味着不能给this指针赋值;在ClassName类的const成员函数中,this指针的类型为:const ClassName* const,这说明不能对这种对象的数据成员进行赋值操作); -
this并不是一个常规变量,而是个右值,所以不能取得this的地址(不能&this)。 -
在以下场景中,经常需要显式引用this指针:
- 为实现对象的链式引用;
- 为避免对同一对象进行赋值操作;
- 在实现一些数据结构时,如
list。
6. 说一下volatile有什么含义
注意
C/C++多线程编程中不要使用volatile。C++11标准中明确指出解决多线程的数据竞争问题应该使用原子操作或者互斥锁。
volatile int a = 1;
volatile可以解释为直接存取原始内存地址
- volatile 关键字是一种类型修饰符,一个定义为 volatile 的变量是说这变量可能会被意想不到地改变,或者说用它声明的变量表示 可以 被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。即每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
- const 可以是 volatile (如只读的状态寄存器)
- 指针可以是 volatile(如当一个中断服务子程序修改一个指向一个buffer的指针时)
使用场景
- 中断服务程序中修改的供其它程序检测的变量需要加volatile;
- 多任务环境下各任务间共享的标志应该加volatile;
- 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;
多线程
有些变量是用volatile关键字声明的。当两个线程都要用到某一个变量且该变量的值会被改变时,应该用volatile声明,该关键字的作用是防止优化编译器把变量从内存装入CPU寄存器中。如果变量被装入寄存器,那么两个线程有可能一个使用内存中的变量,一个使用寄存器中的变量,这会造成程序的错误执行。volatile的意思是让编译器每次操作该变量时一定要从内存中真正取出,而不是使用已经存在寄存器中的值。
volatile 指针
和 const 修饰词类似,const 有常量指针和指针常量的说法,volatile 也有相应的概念:
-
修饰由指针指向的对象、数据是 const 或 volatile 的:
const char* cpch; volatile char* vpch; -
指针自身的值——一个代表地址的整数变量,是 const 或 volatile 的:
char* const pchc; char* volatile pchv;
7. 说一下assert()
断言不是函数,而是一个宏。assert 宏的原型定义在 <assert.h>(C)、<cassert>(C++)中,其作用是先计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。
但是频繁的调用会极大的影响程序的性能,增加额外的开销。在调试结束后,可以通过在包含#include <assert.h>的语句之前插入 #define NDEBUG 来禁用assert调用,记住必须是在#include<assert.h> 之前。
assert() 使用:
#define NDEBUG // 加上这行,则 assert 不可用
#include <assert.h>
assert( p != NULL ); // assert 不可用
8. 说一下sizeof()
sizeof 也不是函数,而是C/C++中的一个判断数据类型或者表达式长度的操作符(operator),在编译阶段进行处理,作用是返回一个对象或者类型所占的内存字节数。其返回值类型为size_t,在头文件stddef.h中定义。这是一个依赖于编译系统的值,一般定义为
typedef unsigned int size_t;
sizeof 计算对象的大小是转换成对对象类型的计算,也就是说,同种类型的不同对象其sizeof值都是一致的。sizeof对一个表达式求值,编译器根据表达式的最终结果类型来确定大小,一般不会对表达式进行计算。
结构体的sizeof
结构体的sizeof并不是简单地将结构体成员的类型的sizeof加起来就完事的,因为存在字节对齐(提高计算机的存取速度)。字节对齐的细节和编译器实现有关,但一般而言,满足三个准则:
- 结构体变量的首地址能够被其最宽基本类型成员的大小所整除
- 结构体每个成员相对于结构体首地址的偏移量(offset)都是相应成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal padding)
- 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)
注意:如果结构成员中有结构体,那么最宽成员应该包括该结构体中的结构体的子成员,即把所有结构体打散只看基本类型成员的sizeof大小;C++中“空结构体”(不含数据成员)的大小不为0,而是1
和strlen()的区别
- sizeof是运算符,strlen是函数。
- 大部分编译程序在编译的时候就把sizeof计算出来了,是类型占内存的大小;而strlen的结果要在运行的时候才能计算出来,是用来计算字符串的长度,不是类型占内存的大小。
- sizeof可以用类型做参数,strlen只能用char*做参数,且必须是以’‘\0’‘结尾的。
9. 说一下C++中的class和struct?
我们要知道C++中的struct已经不再是C中的struct了,在C++中struct几乎可以等同于class,struct可以包含成员函数、可以继承、可以实现多态等等。总之class可以实现的struct几乎都可以实现。下面是二者之间的少有的几点不同之处:
- class默认是私有继承(private),struct默认是公有继承(public)。
- class中默认的成员访问权限是private的,而struct中则默认是public的。
- 如果定义了构造函数,二者都不能使用大括号对其进行初始化。如果没有定义构造函数,struct可以使用大括号{ }进行初始化,而class只有当所有数据成员及函数都为public时,可以使用{ }进行初始化(??)
10. 说一下inline内联函数
普通函数在调用的时候需要跳转到函数的代码区域执行指令,执行完后再跳转回来。而内联函数则是将函数代码嵌入到调用者的代码区,使得其不用跳转直接就可以执行,提高了程序的运行速度。 但是有一个缺点就是如果程序多次调用内联函数,那么程序将包含该函数的多个副本,也就是占用了更多内存。另一个缺点是内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器,程序员不可控。
要使用内联函数只需要在函数声明或定义前加上关键字inline。通常的做法是省略原型,将整个定义(即函数头和所有函数代码)放在本应提供原型的地方。
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
- 相当于宏,却比宏多了类型检查,真正具有函数特性;
- 编译器一般不内联包含循环、递归、switch 等复杂操作的内联函数;
- 在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。(所以一般特别简单的函数才直接在类声明中实现)
11. 说一下面向对象?
面向对象程序设计(Object-oriented programming,OOP)是一种具有对象概念的程序编程典范,同时也是一种程序开发的抽象方针。
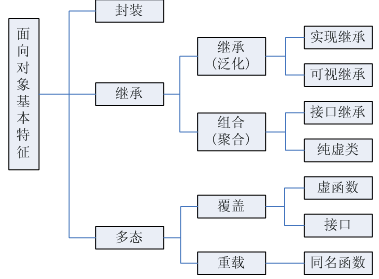
面向对象三大特征 —— 封装、继承、多态
12. 说一下封装?
封装,即隐藏对象的属性和实现细节,仅对外公开接口。数据隐藏(将数据放在类的私有部分中)是 一种封装,将类函数定义和类声明放在不同的文件中也是一种封装。总的来说封装就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。关键字:public, protected, private。默认为 private。
public成员:可以被任意实体访问protected成员:只允许被子类及本类的成员函数访问private成员:只允许被本类的成员函数、友元类或友元函数访问
13. 说一下继承?
- 继承就是从一个已有的类派生出一个新的类,原来的类叫做基类,新的类叫做派生类。派生类继承了基类的特征,包括方法。
- 一个派生类由多个组成部分组成:一个含有自己定义的成员的子对象,一个与该类继承的基类对应的子对象。如果继承自多个基类,那么这样的子对象也有多个。
- 使用基类的指针或引用指向派生类其实就是将基类的指针或引用指向或绑定到派生类中的基类部分上。
- 每个类控制其自己成员的初始化,即派生类不能初始化其基类的成员变量,必须调用基类的构造函数初始化
- C++ 11提供了一种防止继承发生的方法,即在类后面跟一个关键字final,如
class base final{}; - 当我们用一个派生类对象为一个基类对象初始化或赋值时,该派生类对象中只有基类部分会被拷贝、移动或赋值,而其它部分会被忽略
- 外界只能访问类中的public成员(静态成员不是public也不行)。派生类可以访问继承来的基类中的public和protected成员,但基类中的private私有成员只允许基类类自己成员访问
- 继承也分为public、protected、private,public表示不对基类做保护,外界可以通过该继承类访问其基类的public成员;protected继承表示对基类做保护,基类中的public在该派生类中对外界来说是protected的,因此外界不能访问;private一般来说少用,基类中的成员在派生类中对外界全部表示为private
- 使用using 可以将基类中的成员设置成相应的访问级别。但是派生类只能为那些它可以访问的基类成员提供using声明。using声明语句中成员的访问权限由该声明语句之前的访问说明符决定(就是看using是放在public、protected、private中哪个的下面)
14. 说一下多态?
多态就是为函数或运算符创建多个定义,通过上下文来确定具体使用哪个定义。
- 多态是以封装和继承为基础的。
- C++ 多态分类及实现:
- 重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载
- 子类型多态(Subtype Polymorphism,运行期):虚函数
- 参数多态性(Parametric Polymorphism,编译期):类模板、函数模板
- 强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
静态多态(编译期/早绑定)
对非虚函数的调用以及通过对象进行的虚函数的调用是在编译时绑定的。
函数多态(函数重载),即定义一系列具有相同函数名但不同参数列表的函数。
class A
{
public:
void do(int a);
void do(int a, int b);
};
动态多态(运行期/晚绑定)
当且仅当通过引用或指针调用虚函数时,才会在运行时解析该调用。
虚函数:在基类中冠以关键字 virtual 的成员函数。 它提供了一种接口界面。允许在派生类中对基类的虚函数重新定义。
目的:接口重用。封装可以使得代码模块化,继承可以扩展已存在的代码,他们的目的都是为了代码重用。而多态的目的则是为了接口重用。
15. 说一下::范围解析运算符
- 全局作用域符(
::name):用于类型名称(类、类成员、成员函数、变量等)前,表示作用域为全局命名空间 - 类作用域符(
class::name):用于表示指定类型的作用域范围是具体某个类的 - 命名空间作用域符(
namespace::name):用于表示指定类型的作用域范围是具体某个命名空间的
16. 说一下namespace命名空间
命名空间就是定义一种新的声明区域来创建命名的名称空间,这样做的目的之一是提供一个声明名称的区域。一个名称空间中的名称不会与另外一个名称空间的相同名称发生冲突,同时允许程序的其他部分使用该名称空间中声明的东西
using声明和using编译命令
using声明使特定的标识符可用。using声明由被限定的名称和它前面的关键字using组成:
using std::cout;
cout << "now we can use cout!";
using编译指令使整个名称空间可用。using编译指令由名称空间名和它前面的关键字using namespace组成:
using namespace std; //make names available globally
建议:一般说来,使用using声明比使用using编译指令更安全,这是由于它只导入指定的名称。如果该名称与局部名称发生冲突,编译器将发出指示。using编译指令导入所有名称,包括可能并不需要的名称。如果与局部名称发生冲突,则局部名称将覆盖名称空间版本,而编译器并不会发出警告。另外,名称空间的开放性意味着名称空间的名称可能分散在多个地方,这使得难以准确知道添加了哪些名称。
总之,尽量少使用using编译:
using namespace std;
而多使用using声明:
char c;
std::cin >> c;
std::cout << c << std::endl;
或者:
using std::cin;
using std::cout;
using endl;
char c;
cin >> c;
cout << c << endl;
17. 说一下重载和重写
重载(overload):是指允许存在多个同名函数,这些函数参数不同(类型、数目或顺序),根据参数列表确定调用哪个函数,在编译期间完成选择,因此和多态无关。重载不关心函数返回类型。
重写(override):即虚函数,和多态真正相关。是指派生类中存在重新定义的函数。其函数名、参数列表、返回值类型等所有都必须同基类中被重写的函数一致。只有函数体不同(花括号内)。派生类调用时会调用派生类的重写函数,不会调用被重写函数。重写基类中的虚函数必须有virtual修饰。这样的函数调用在编译期间是无法确定的(调用的子类的虚函数的地址无法给出)。因此,这样的函数地址是在运行期绑定的(晚绑定)。
18. 说一下虚函数机制
虚函数
简单地说,那些被virtual关键字修饰的类成员函数,就是虚函数。一般将基类希望其派生类覆盖的函数定义为虚函数。而纯虚函数是在基类中只声明而没有定义的虚函数。任何派生类都需要定义自己的实现方法。
注意:关键字virtual只能出现在类内部的声明语句之前而不能用于类外部的函数定义
在基类中实现纯虚函数的方法是在函数原型后加“=0”(类内部的函数声明语句处):
virtual void funtion1(参数列表)=0;
- 类里如果声明了虚函数,这个函数是实现的,哪怕是空实现,它的作用就是为了能让这个函数在它的子类里面可以被覆写(override),这样的话,编译器就可以使用后期绑定来达到多态了。纯虚函数只是一个接口,是个函数的声明而已,它要留到子类里去实现。
- 虚函数在子类里面可以不重写;但纯虚函数必须在子类实现才可以实例化子类。
- 虚函数的类用于 “实作继承”,继承接口的同时也继承了父类的实现。纯虚函数关注的是接口的统一性,实现由子类完成。
- 带纯虚函数的类叫抽象类,这种类不能直接生成对象,而只有被继承,并重写其虚函数后,才能使用。抽象类被继承后,子类可以继续是抽象类,也可以是普通类。
- 虚基类是虚继承中的基类,具体见下文虚继承。
虚函数表
C++多态是由虚函数来实现的,而虚函数是由虚函数表来实现的。通常,编译器处理虚函数的方法是:给每个对象添加一个隐藏成员。隐藏成员中保存了一个指向函数地址数组的虚指针(虚指针存在于对象实例地址的最前面,保证虚函数表有最高的性能)。这种数组称为虚函数表(virtual function table,vtbl)。 虚函数表中存储了为类中声明的虚函数的地址。如果派生类提供了虚函数的新定义(重写),该虚函数表将保存新函数的地址;如果派生类没有重新定义虚函数,该vtbl将保存函数原始版本的地址。如果派生类定义了新的虚函数,则该函数的地址也将被添加到vtbl中。
注:对象不包含虚函数表,只有虚指针,类才包含虚函数表,派生类会生成一个兼容基类的虚函数表
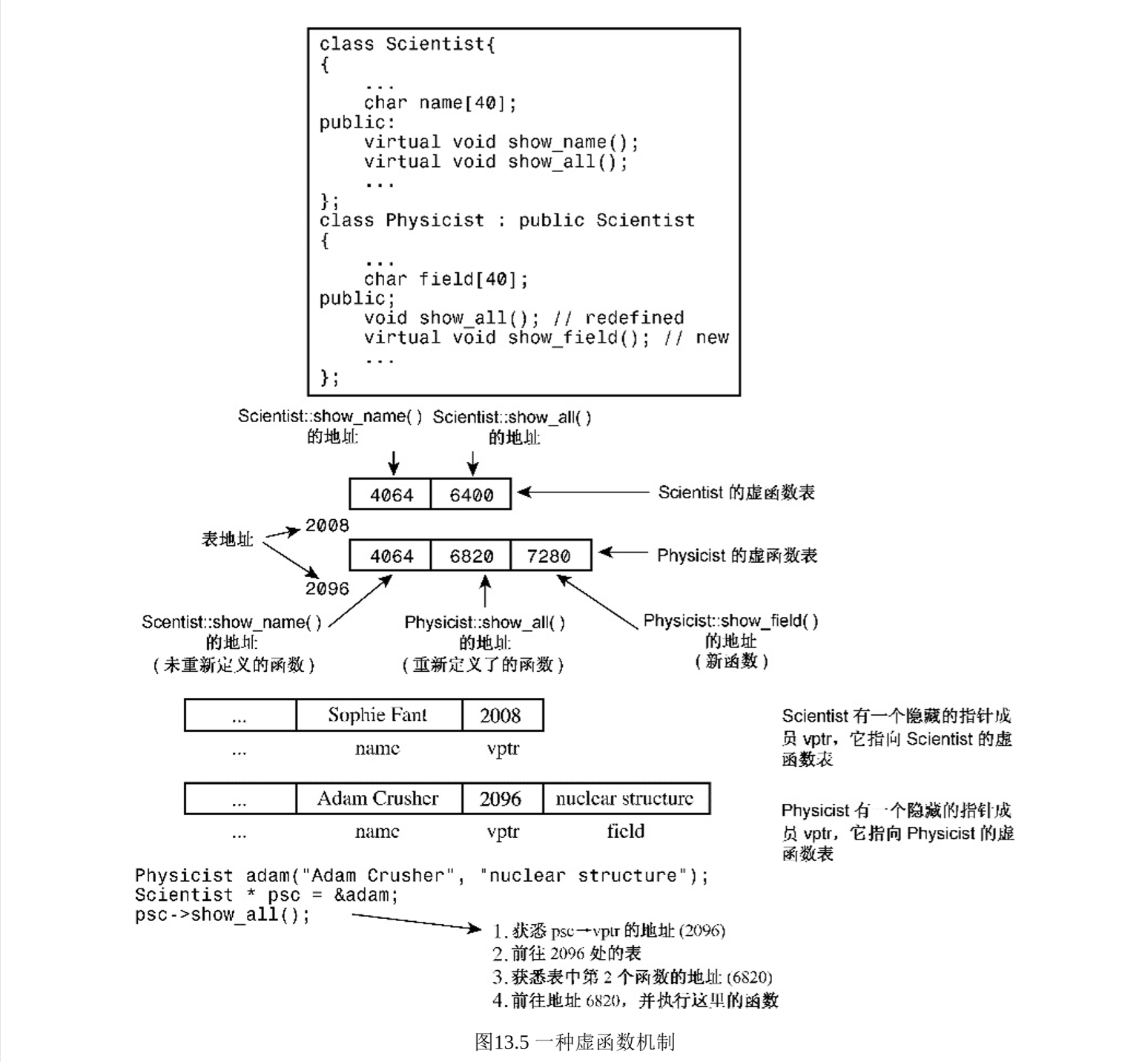
编译器如何在虚函数表中定位具体函数
由于虚函数表是一块连续的存储空间,并且每个元素都是指针,大小是固定的,因此可以看作是数组。
该数组是编译器在编译器生成的,并且生成后就不再改变,运行期间不可能会新增或更改。也就是说,虚函数表的构建和存取都是由编译器掌控的。
在运行期,调用的虚函数地址存在于该虚函数表中,为了找到该表格,每一个对象被安插了一个由编译器内部产生的指针,指向该表格。为了找到函数地址,每一个虚函数被指派一个表格索引值(作为数组索引)。
19. 说一下虚继承与虚基类
多继承(Multiple Inheritance,MI),即一个派生类可以有两个或多个基类。MI有两个主要问题:
- 从两个不同的基类继承同名方法(函数调用二义性,可以使用作用域解析运算符::来解决)
- 从两个或更多相关基类那里继承同一个类的多个实例(虚基类解决)

虚基类
虚基类使得从多个类(它们的基类相同)派生出的对象只继承一个基类对象。例如, 通过在类声明中使用关键字virtual,可以使Worker被用作Singer和Waiter的虚基类(virtual 和public的次序无关紧要):
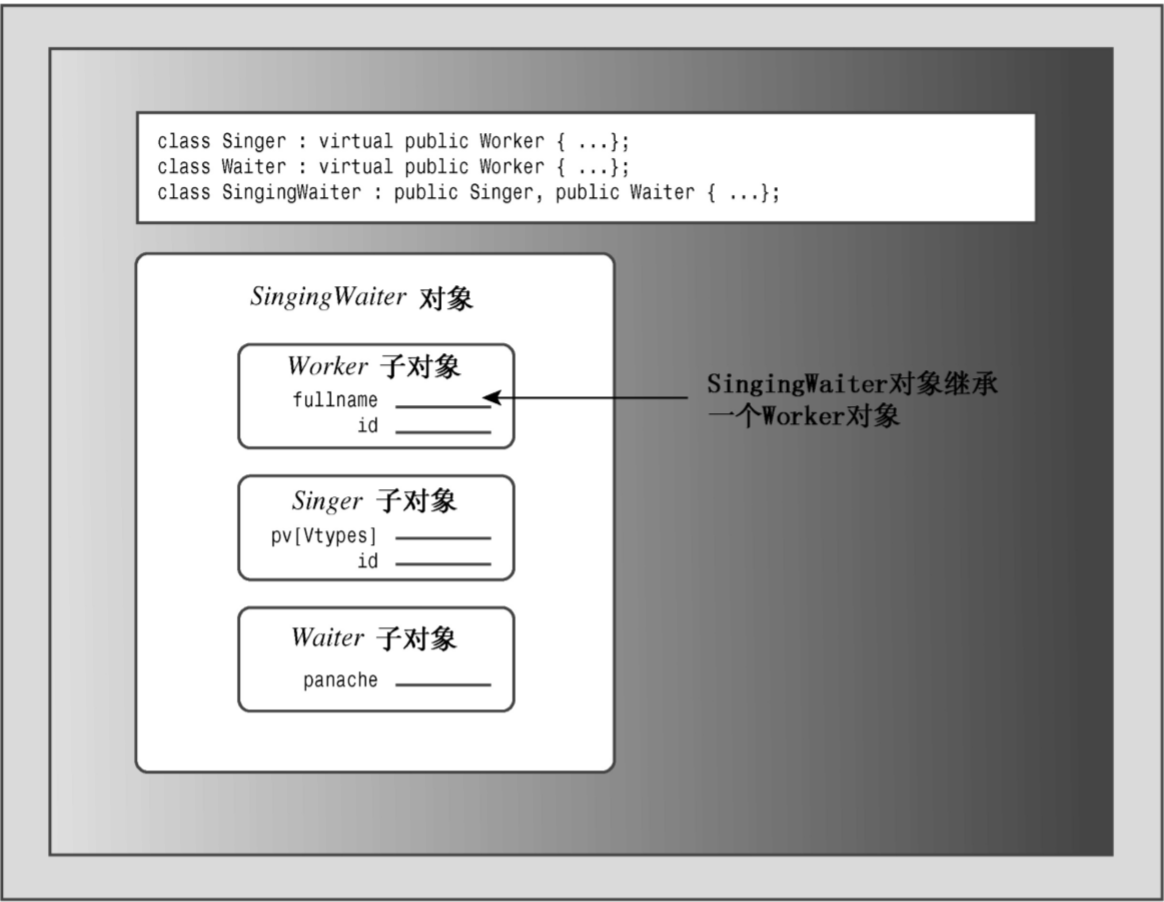
混合使用虚基类和非虚基类
如果基类是虚基类,派生类将包含基类的一个子对象;如果基类不是虚基类,派生类将包含多个子对象。当虚基类和非虚基类混合时,情况将如何呢?例如,假设类B被用作类C和D的虚基类,同时被用作类X和Y的非虚基类,而类M是从C、D、X和Y派生而来的。在这种情况下,类M从虚派生祖先(即类C和D)那里共继承了一个B类子对象,并从每一个非虚派生祖先(即类X和 Y)分别继承了一个B类子对象。因此,它包含三个B类子对象。
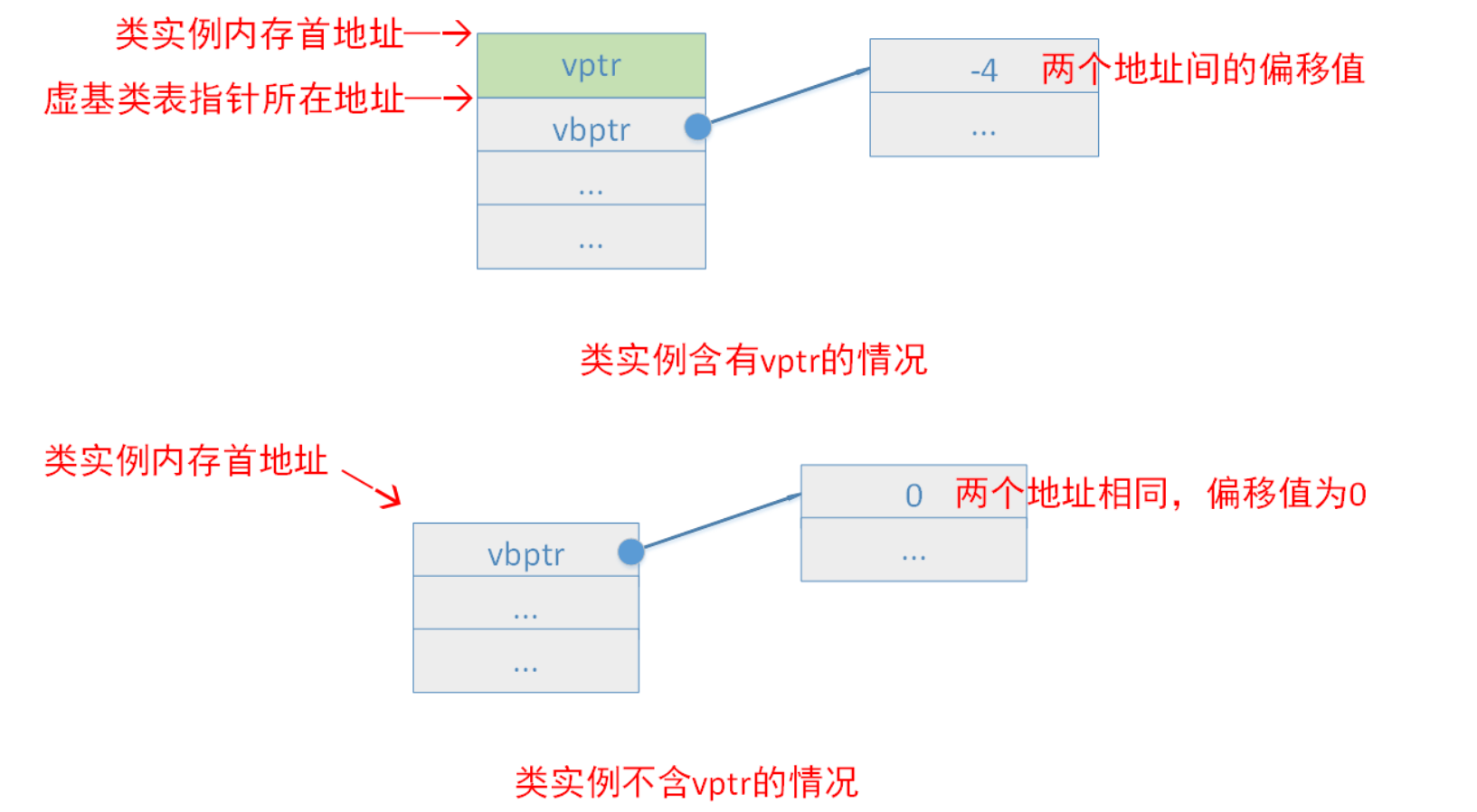
底层实现
底层实现原理与编译器相关,一般通过虚基类指针和虚基类表实现,每个虚继承的子类都有一个隐藏的虚基类指针(vbptr)和虚基类表(不占用类对象的存储空间);当虚继承的子类被当做父类继承时,虚基类指针也会被继承。
实际上,vbptr 指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚基类表(virtual table),虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员,而虚继承也不用像普通多继承那样维持着公共基类(虚基类)的两份同样的拷贝,节省了存储空间。
虚基类表指针总是在虚函数表指针之后。一个类对象的虚基类指针指向的虚基类表,与虚函数表一样,虚基类表也由多个条目组成,条目中存放的是偏移值。第一个条目存放虚基类表指针(vbptr)所在地址到该类对象内存首地址的偏移值,由第一段的分析我们知道,这个偏移值为0(类没有vptr)或者-4(类有虚函数,此时有vptr)。我们通过一张图来更好地理解。
多继承中的构造函数调用顺序
- 任何虚基类的构造函数按照它们被继承的顺序构造。
- 任何非虚基类的构造函数按照它们被构造的顺序构造。
- 任何成员对象的构造按照它们声明的顺序调用。
- 类自身的构造函数。
20. 说一下类、对象及其成员的内存分布
20.1 类
类的实质是一种引用数据类型,类似于byte、short、int(char)、long、float、double等基本数据类型,不同的是它是一种复杂的数据类型。因为它的本质是数据类型,而不是数据,所以不存在于内存中,不能被直接操作,只有被实例化为对象时,才会变得可操作。
20.2 对象
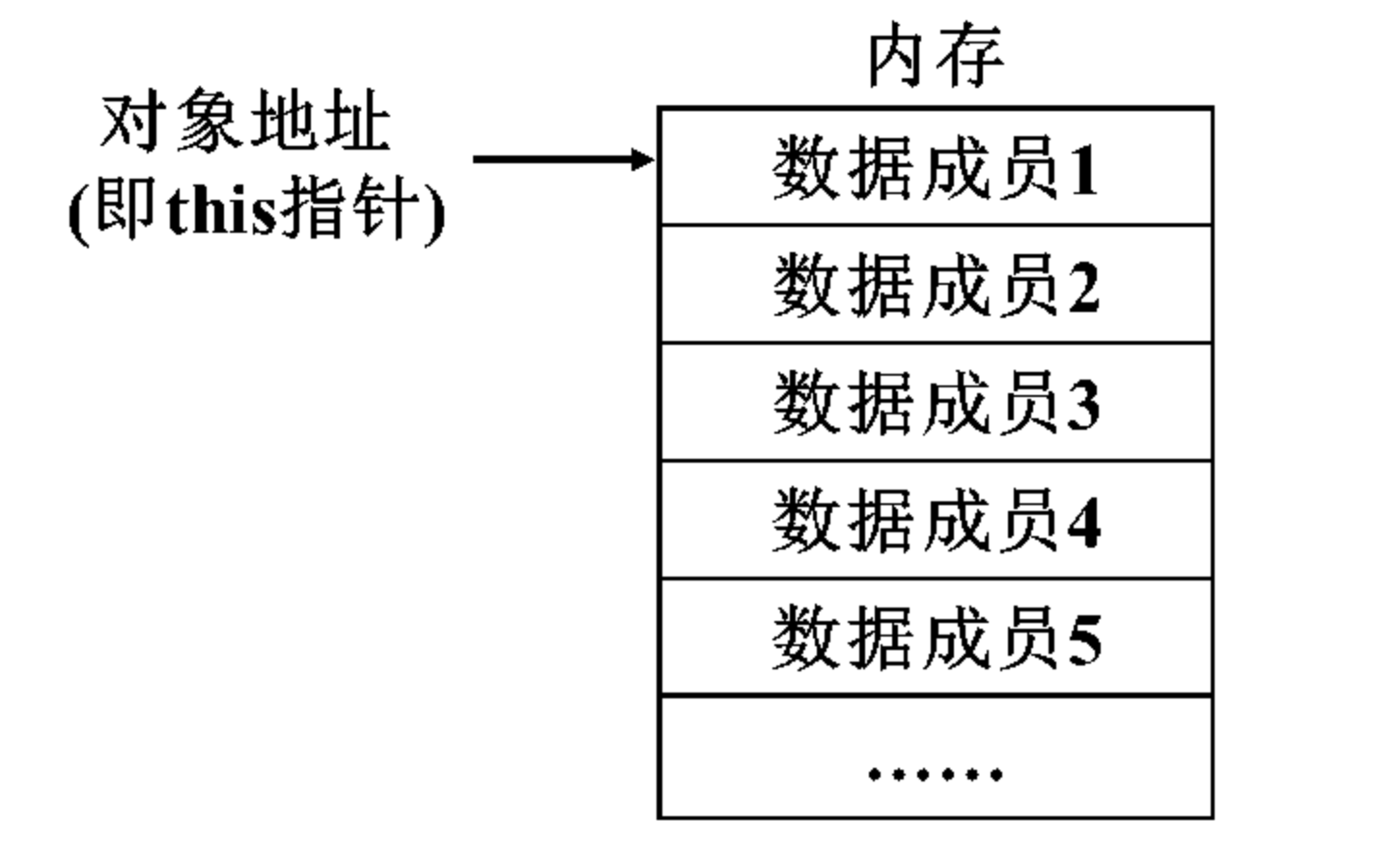
对象是类的实例,用类定义对象时,系统会为每一个对象分配内存空间。对于静态数据成员,它不属于类的某个对象,存储在全局变量区;而非静态数据成员则以连续存储的方式存储在内存中,对象的数据成员是根据this指针以及该数据成员与this的偏移量来获取的,如图:
然而对象的存储空间大小往往并不等于各个数据成员的存储空间总和,这是因为对象的存储空间大小还与以下因素有关:
-
虚函数
含有虚函数的类的对象比普通类对象多一个虚函数指针vptr,因此存储空间应多出sizeof(vptr)字节的内存。
-
虚基类
虚基类的对象往往比普通类对象多一个指向虚基类表的虚基类表指针vbptr,因此存储空间也应多出sizeof((void*)0)字节的内存。
-
字节对齐
字节对齐是指编译器会在数据成员之间自动填充一些字节,这里可以照搬上面sizeof中的结构体的sizeof。
-
空类
空类是指没有任何数据成员的类,为了标识它的不同对象,编译器往往会给空类对象分配1个字节的内存空间。有趣的是,继承自空类的空类,编译器也往往只给它分配1个字节的空间,而不是2个字节,以避免空间的浪费;继承自空类的非空类,编译器往往会忽略空类1个字节的空间,只计算非空类自身数据成员所占的空间。
20.3 成员函数
C++中的函数在编译时会根据命名空间、类、参数签名等信息进行重新命名,形成新的函数名。这个重命名的过程是通过一个特殊的算法来实现的,称为名字编码(Name Mangling)。
C++类中函数代码是存储在对象空间之外的(不占用类对象空间)。如果对同一个类定义了10个对象,这些对象的成员函数对应的是同一个函数代码段,而不是10个不同的函数代码段。
C++规定,编译成员函数时要额外添加一个参数,把当前对象的指针传递进去,通过指针来访问成员变量
例如:
void Demo::display() {
cout << a << endl;
cout << b << endl;
}
那么编译后的代码就类似于:
void new_function_name(Demo * const p) {
//通过指针p来访问a、b
cout << p->a << endl;
cout << p->b << endl;
}
使用obj.display()调用函数时,也会被编译成类似下面的形式:
// obj.display()
new_function_name(&obj);
总结:编译器通过指针来访问成员变量,指针指向哪个对象就使用哪个对象的数据;编译器通过指针的类型来访问成员函数,指针属于哪个类的类型就使用哪个类的函数。
21. 说一下友元关系?
有时候类的访问权限控制显得有些呆板,因此C++提供了另一种访问控制权限:友元。友元分三种:
- 友元函数
- 友元类
- 友元成员函数
性质
- 友元关系不具对称性。即 A 是 B 的友元,但 B 不一定是 A 的友元。
- 友元关系不具传递性。即 A 是 B 的友元,B 是 C 的友元,但是 A 不一定是 C 的友元。
- 友元关系不能被继承。
21.1 友元函数
友元函数是能够访问类中的私有成员的非成员函数,需要在对应的类中使用friend关键字声明:
friend int add(int a, int b);
然后再在类外定义,注意因为友元函数不是成员函数,因此定义时不需要使用 类名:: 限定符,也不再需要使用关键字friend了。
21.2 友元类
友元除了函数以外,还可以是类,即一个类可以作另一个类的友元。当一个类作为另一个类的友元时,这就意味着这个类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。
定义友元类:
friend class 类名(即友元类的类名);
21.3 友元成员函数
即让类中的一个成员函数作为另一个类的友元函数,而不必让整个类作为另一个类的友元类。一定要注意各种声明和定义的顺序。
例如:
class A {
private:
int age;
public:
//...
};
class B {
public:
void set_age(A& a){
a.age = 0;
};
//...
};
我们需要把类B中的set_age作为类A的友元成员函数,因此我们重新定义类A:
class A{
private:
int age;
public:
friend void B::set_age(A& a);
...
}
然而,要使编译器能够处理这条语句,它必须知道B的定义。否则,它无法知道B是一个类,而set_age是这个类的方法。这意味着应将B的定义放到A的定义前面。然而B类中提到了A对象,而这意味着A定义应当位于B定义之前。避开这种循环依赖的方法是使用前向声明(forward declaration)。为此,需要在B定义的前面插入下面的语句:
class A;// 前向声明
class B {...};
class A {...};
同样是前置声明,那能不能这样做呢:
class B;// 前向声明
class A {...};
class B {...};
答案是不能。原因在于,编译器在A类的定义中看到B类的一个方法被声明为A类的友元之前,应该先看到B类的声明和set_age( )方法的声明。
22. 说一下构造函数和析构函数
22.1 构造函数
-
构造函数 ,是一种特殊的方法。主要用来在创建对象时初始化对象(非static成员)。
-
C++中构造函数的命名必须和类名完全相同,并且没有返回值,void也不行;
- 构造函数不能直接调用,必须在创建对象的时候才会调用;
- 构造函数有回滚的效果,构造函数抛出异常时,构造的是一个不完整对象,会回滚,将此不完整对象的成员释放;
- 当一个类只定义了私有的构造函数,将无法通过new关键字来创建其对象;
- 当一个类没有定义任何构造函数,编译器在满足一定条件时会为其自动生成一个默认的无参的构造函数。
声明并定义构造函数
class A{
private:
int no;
public:
A(int num) {no = num};
}
使用构造函数
-
隐式地调用构造函数
A a(1); -
显式地调用构造函数
A a = A(1); -
和new一起使用
A *a = new A(1);这条语句在堆上创建一个对象,并将对象的首地址赋给指针变量a。在这种情况下对象没有名称,我们通过指针来管理该对象。
-
调用默认构造函数
默认构造函数是在未提供显式初始值时,用来创建对象的构造函数
A a; //可能的构造函数是不做任何操作 A::A() { }
22.2 析构函数
析构函数(destructor) 与构造函数相反,释放对象使用的资源,并销毁对象的非static数据成员。
当对象结束其生命周期,如对象所在的函数已调用完毕时,系统自动执行析构函数。在一个析构函数中,首先执行函数体,然后按初始化顺序的逆序销毁各个成员。成员销毁时发生什么完全依赖于成员类型,销毁类类型的成员需要执行该类成员自己的析构函数。销毁内置类型成员时什么也不做,因为内置类型没有析构函数。
特点
- 析构函数名称必须为 ~类名,并且无返回值,void也不行
- 每一个类只有唯一的一个析构函数
- 与构造函数不同,析构函数不能有参数,因此也就不能重载
- 如没必要,析构函数可以不执行任何操作
什么时候调用析构函数
无论何时,只要一个对象被销毁,就会自动调用其析构函数:
- 变量在离开其作用域时被销毁
- 当一个对象被销毁时,其成员被销毁
- 容器被销毁时,其元素被销毁
- 对于动态分配的对象,当对指向它的指针使用delete运算符时被销毁
- 对于临时对象,当创建它的完整表达式结束时被销毁
23.3 是否能声明为虚函数
构造函数不能声明为虚函数:因为在构造函数执行的时候,对象还没有完全创建,同时构造函数也承担了虚函数表初始化的工作,所以构造函数无法声明为虚函数。
析构函数尽量声明为虚函数:如果未声明析构函数为虚函数,那么在delete的时候只会调用当前对象的析构函数。如果继承或派生的类中也包含了析构函数,则不会被调用。如果声明为虚析构函数,则会依次调用对应的虚析构函数,避免内存泄漏。
23. 如何定义一个只能在堆上(栈上)生成对象的类?
23.1 只能在堆上
方法:将析构函数设置为私有
原因:C++ 是静态绑定语言,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数不可访问,则不能在栈上创建对象。
23.2 只能在栈上
方法:将 new 和 delete 重载为私有
原因:在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。
class A
{
private :
void * operator new ( size_t t){} // 注意函数的第一个参数和返回值都是固定的
void operator delete ( void * ptr){} // 重载了new就需要重载delete
public :
A(){}
~A(){}
};
原理
new和sizeof一样是操作符,是C++语言内置的,我们不能以任何方式直接改变它的行为。它要完成两个功能,第一个是分配足够的内存以便容纳所需类型的对象。第二个是它调用构造函数初始化内存中的对象。new 操作符调用一个函数来完成必需的内存分配,通过重写或重载这个函数可以改变它的行为。这个函数就是 operator new:
void * operator new(size_t size);
24. 说一下引用和指针的区别?
本质上的区别是,指针是一个新的变量,只是这个变量存储的是一个内存地址,我们通过访问这个地址来修改对应内存空间上的数据。而引用只是一个别名,还是变量本身。对引用进行的任何操作就是对变量本身进行操作,因此以达到修改变量的目的。
- 引用是变量的一个别名,内部实现是只读指针,不占用内存
- 引用只能在初始化时被赋值,其他时候值不能被改变,指针的值可以在任何时候被改变
- 引用不能为NULL,指针可以为NULL
- 引用变量内存单元保存的是被引用变量的地址
- 引用可以取地址操作,返回的是被引用变量本身所在的内存单元地址
- 引用使用在源代码级相当于普通的变量一样使用,做函数参数时,内部传递的实际是变量地址
- 引用只能是一级,而指针可以有多级指针。
- 指针传参的时候,还是值传递,试图修改传进来的指针的值是不可以的。只能修改指针变量中地址所在内存的数据。而引用传参的时候,传进来的就是变量本身,因此可以被修改。
25. C++中有了malloc / free , 为什么还需要 new / delete?
- malloc与free是C/C++语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
- new是一个操作符可以重载,malloc是一个库函数。
-
c++对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
- new出来的指针是直接带类型信息的。而malloc返回的都是void指针
- new分配内存按照数据类型进行分配,malloc分配内存按照指定的大小分配;
- malloc分配的内存不够的时候,可以用realloc扩容。扩容的原理?new没有这样操作。
26. 说一下堆和栈的区别?
- 栈区(stack):由编译器自动分配和释放 ,存放函数的参数值,局部变量的值等。速度较快。
- 堆区(heap):一般由程序员分配释放。速度较慢,容易产生内存碎片或内存泄漏。
- 全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化或初始化为0的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后由系统释放。
- 文字常量区:常量字符串就是放在这里的。程序结束后由系统释放。
- 程序代码区:存放函数体的二进制代码。
27. 在C++程序中调用被C编译器编译后的函数,为什么要加extern“C”
首先,被它修饰的目标是“extern”的。也就是告诉编译器,其声明的函数和变量可以 在本模块或其他模块中使用。通常,在模块的头文件中对本模块提供给其他模块引用的函数和全局变量以关键字extern声明。例如,当模块B欲引用该模块A中定义的全局变量和函数时,只需包含模块A的头文件即可。这样,模块B中调用模块A中的函数时,在编译阶段,模块B虽然找不到该函数,但是并不会报错;它会在连接阶段中从模块A编译生成的 目标代码中找到此函数。
其次,被它修饰的目标是“C”的,意思是其修饰的变量和函数是按照C语言方式编译和连接的。
C++语言支持函数重载,C语言不支持函数重载,函数被C++编译器编译后在库中的名字与C语言的不同,假设某个函数原型为:
void foo(int x, int y);
该函数被C编译器编译后在库中的名字为: _foo,而C++编译器则会产生像: _foo_int_int 之类的名字。
为了解决此类名字匹配的问题,C++提供了 C 链接交换指定符号 extern “C”,告诉编译器在编译foo这个函数名时按着C的规则去翻译相应的函数名而不是C++的。
#ifndef MODULE_A_H
#define MODULE_A_H
extern "C" int foo(int x, int y);
#endif
28. 头文件中的ifndef/define/endif 是干什么用的?
防止头文件被重复包含。和#pragma once一样。
29. 说一下C++对象内存模型
一个原则是:类对象成员变量在内存中的排列只需要符合 “较晚出现的成员变量在对象的内存中有较高的内存地址” 这一条件即可。
29.1 单一对象
-
如果类中没有虚函数,那么对象的内存中就只有对象的非静态成员变量。变量存储的顺序就是变量的声明次序,与private / public 无关。内存中没有具体函数是因为函数不隶属于具体的某一个类对象,而是属于类自己,并且被所有对象共享的。
-
如果类中有虚函数,那么对象内存的首地址处会额外增加一个虚函数指针,该指针指向的内存区域存储着该类中的所有虚函数。因此对象的体积会变大。虚函数指针之后就是对象的非静态成员变量。
- 如果类的析构函数是虚函数,那么虚函数表中会产生两个析构函数。因为 gcc 里虚析构函数在虚表里是一对;一个叫complete object destructor,另一个叫deleting destructor,区别在于前者只执行析构函数不执行delete(),后面的在析构之后执行deleting操作。应该是gcc想把non-detele的析构函数轮一遍后,然后用delete析构直接就清理掉整个内存。
虚函数表中的虚函数顺序就是类中声明的顺序。与 public/private 无关,与是否是析构函数也无关。
具体分析可参考博客:https://www.cnblogs.com/malecrab/p/5572730.html
29.2 单一继承
普通继承
- 如果所有类中都没有虚函数,那么类对象的内存分布就很简单。对于基类,非静态成员变量按序分布内存中;对于继承类,先是在内存中分配基类对象,然后紧接着分配自己的非静态成员变量。继承链中的当前类总是将自己的成员变量分配在对象内存的尾部。
- 如果基类中有虚函数(包括继承得到的),那么子类就会新开辟一块内存空间作为自己的虚函数表,先保存其继承下来的所有虚函数(虚析构函数除外),然后如果子类重写了虚函数,就将对应的函数地址替换为子类重写的虚函数的地址。 重写该虚函数时,可以不必写virtual关键字(只要函数同名同参同返回类型,就默认重写父类中虚函数)。如果子类新增了虚函数,那么直接添加到虚函数表尾部。
- 如果某个类中有虚析构函数,那么继承链中位于其后的所有类都会自定义自己的默认虚析构函数(啥事都不做的那种)。如果这个时候继承链后续的每个类中有的类自己定义了非虚的析构函数,那么其虚函数表中仍然有自己的默认虚析构函数地址。当然虚函数调用的肯定是用户自己定义的那个。
虚继承
虚继承会在对象的首地址新增一个虚函数指针。然后是自己新定义的变量,紧接着是一个完整的基类对象。
如果基类中有虚函数,那么虚继承会将其虚继承的基类整个完整保存下来,包括虚函数指针,但是虚函数表空间是自己新开辟的内存空间,因此虚函数指针值会发生变化。如果子类重写了基类的虚函数,那么也会更改虚函数表中对应的虚函数地址。
29.3 多继承
没有虚函数:那么对象的内存分布就是按照继承的顺序按序分布,这个过程可能会有字节对齐。对象自己定义的成员变量分布在对象内存结尾。
有虚函数:同上,只是在每一个有虚函数的对象中多了一个虚函数指针。如果继承的基类中有虚析构函数,那么继承类对象的该基类对象首部的虚函数指针指向的虚函数表中也会有该继承类的虚析构函数。如果这样的基类有多个,那么该继承类就有多个虚函数指针,也就有多个虚函数表,也就有可能有多个虚析构函数。
29.4 菱形继承
菱形继承是多继承的特殊情况,也就是上级基类是虚继承上上级的基类,这样当前继承类多继承的时候对象内存空间就只会存在一个上上级基类。大大节约了内存空间。
内存分布:
首先是多继承的上级基类的虚函数指针(如果有的话)及其非静态成员变量,上级基类是按照继承的顺序按序存放在内存中的。上级基类存储完毕后就是自己的成员变量;最后是上上级被虚继承的完整的上上级基类。
也就是说,菱形继承的顶端那个基类会被完整存储在继承类对象的结尾,而中间的多个基类会按照继承的顺序完整的存储在继承类的首部,中间的部分就是当前继承类的自定义非静态成员变量了。
30. 什么时候要用虚析构函数?
基类指针可以指向派生类的对象(多态性),如果使用delete删除该指针;就会调用该指针指向的派生类析构函数,而派生类的析构函数又自动调用基类的析构函数,这样整个派生类的对象完全被释放。如果析构函数不被声明成虚函数,则编译器实施静态绑定,在删除基类指针时,只会调用基类的析构函数而不调用派生类析构函数,这样就会造成派生类对象析构不完全,从而产生内存泄漏。所以,将析构函数声明为虚函数是十分必要的。
当然,如果指针指向的内容不是位于堆上面,那么我们就不必delete了,如果调用了delete,那么在析构函数中free函数会发生错误(free(): invalid pointer Aborted (core dumped))而退出。
总结
-
继承类指针指向继承类对象,delete 继承类指针:先调用继承类虚构函数,再调用基类虚构函数。
-
继承类指针指向基类对象,delete 继承类指针:
- 通过dynamic_cast,转化得到空指针),delete空指针不做任何操作。
- 通过static_cast或reinterpret_cast,转化得到值为原指针值的继承类指针,这个指针指向原来的基类对象,以及其后的一片区域(强制将其视为继承类对象)。也就是说我们得到两个不同的指针变量,他们的值相同(指向同一个内存首地址),但是指向的内存大小不同。如果我们对两个指针变量都作 delete,那么后面的delete操作会发生段错误(如果不存在虚析构函数则不会发生段错误,不知道为什么?)。
-
基类指针指向基类对象,delete 基类指针:调用基类虚构函数。
-
基类指针指向继承类对象,delete 基类指针:
- 如果基类析构函数是虚函数:先调用继承类析构函数,再调用基类的虚析构函数。
- 如果基类析构函数不是虚函数:直接调用基类析构函数。
-
如果是void* 指针指向类对象,那么delete该指针将不会调用析构函数。
任何class只要带有virtual函数都几乎确定应该也有一个virtual析构函数 ——《Efficient C++中文版 第三版》
31. 说一下显式调用和隐式调用
C/C++中的调用分为显式调用和隐式调用:
显示调用
显示调用是指在程序中能找到相应的调用代码,或者说是手动调用的
隐式调用
隐式调用是指程序中找不到相应的调用代码,或者说是编译器自动调用的,一般来说,强制转换是隐式调用了构造函数。
构造函数的调用
类的构造函数与析构函数一般就是隐式调用的。但是,析构函数与构造函数不同,构造函数只能隐式调用,而析构函数可以隐式调用,也可以被显式调用(如a.~Sample();)。
如果程序使用exit或abort非正常退出,则不会隐式调用析构函数,这样就造成对象申请的资源无法回收,从而导致操作系统的资源紧张而使应用程序无法运行。因此,在通常情况下,应使用return语句正常退出。
32. 说一下拷贝构造函数?
对于普通对象,它们的复制或赋值很简单,但是对于类对象,由于其内部结构复杂,存在各种各样的成员变量,因此需要专门的拷贝构造函数。
我们平时写的类如果没有定义拷贝构造函数,那么编译器会自动帮我们定义并实现一个拷贝构造函数,因此我们能够实现同一个类的对象之间的直接赋值。
调用场景
拷贝构造函数只在对象之间的赋值的时候被调用,具体的情况可能有如下:
-
以传值的方式传入函数
function(Object obj) {} -
在函数体内部构建的类对象被返回
Object function() { Object obj; ...... return obj; } -
对象需要通过另外一个对象进行初始化
Object a(); Object b = a;//或者Object b(a);
上述情况的一个共同点就是有对象之间的赋值操作。传值的方式传入对象需要创建一个临时对象,有赋值操作;类对象被返回后是直接的赋值操作;一个对象初始化另一个对象也是直接的赋值操作,而赋值操作就会调用拷贝构造函数。
怎样让返回对象的函数不调用拷贝构造函数
返回对象的函数调用拷贝构造函数是因为结果使用了“=”的对象间直接赋值,导致发生隐式转换。此时我们只需要在该拷贝构造函数声明前加上一个关键字 “explicit” 即可。explicit 修饰构造函数时,可以防止隐式转换和赋值初始化。但是有两点需要注意:
- 关键字 explicit 只对一个实参的构造函数有效,需要多个实参的构造函数不能用于执行隐式转换;
- 只能在类内声明构造函数时使用 explicit 关键字,在类外部定义时不应重复。
标准库中的案例
- 接受一个单参数的 const char* 的 string 构造函数不是 explicit 的;
- 接受一个容量参数的 vector 构造函数是 explicit 的。
33. 说一下C++中四种cast转换
C++中四种强制类型转换(cast)是:static_cast, dynamic_cast, const_cast, reinterpret_cast.
33.1 const_cast
只能用于const 修饰的变量,不能用于字面量。
const_cast<T>(expression);
...
char buf[] = "123456789";
//此时buf指向的数据是一个常量,不仅仅是只读属性
//const char *buf = "123456789" 此时有没有const都不可修改
//使用const_cast转换去只读属性,仍然不能进行修改
char *tmp = const_cast<char *>(buf);
tmp[0] = '9'; //会发生段错误
const_cast 运算符用于将一个 const / volatile 类型的变量的地址赋值给一个普通指针。不能改变变量类型。常用于函数重载的上下文中。
提供该运算符的原因是,有时候可能需要这样一个值,它在大多数时候是常量,而有时又是可以修改的。
33.2 static_cast
static_cast<T>(expression);
只要C语言中能够隐式转换的所有类型都可以使用static_cast进行转换。如果类型不能兼容,编译阶段会报错。用于各种隐式转换。static_cast 也能用于多态向上转化,如果向下转能成功但是不安全,结果未知。
适用场景:
- 用于类层次结构中基类和派生类之间指针或引用的转换:
进行上行转换(把派生类的指针或引用转换成基类表示)是安全的。
进行下行转换(把基类指针或引用转换成派生类表示)由于没有动态类型检查,所以是不安全的。
- 用于基本数据类型之间的转换,如把int转换为char,安全性问题由开发者来保证;
- 把空指针转换成目标类型的空指针;
- 把任何类型的表达式转为void类型;
33.3 dynamic_cast
dynamic_cast主要用于类层次间的上行转换和下行转换,还可以用于类之间的交叉转换。在类层次间进行上行转换时,dynamic_cast和static_cast的效果是一样的;在进行下行转换时,dynamic_cast具有类型检查的功能,比static_cast更安全。
class B {
public:
int m_iNum;
virtual void foo();
};
class D : public B {
public:
char* m_szName[100];
};
void func(B* pb) {
D* pd1 = static_cast(pb);
D* pd2 = dynamic_cast(pb);
}
在上面的代码段中,如果 pb 指向一个 D 类型的对象,pd1 和 pd2 是一样的,并且对这两个指针执行 D 类型的任何操作都是安全的;但是,如果 pb 指向的是一个 B 类型的对象,那么 pd1 将是一个指向该对象的指针,对它进行 D 类型的操作将是不安全的(如访问 m_szName),而 pd2 将是一个空指针。
另外要注意:B 要有虚函数,否则会编译出错;static_cast则没有这个限制。
这是由于运行时类型检查需要运行时类型信息,而这个信息存储在类的虚函数表中,只有定义了虚函数的类才有虚函数表,没有定义虚函数的类是没有虚函数表的。
33.4 reinterpret_cast
reinterpret_cast<T>(expression);
...
class A
{
public:
int i;
int j;
A(int n):i(n),j(n) { }
};
int main()
{
A a(100);
int &r = reinterpret_cast<int&>(a); // 强行让 r 引用 a
r = 200; // 把 a.i 变成了 200
cout << a.i << "," << a.j << endl; // 输出 200,100
int n = 300;
A *pa = reinterpret_cast<A*> (&n); // 强行让 pa 指向 n
pa->i = 400; // n 变成 400
pa->j = 500; // 此条语句不安全,很可能导致程序崩溃
cout << n << endl; // 输出 400
long long la = 0x12345678abcdLL;
pa = reinterpret_cast<A*>(la); // la太长,只取低32位0x5678abcd拷贝给pa
unsigned int u = reinterpret_cast<unsigned int>(pa); // pa逐个比特拷贝到u
cout << hex << u << endl; // 输出 5678abcd
typedef void (* PF1) (int);
typedef int (* PF2) (int,char *);
PF1 pf1;
PF2 pf2;
pf2 = reinterpret_cast<PF2>(pf1); // 两个不同类型的函数指针之间可以互相转换
}
我们可以使用statci_cast来替代隐式转换。但是如果碰到类型不兼容的情况,C语言可以使用强制类型转换来处理,那么C++该如何处理呢?C++中可以通过重解析类型转换reinterpret_cast来实现C语言的强制类型转换的效果。C++会将类型进行重新解析,转换成你需要的类型,不考虑转换后的后果。
interpret是解释的意思,reinterpret即为重新解释,此标识符的意思即为数据的二进制形式重新解释,但是不改变其值。是将一个指针转换成其他类型的指针,新类型的指针与旧指针可以毫不相关。通常用于某些非标准的指针数据类型转换,例如将void *转换为char *。
不到万不得已,不要使用这个转换符,高危操作
33.5 为什么不使用C的强制转换?
- 转换太过随意,可以在任意类型之间转换,但转化不够明确,不能进行错误检查,容易出错。
- 没有统一的关键字和标示符。对于大型系统,做代码排查时容易遗漏和忽略
通过静态类型转换和重解析类型转换完全可以替代C语言中的隐式转换和强制类型转换。
34. 说一下野指针是什么?
-
野指针是一个指针,这个指针指向的内存区域不确定、或者说是随机的。
-
野指针产生的原因是我们在定义指针变量时没有初始化,或者说我们的指针在free或delete后未赋值为NULL。
-
规避野指针的方法就是我们在初始化指针变量时记得初始化为NULL;指针变量在释放后也要记得将其赋值为NULL。
35. 说一下C++中的智能指针
智能指针主要用于管理在堆上分配的内存,它将普通的指针封装为一个栈对象。当栈对象的生存周期结束后,会在析构函数中释放掉申请的内存,从而防止内存泄漏。目前常用的智能指针有 unique_ptr、shared_ptr、weak_ptr,之前还有一个 auto_ptr,是在C++98中提出来的,后来在C++11中被废弃了。
auto_ptr
智能指针auto_ptr是C++98提供的解决方案, C++11已将其摒弃,并提供了另外两种解决方案。
为什么要舍弃 auto_ptr 智能指针呢?因为 auto_ptr 是一个利用建立所有权原理实现的智能指针。也就是说一个资源只能由一个该智能指针拥有。 如果此时将该智能指针利用拷贝构造函数或赋值运算符 赋值给另一个智能指针,那么原来的智能指针就不再拥有该资源,该资源将会被新的智能指针所拥有。而此时如果程序不小心调用了原来的智能指针,就会发生运行时错误。给系统留下了安全隐患。因此将其废除。
#include<memory>
#include<iostream>
using namespace std;
int main() {
auto_ptr<string> p1(new string("This is a string"));
auto_ptr<string> p2 = p1; //p1将所有权转让给p2,此时p1不再引用该字符串从而变成空指针。
cout << *p1 << endl; //报错,此时p1已经没有所指向的内存的所有权。
cout << *p2 << endl;
}
auto_ptr 也不能放在容器中。
unique_ptr
直观地看来,unique_ptr 形如其名,就是不能与其他 unique_ptr 类型的指针对象共享同一个对象的内存。所以我们无法通过拷贝构造函数或赋值运算符来复制一个 unique_ptr 类型的指针对象。如果实在要更改对象的指向,那么我们可以通过标准库的 std::move 函数来转移其 “所有权”。一旦“所有权”转移成功了,原来的 unique_ptr 指针就失去了对象内存的所有权。此时再使用已经“失势”的 unique_ptr,就会导致运行时的错误。
而从实现上讲,unique_ptr 则是一个删除了拷贝构造函数、保留了移动构造函数的指针封装类型。程序员仅可以使用右值对 unique_ptr 对象进行构造,而且一旦构造成功,右值对象中的指针即被“窃取”,因此该右值对象立刻失去了对指针的“所有权”。

shared_ptr
而 shared_ptr 同样形如其名,允许多个该智能指针共享地“拥有”同一块堆中对象的内存。与 unique_ptr 不同的是,由于在实现上采用了引用计数,只有在引用计数归零的时候,share_ptr 才会真正释放所占有的堆内存的空间。

当进行拷贝或赋值时,每个 shared_ptr 都会记录有多少个其它 shared_ptr 指向相同的对象。每个 shared_ptr 都有一个关联的引用计数器,当我们拷贝或赋值一个 shared_ptr时,该 shared_ptr 指向的对象的引用计数会递增;当我们给 shared_ptr 赋予一个新值或是 shared_ptr 被销毁,计数器会递减。
auto p = make_shared<int>(42); //p指向的对象只有一个引用者
auto q(p); //p和q指向相同对象,此对象有两个引用者
auto r = make_shared<int>(43); //r指向的int只有一个引用者
r = q; //给r赋值,令它指向另一个地址
//递增q指向的对象的引用计数
//递减r原来指向的对象的引用计数
//r原来指向的对象已没有引用者,会自动释放
weak_ptr
然而 shared_ptr 还不够安全,因为如果两个 shared_ptr 对象互相指向对方,那么将会导致循环引用,两个对象的引用计数都会加1。因此当 shared_ptr对象的生存周期已到的时候,其引用计数并不会减为0,也就不会回收内存,从而造成内存泄漏。
1 #include <memory>
2 #include <iostream>
3 using namespace std;
4
5 struct node{
6 int val;
7 node(int v): val(v) { }
8 shared_ptr<node> nxt;
10 };
11
12 int main() {
13 shared_ptr<node> sp1(new node(1));
14 shared_ptr<node> sp2(new node(2));
15
16 cout << sp1.use_count() << endl; //1
17 cout << sp2.use_count() << endl; //1
18 sp1->nxt = sp2;
19 sp2->nxt = sp1;
20
21 cout << sp1.use_count() << endl; //2
22 cout << sp2.use_count() << endl; //2
23 return 0;
24 }
而 weak_ptr 就是用来解决这个问题的,只要将指向的类型改为 weak_ptr 就可以避免这个问题。这是因为弱引用不修改对象的引用计数,只要把循环引用的一方使用弱引用,即可解除循环引用。
1 #include <memory>
2 #include <iostream>
3 using namespace std;
4
5 struct node{
6 int val;
7 node(int v): val(v) { }
8 //shared_ptr<node> nxt;
9 weak_ptr<node> nxt;
10 };
11
12 int main() {
13 shared_ptr<node> sp1(new node(1));
14 shared_ptr<node> sp2(new node(2));
15
16 cout << sp1.use_count() << endl; //1
17 cout << sp2.use_count() << endl; //1
18 sp1->nxt = sp2;
19 sp2->nxt = sp1;
20
21 cout << sp1.use_count() << endl; //1
22 cout << sp2.use_count() << endl; //1
23 return 0;
24 }
weak_ptr 可以指向 shared_ptr 指针指向的对象内存,却并不拥有该内存。而使用 weak_ptr 成员 lock,则可返回其指向内存的一个 shared_ptr 对象,且在所指对象内存已经无效时,返回指针空值(nullptr)。这在验证share_ptr 智能指针的有效性上会很有作用。
1 #include <memory>
2 #include <iostream>
3 using namespace std;
4 void Check(weak_ptr<int> & wp) {
5 shared_ptr<int> sp = wp.lock(); // 转换为shared_ptr<int>
6 if (sp != nullptr)
7 cout << "still " << *sp << endl;
8 else
9 cout << "pointer is invalid." << endl;
10 }
11 int main() {
12 shared_ptr<int> sp1(new int(22));
13 shared_ptr<int> sp2 = sp1;
14 weak_ptr<int> wp = sp1; // 指向shared_ptr<int>所指对象
15 cout << *sp1 << endl; // 22
16 cout << *sp2 << endl; // 22
17 Check(wp); // still 22
18 sp1.reset();
19 cout << *sp2 << endl; // 22
20 Check(wp); // still 22
21 sp2.reset();
22 Check(wp); // pointer is invalid
23 } //
使用实例:
1 #include <memory>
2 #include <iostream>
3 using namespace std;
4 int main() {
5 unique_ptr<int> up1(new int(11)); // 无法复制的unique_ptr
6 //unique_ptr<int> up2 = up1; // 想要赋值?不能通过编译
7 cout << *up1 << endl; // 11
8 unique_ptr<int> up3 = move(up1); // 现在up3是数据唯一的unique_ptr智能指针
9 cout << *up3 << endl; // 11
10 //cout << *up1 << endl; // 运行时错误
11 up3.reset(); // 显式释放内存
12 up1.reset(); // 不会导致运行时错误
13 //cout << *up3 << endl; // 运行时错误
14 shared_ptr<int> sp1(new int(22));
15 shared_ptr<int> sp2 = sp1;
16 cout << *sp1 << endl; // 22
17 cout << *sp2 << endl; // 22
18 sp1.reset();
19 cout << *sp2 << endl; // 22
20 }
选择哪种智能指针
应使用哪种智能指针呢?要看具体的程序。如果程序要使用多个指针指向同一个对象,应选择 shared_ptr。这样的情况包括:有一个指针数组,并使用一些辅助指针来标识特定的元素,如最大的元素和最小的元素;两个对象包含都指向第三个对象的指针;STL容器包含指针。
如果程序不需要多个指针指向同一个对象,则可使用 unique_ptr。如果函数使用 new 分配内存,并返回指向该内存的指针,将其返回类型声明为 unique_ptr 是不错的选择。这样,所有权将转让给接受返回值的unique_ptr,而该智能指针将负责调用 delete。
36. 说一下智能指针有没有内存泄露的情况
当两个对象相互使用一个shared_ptr成员变量指向对方,会造成循环引用,使引用计数失效,从而导致内存泄漏。
解决办法
为了解决循环引用导致的内存泄漏,引入了weak_ptr弱指针,weak_ptr的构造函数不会修改引用计数的值,从而不会对对象的内存进行管理,其类似一个普通指针,但不指向引用计数的共享内存,但是其可以检测到所管理的对象是否已经被释放,从而避免非法访问。
37. 说一下函数指针
函数指针是指向函数的指针变量。函数指针本身首先是一个指针变量,该指针变量指向一个具体的函数。这正如用指针变量可指向整型变量、字符型、数组一样,这里是指向函数。
C/C++ 在编译时,每一个函数都有一个入口地址,该入口地址就是函数指针所指向的地址。有了指向函数的指针变量后,可用该指针变量调用函数,就如同用指针变量可引用其他类型变量一样,在这些概念上是大体一致的。
用途
调用函数和做函数的参数,比如回调函数。
示例
char * fun(char * p) {…} // 函数fun
char * (*pf)(char * p); // 函数指针pf
pf = fun; // 函数指针pf指向函数fun
pf(p); // 通过函数指针pf调用函数fun
38. 说一下map和set有什么区别,分别又是怎么实现的?
map和set都是C++ 中STL中的关联容器,其底层实现都是红黑树(RB-Tree)。由于 map 和set所开放的各种操作接口,RB-tree 也都提供了,所以几乎所有的 map 和set的操作行为,都只是转调 RB-tree 的操作行为。
map和set区别在于:
- map中的元素是
key-value(关键字—值)对:关键字起到索引的作用,值则表示与索引相关联的数据;Set与之相对就是关键字的简单集合,set中每个元素只包含一个关键字。 - set的迭代器是
const的,不允许修改元素的值;map允许修改value,但不允许修改key。其原因在于map和set是根据关键字排序来保证其有序性的,如果允许修改key的话,那么首先需要删除该键,然后调节平衡,再插入修改后的键值,调节平衡,如此一来,严重破坏了map和set的结构,导致iterator失效,不知道应该指向改变前的位置,还是指向改变后的位置。所以STL中将set的迭代器设置成const,不允许修改迭代器的值;而map的迭代器则不允许修改key值,允许修改value值。 - map支持下标操作,set不支持下标操作。map可以用key做下标,map的下标运算符[ ]将key作为下标去执行查找,如果key不存在,则插入一个具有key和mapped_type类型默认值的元素至map中,因此下标运算符[ ]在map应用中需要慎用,const_map不能用,只希望确定某一个关键值是否存在而不希望插入元素时也不应该使用,mapped_type类型没有默认值也不应该使用。如果find能解决需要,尽可能用find。
39. 说一下STL的allocaotr
STL的分配器用于封装STL容器在内存管理上的底层细节。在C++中,其内存配置和释放如下:
new运算分两个阶段:
- 调用::operator new配置内存;
- 调用对象构造函数构造对象内容
delete运算分两个阶段:
- 调用对象析构函数;
- 调用::operator delete释放内存
为了精密分工,STL allocator将两个阶段操作区分开来:内存配置有alloc::allocate()负责,内存释放由alloc::deallocate()负责;对象构造由::construct()负责,对象析构由::destroy()负责。
同时为了提升内存管理的效率,减少申请小内存造成的内存碎片问题,SGI STL采用了两级配置器,当分配的空间大小超过128B时,会使用第一级空间配置器;当分配的空间大小小于128B时,将使用第二级空间配置器。第一级空间配置器直接使用malloc()、realloc()、free()函数进行内存空间的分配和释放,而第二级空间配置器采用了内存池技术,通过空闲链表来管理内存。
40. 说一下STL迭代器删除元素
这个主要考察的是迭代器失效的问题。
- 对于序列容器vector、deque来说,使用erase(itertor)后,后边的每个元素的迭代器都会失效,后边每个元素都会往前移动一个位置,但是erase会返回下一个有效的迭代器;
- 对于关联容器map、set来说,使用了erase(iterator)后,当前元素的迭代器失效,但是其结构是红黑树,删除当前元素的,不会影响到下一个元素的迭代器,所以在调用erase之前,记录下一个元素的迭代器即可。
- 对于list来说,它使用了不连续分配的内存,并且它的erase方法也会返回下一个有效的iterator,因此上面两种正确的方法都可以使用。
41. 说一下什么是右值引用,跟左值又有什么区别?
右值引用是C++11中引入的新特性 , 它实现了转移语义和精确传递。它的主要目的有两个方面:
- 消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率。
- 能够更简洁明确地定义泛型函数。
左值和右值的概念:
-
左值:能对表达式取地址、或具名对象/变量。一般指表达式结束后依然存在的持久对象。
-
右值:不能对表达式取地址,或匿名对象。一般指表达式结束就不再存在的临时对象。
右值引用和左值引用的区别:
- 左值可以寻址,而右值不可以。
- 左值可以被赋值,右值不可以被赋值,可以用来给左值赋值。
- 左值可变,右值不可变(仅对基础类型适用,用户自定义类型右值引用可以通过成员函数改变)。
42. 说一下一个C++源文件从文本到可执行文件经历的过程?
对于C++源文件,从文本到可执行文件一般需要四个过程:
- 预处理阶段:处理以 # 开头的预处理命令(源代码文件中文件包含关系、预编译语句进行分析和替换,生成预编译文件)
- 编译阶段:将经过预处理后的预编译文件转换成特定汇编代码,生成汇编文件
- 汇编阶段:将编译阶段生成的汇编文件转化成机器码,生成可重定位目标文件
- 链接阶段:将多个目标文件及所需要的库连接成最终的可执行目标文件
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
- 符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。
- 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
动态链接
静态库有以下两个问题:
- 当静态库更新时那么整个程序都要重新进行链接;
- 对于 printf 这种标准函数库,如果每个程序都要有代码,这会极大浪费资源。
共享库是为了解决静态库的这两个问题而设计的,在 Linux 系统中通常用 .so 后缀来表示,Windows 系统上它们被称为 DLL。它具有以下特点:
- 在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中;
- 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。
43. 说一下C++11有哪些新特性?
43.1 新类型
C++11新增了类型long long和unsigned long long,以支持64位(或更宽)的整型;新增了类型char16_t和char32_t,以支持16位和32位的字符表示;还新增了“原始”字符串。
43.2 大括号初始化
C++11扩大了用大括号括起的列表(初始化列表)的适用范围,使其可用于所有内置类型和用户定义的类型(即类对象)。使用初始化列表时,可添加等号(=),也可不添加:
int x = {5};
double y {1.0};
short array[3] {1, 2, 3};
int *array = new int[4] {1, 2, 3, 4};
并且大括号初始化还可以防止将值存储在比它”窄“的变量中,例如:
char c = {129};//int to char, out of range, compile-time error
但是只要值在变量表示范围内,不管值的类型是啥,都可以转化:
char c = {1};//int to char, in range, allowed
43.3 auto
编译器可以根据初始值自动推导出类型。但是不能用于函数传参以及数组类型的推导
auto num = 12; //num is type int
auto ptr = # //ptr is type int *
double function(int, double);
auto ptr2 = function; //ptr2 is type double () (int, double)
43.4 decltype
关键字decltype将变量的类型声明为表达式指定的类型。下面的语句的含义是,让y的类型与x相同,其中x是一个表达式:
decltype(x) y;
//例如:
int n;
double e;
decltype(n * e) q; //q is the type as n*e(double)
decltype(&n) q2; //q2 is the type as &n(int *)
decltype在定义模板时很有用,因为只有在模板被实例化时才可以确定类型。
43.5 返回类型后置
在定义模板函数时,可以使用decltype来指定函数的返回类型,例如:
template<typename T, typename U>
auto eff(T t, U u) -> decltype(T*U){
//...
}
这里解决的问题是,在编译器遇到eff的参数列表前,T和U还不在作用域内,因此必须在参数列表后使用decltype。这种新语法使得能够这样做。
43.6 using a=b
对于冗长或复杂的标识符,如果能够创建其别名将很方便。之前,C++为此提供了 typedef,C++11新提供了using:
typedef std::vector<std::string>::iterator itType;
using itType = std::vector<std::string>::iterator;
差别在于,新语法也可用于模板部分具体化,但typedef不能:
template<typename T>
using arr12 = std::array<T, 12>
//原来类型
std::array<double, 12> a1;
std::array<int, 12> a2;
//就可以替换成
arr12<double> a1;
arr12<int> a2;
43.7 nullptr
空指针是不指向有效数据的指针。之前,C++在源代码中使用NULL(0)表示这种指针,但内部表示可能不同。这带来了一些问题,因为这使得0即可表示指针常量,又可表示整型常量。
而C++11新增了关键字nullptr,用于表示空指针;它是指针类型,不能转换为整型类型。为向后兼容,C++11仍允许使用0来表示空指针,因此表达式 nullptr == 0为true,但使用nullptr而不是0提供了更高的类型安全。例如,可将0传递给接受int参数的函数,但如果您试图将nullptr传递给这样的函数,编译器将此视为错误。因此,出于清晰和安全考虑,请使用nullptr—如果您的编译器支持它。
43.8 智能指针
如果在程序中使用new从堆(自由存储区)分配内存,等到不再需要时,应使用 delete将其释放。C++引入了智能指针auto_ptr,以帮助自动完成这个过程。随后的编程体验(尤其是使用STL时)表明,需要有更精致的机制。基于程序员的编程体验和BOOST 库提供的解决方案,C++11摒弃了auto_ptr,并新增了三种智能指针:unique_ptr、 shared_ptr和weak_ptr
43.9 类内成员初始化
C++11实现了可以直接在类定义中初始化成员变量:
class Test{
int number = 10;
//......
};
通过使用类内初始化,可避免在构造函数中编写重复的代码,从而降低了程序员的工作量、厌倦情绪和出错的机会。
43.10 基于范围的for循环
基于范围的for循环可简化编写循环的工作。这种循环对数组或容器中的每个元素执行指定的操作:
int array[5] = {1,2,3,4,5};
for (int num : array) {
//do something with num
}
其中,num将依次为array中每个元素的值。num的类型应与数组元素的类型匹配。一种更容易、更安全的方式是,使用auto来声明num,这样编译器将根据array声明中的信息来推断num的类型:
int array[5] = {1,2,3,4,5};
for (auto num : array) {
//do something with num
}
如果要在循环中修改数组或容器的每个元素,可使用引用类型。
43.11 新的STL容器
C++11新增了STL容器forward_list、unordered_map、unordered_multimap、 unordered_set和unordered_multiset。容器forward_list是一种单向链表,只能沿一个方向遍历;与双向链接的list容器相比,它更简单,在占用存储空间方面更经济。其他四种容器都是使用哈希表实现的。
C++11还新增了模板array。要实例化这种模板,可指定元素类型和固定的元素数:
std::array<int, 100> arr; //array of 100 ints
但是由于长度固定,array不能使用任何修改容器大小的方法,如push_back( )。
43.12 新的STL方法
C++11新增了STL方法cbegin( )和cend( )。与begin( )和end( )一样,这些新方法也返回 一个迭代器,指向容器的第一个元素和最后一个元素的后面,因此可用于指定包含全部元素的区间。另外,这些新方法将元素视为const。与此类似,crbegin( )和crend( )是rbegin( ) 和rend( )的const版本。
43.13 尖括号
为避免与运算符»混淆,之前的C++要求在声明嵌套模板时使用空格将尖括号分开,而C++11不再这样要求:
std::vector<std::vector<int> > matrix; //always ok
std::vector<std::vector<int>> matrix1; //not ok
std::vector<std::vector<int>> matrix2; // ok in C++11
43.14 右值引用
C++11新增了右值引用,这是使用&&表示的。右值引用可关联到右值,即可出现在赋值表达式右边,但不能对其应用地址运算符的值。右值包括字面常量、诸如x + y等表达式以及返回值的函数(条件是该函数返回的不是引用):
int x = 10;
int y = 13;
int &&r1 = 13;
int &&r2 = x + y;
注意:r2关联到的是当时计算x + y得到的结果。也就是说,r2关联到的是23,即使以后修改了x或y,也不会影响到r2。
将右值关联到右值引用导致该右值被存储到特定的位置,且可以获取该位置的地址。也就是说,虽然不能将运算符&用于13,但可将其用于r1。通过将数据与特定的地址关联,使得可以通过右值引用来访问该数据。
移动语义
Lambda函数
可变参数模板
可变参数模板(variadic template)能够创建可接受可变数量的参数这样的模板函数和模板类。
并行编程
44. C++中main函数执行完后还执行其他语句吗
可以执行。很多时候,我们需要在程序退出的时候做一些诸如释放资源的操作,但程序退出的方式有很多种,例如main()函数运行结束,在程序的某个地方用exit()结束程序,用户通过 Ctrl+C等操作发信号来终止程序,等等,因此需要有一种与程序退出方式无关的方法来进行程序退出时的必要处理。方法就是用atexit()函数来注册程序正常终止时要被调用的函数。
atexit()函数的参数是一个函数指针,函数指针指向一个没有参数也没有返回值的函数。atexit()的函数原型是:
int atexit (void (*)(void));
在一个程序中最多可以用atexit()注册32个处理函数,这些处理函数的调用顺序与其注册的顺序相反,即最先注册的最后调用,最后注册的最先调用。
45. 说一下复杂指针的声明
对于复杂指针的声明,使用右左法则:首先从未定义的标识符开始阅读,然后往右看,再往左看。每当遇到圆括号时,就应该掉转阅读方向。一旦解析完圆括号里面所有的东西,就跳出圆括号。重复这个过程,直到整个声明解析完毕。
-
int (*func)(int *p);首先找到那个未定义的标识符,就是 func ,它的外面有一对圆括号,而且左边是一个 * 号,这说明 func 是一个指针;然后跳出这个圆括号,先看右边,也是一个圆括号,这说明 ( * func) 是一个函数,而 func 是一个指向这类函数的指针,就是一个函数指针,这类函数具有 int * 类型的形参,返回值类型是 int。
-
int (*func)(int *p, int (*f)(int*));func 被一对括号包含,且左边有一个 * 号,说明 func 是一个指针,跳出括号,右边也有个括号,那么func 是一个指向函数的指针,这类函数具有 int * 和 int ( * )(int * ) 这样的形参,返回值为 int 类型。再来看一看 func 的形参 int ( * f)(int * ) ,类似前面的解释,f 也是一个函数指针,指向的函数具有 int* 类型的形参,返回值为 int。
-
int (*func[5])(int *p);func 右边是一个 [] 运算符,说明 func 是一个具有5个元素的数组;func 的左边有一个 * , 说明 func 的元素是指针。要注意这里的 * 不是修饰 func 的,而是修饰 func[5] 的,原因是 [] 运算符优先级比 * 高,func 先跟 [] 结合,因此 * 修饰的是 func[5]。跳出这个括号,看右边, 也是一对圆括号,说明 func 数组的元素是函数类型的指针,它所指向的函数具有 int* 类型的形参,返回值类型为 int。
-
*int (*(*func)[5])(int *p);func 被一个圆括号包含,左边又有一个 ,那么func是一个指针;跳出括号,右边是 一个 [] 运算符号,说明 func 是一个指向数组的指针。现在往左看,左边有一个 * 号,说明这个数组的元素是指针;再跳出括号,右边又有一个括号,说明这个数组的元素是指向函数的指针。总结一下,就是:func 是一个指向数组的指针,这个数组的元素是函数指针,这些指针指向具有 int 类型的形参,返回值为 int 类型的函数。
-
*int (*(*func)(int *p))[5];func 是一个函数指针,这类函数具有 int* 类型的形参,返回值是指向数组的指针,所指向的数组的元素是具有5个 int 元素的数组
46. 说一下指针数组与数组指针的区别
-
指针数组是一个数组,并且数组中的每一个元素是指针。
int *a[10]; //数组a里面存放了10个int *型变量 -
数组指针是一个指针,并且指向了一个数组。
int *b = new int[10]; //指针b指向含有10个整型数据的一维数组
47. 有哪几种情况只能用intialization list, 而不能用assignment
- 对于 const 和 reference 类型成员变量,它们只能够被初始化而不能做赋值操作,因此只能用初始化列表
- 类的构造函数需要调用其基类的构造函数的时候(在函数体内调用父类的构造函数是不合法的,只有采取初始化列表调用子类构造函数的方式)
- 注意:static 成员变量不能在类内部被初始化,使用初始化列表也不行
48. C++中的空类默认会产生哪些类成员函数
虽然 Empty 类定义中没有任何成员,但为了进行一些默认的操作,编译器会加入以下一些成员函数,这些成员函数使得类的对象拥有一些通用的功能:
- 默认构造函数和拷贝构造函数。它们被用于类的对象的构造过程。
- 析构函数。它被用于类的对象的析构过程。
- 赋值函数。它被用于同类的对象间的赋值过程。
- 取址运算。当对类的对象进行取地址(&)时,此函数被调用。 完整的 Empty 类定义如下。
class Empty {
public:
Empty(); //缺省构造函数
Empty(const Empty&); //拷贝构造函数
~Empty(); //析构函数
Empty& operator=(const Empty&); //赋值运算符
Empty* operator&(); //取址运算符
const Empty* operator&() const; //取址运算符 const
};
49. 说一下C++中函数调用的解析过程
49.1 分类
C++中的函数可以大致分为三类:
- 普通函数(nostatic):分为类成员函数和类外普通函数。
- 静态函数(static):分为类静态成员函数和类外静态函数。
- 虚函数(virtual):只能是类类非静态成员函数。
49.2 非静态成员函数
C++类中的非静态成员函数本质上就是一个类外的普通函数,只不过这个类外的普通函数的第一个参数是默认参数this指针。通过这个默认的this指针函数才可以操作对应的非静态类成员变量,而如果类成员函数被修饰为const,那么该函数就不能修改类成员变量(只能读不能写)。因为其本质是this指针变量被const修饰了,而我们需要通过this指针来操作类成员变量,const就将这一方式禁止了(所以const修饰函数的本质也是修饰变量)。
正是因为非静态成员函数有一个隐藏this指针参数,所以只要该函数内部没有读写成员变量,即使传入的this指针是NULL,函数也可以成功调用。
将一个成员函数改写成一个外部函数的关键在于两点:
- 一是给函数提供一个可以直接读写成员数据的通道,通过给函数提供一个额外的指针参数来解决;
- 二是解决好有可能带来的名字冲突,通过一定的规则将名字转换,使之独一无二。
49.3 静态成员函数
静态成员函数的一些特性:
- 不能够直接存取其类中的非静态成员(nostatic members),包括不能调用非静态成员函数(Nonstatic Member Functions)。因为没有this指针。
- 不能够声明为 const、voliatile 或 virtual。
- 它不需经由对象调用,当然,通过对象调用也被允许。
除了缺乏一个this指针他与非静态成员函数没有太大的差别。在这里通过对象调用和通过指针或引用调用,将被转化为同样的调用代码。
49.4 虚函数
如果function()是一个虚拟函数,那么用指针或引用进行的调用将发生一点特别的转换——一个中间层被引入进来。例如:
// p->function()
//将转化为
(*p->vptr[1])(p);
- 其中vptr为指向虚函数表的指针,它由编译器产生(一般位于对象首地址)。vptr也要进行名字处理,因为一个继承体系可能有多个vptr。
- 1是虚函数在虚函数表中的索引,通过它关联到虚函数function().
49.5 成员函数调用过程
假如我们调用p->mem()或者obj.mem(),那么函数调用将依次执行以下4个步骤:
- 首先确定p或者obj的静态类型,必须是类类型
- 在p或者obj静态类型对应的类中查找mem。如果找不到,则依次在直接基类中不断查找直至到达继承链的顶端,如果找遍了该类及其基类仍然找不到,则编译器会报错
- 一旦找到了mem,就进行常规的类型检查已确认对于当前找到的mem,本次调用是否合法
- 假设调用合法,则编译器会根据调用的是否是虚函数而产生不同的代码:
- 如果是虚函数且我们是通过指针或引用调用进行的调用,则编译器产生的代码将在运行时确定到底运行该虚函数的哪个版本,依据是对象的动态类型
- 如果mem不是虚函数或者我们是通过对象进行的调用,则编译器将产生一个常规函数调用,第一个参数是默认参数this指针。
50. 说一下函数模板与类模板
使用泛型编程(模板)可以极大地增加代码的重用性
函数模板
函数模板是一种抽象的函数定义,它代表一类同构函数。通过用户提供的具体参数, C++编译器在编译时刻能够将函数模板实例化,根据同一个模板创建出不同的具体函数。这些函数之间的不同之处主要在于函数内部一些数据类型的不同,而由模板创建的函数的使用方法与一般函数的使用方法相同。函数模板的定义格式如下:
template<TYPE_LIST,ARG_LIST>
Function_Definition
例如:
template <class T> //class也可用typename替换
T max(T a, T b) //参数和返回值都是T类型
{
return a > b ? a: b;
}
类模板
C++提供的类模板是一种更高层次的抽象的类定义,用于使用相同代码创建不同的类。类模板的定义与函数模板的定义类似,只是把函数模板中的函数定义部分换作类声明,并对类的成员函数进行定义即可。在类声明中可以使用出现在TYPE_LIST中的各个类型标识以及出现在ARG_LIST中的各变量
template<模板参数表>
class<类模板名>
{<类模板定义体>},
区别
- 函数模板是一种抽象的函数定义,它代表一类同构函数。类模板是一种更高层次的抽象的类定义。
- 函数模板的实例化是由编译程序在处理函数调用时自动完成的,而类模板的实例化必须由程序员在程序中显式地指定。
51. 说一下C++标准模板库&C++标准程序库
标准模板库STL(Standard Template Library),是一个具有工业强度的、高效的 C++程序库。它被容纳于C++标准程序库(C++ Standard Library)中。
STL是最新的C++标准函数库中的一个子集,它占据了整个库的大约80%的分量。而作为在实现 STL 过程中扮演关键角色的模板,则充斥了几乎整个 C++标准函数库。
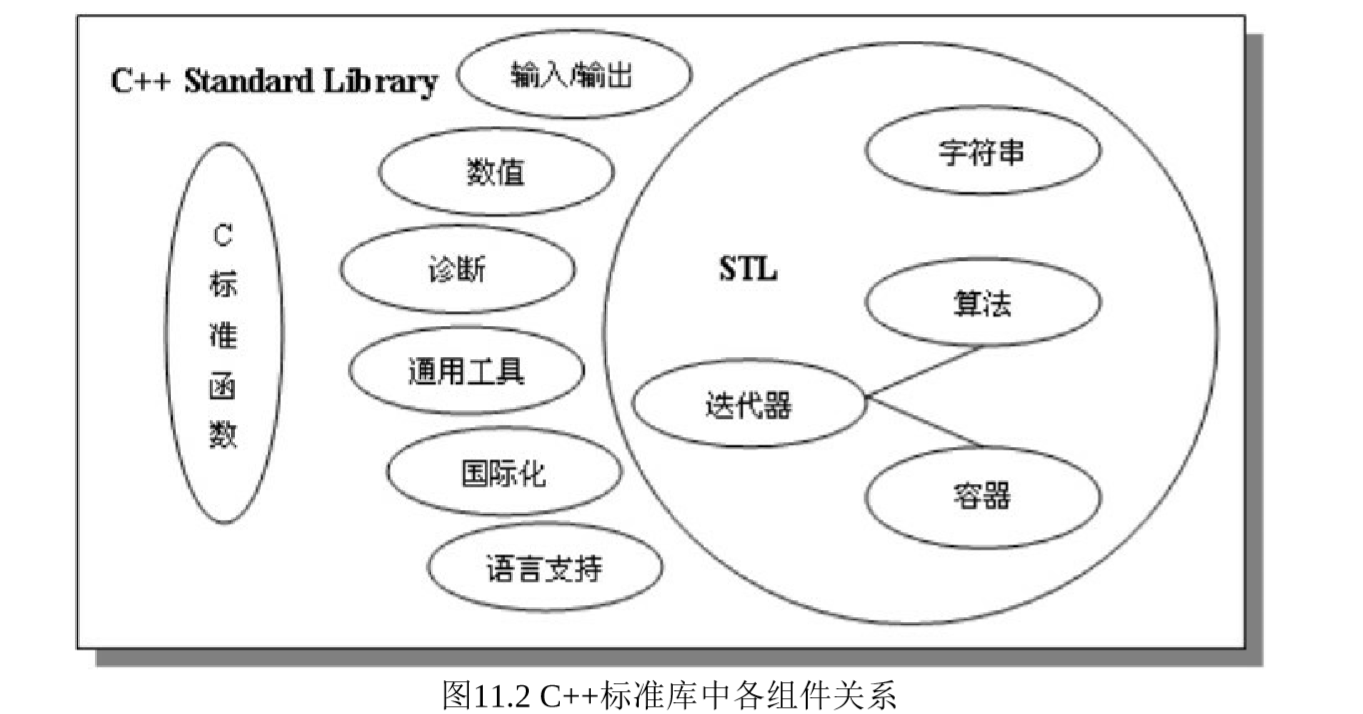
C++标准函数库包含了如下几个组件:
- C标准函数库,尽管有了一些变化,但是基本保持了与原有 C 语言程序库的良好兼容。C++标准库中存在两套C的函数库,一套是带有.h扩展名的(比如
<stdio.h>), 而另一套则没有(比如<cstdio>)。它们确实没有太大的不同。 - 输入/输出(input/output)部分,就是经过模板化了的原有标准库中的 iostream 部分。它提供了对C++程序输入/输出的基本支持。在功能上保持了与原有 iostream 的兼容,增加了异常处理的机制,并支持国际化(internationalization)。
- 数值(numerics)部分,包含了一些数学运算功能,提供了复数运算的支持。
- 诊断(diagnostics)部分,提供了用于程序诊断和报错的功能,包含了异常处理 (exception handling)、断言(assertions)、错误代码(error number codes)三种方式。
- 通用工具(general utilities)部分,这部分内容为 C++ 标准库的其他部分提供支持。当然,你也可以在自己的程序中调用相应功能,比如动态内存管理工具、日期/时间处理工具。记住,这里的内容也已经被泛化了(采用了模板机制)。
- 国际化(internationalization)部分,作为OOP特性之一的封装机制在这里扮演着消除文化和地域差异的角色,采用 locale 和 facet 可以为程序提供众多国际化支持,包括对各种字符集的支持、日期和时间的表示、数值和货币的处理等等。
- 语言支持(language support)部分,包含了一些标准类型的定义以及其他特性的定义。这些内容被用于标准库的其他地方或是具体的应用程序中。
- 字符串(string)部分,用来代表和处理文本。它提供了足够丰富的功能。
- 容器(containers)部分,是STL的一个重要组成部分,涵盖了许多数据结构, 如链表、vector(类似于大小可动态增加的数组)、queue(队列)、stack(堆栈)…… string也可以看作一个容器,适用于容器的方法同样也适用于string。
- 迭代器(iterators)部分,是 STL 的一个重要组成部分。它使得容器和算法能够完美地结合。事实上,每个容器都有自己的迭代器,只有容器自己才知道如何访问自己的元素。它有点像指针,算法通过迭代器来定位和操控容器中的元素。
- 算法(algorithms)部分,是STL的一个重要组成部分,包含了大约70个通用算法,用于操控各种容器,同时也可以操控内建数组。
52. 说一下函数对象
简单地说,函数对象就是一个重载了“()”运算符的类的对象,它可以像一个函数一样使用。例如:
#include <iostream>
using namespace std;
class MyAdd {
public:
int operator () (int a, int b) { return a+b; }
};
class MyMinus {
public:
int operator () (int a, int b) { return a-b; }
};
int main() {
int a = 1;
int b = 2;
MyAdd addObj;
MyMinus minusObj;
cout << "a+b=" << addObj(a, b) << endl; //输出 a+b=3
cout << "a-b=" << minusObj(a, b) << endl; //输出a-b=-1
return 0;
}
STL中提供了一元和二元函数的两种函数对象。下面列出了各个函数对象。
一元函数对象
- negate,相反数
二元函数对象
- plus,加(+)法
- minus,减(-)法
- multiplies,乘(*)法
- divides,除(/)法
- modulus,求余(%)
- equal_to,等于(==)
- not_equal_to,不等于(!=)
- greater,大于(>)
- greater_equal,大于或等于(>=)
- less,小于(<)
- less_equal,小于或等于(<=)
- logical_and,逻辑与(&&)
-
logical_or,逻辑或( ) - logical_not,逻辑非(!)
以上这些函数对象都是基于模板实现的,可以这样使用它们:
minus <int> int_ minus;
cout << int_minus(3, 4) << endl; //输出-1
53. 说一下C++中const变量的内存分布
进程空间大概分为栈、堆、BSS、rwData、roData、text这几个区域。
对于栈上的const变量,变量全部存储在栈上,因此可以通过其它指针对其进行更改。如果const修饰的变量是指针,那么需要注意区分指针常量和常量指针,如果指针指向的是字面量,那么字面量一定是位于只读数据区,我们无法更改该区域的内容;如果变量不是指针,表示我们不可以直接对该变量进行修改,但是可以通过其它指针对其进行更改,因为该变量存储在栈上。
对于全局变量和静态变量,const修饰的非指针变量存储在只读数据区,因此不能直接或通过其它指针对其进行修改。const修饰的指针变量根据const和 * 的位置可以分为常量指针和指针常量,二者位于的内存区域也不相同。常量指针是const位于 * 和指针变量之前,修饰的是指针指向的内存区域,表示该内存区域不可通过该指针进行更改,但是只要该指针指向的内存是位于可读写区域,我们就可以通过其它指针来对该区域的数据进行修改。指针常量则是const位于 * 和指针变量之间,修饰的是指针变量本身,表示该指针变量不可更改,因此该变量存放于只读数据区,但该指针常量指向的内存区域只要不是只读数据区,就可以通过其它指针进行修改。
54. 如何防止和避免指针越界和指针泄漏?
规则1:使用malloc申请的内存时,必须要立即检查相对应的指针是否为NULL。
规则2:初始化数组和动态内存。
规则3:避免数组或指针下标越界。
规则4:动态内存的申请和释放必须相配对,防止内存泄漏。
规则5:free释放某块内存之后,要立即将指针设置为NULL,防止产生野指针。
55. char 与 unsigned char的本质区别
首先在内存中,char与unsigned char没有什么不同,都是一个字节,唯一的区别是,char的最高位为符号位,因此char能表示-127~127,unsigned char没有符号位,因此能表示0~255,这个好理解,8个bit,最多256种情况,因此无论如何都能表示256个数字。
二者的最大区别是:但是我们却发现在表示byte时,都用unsigned char,这是为什么呢?首先我们通常意义上理解,byte没有什么符号位之说,更重要的是如果将byte的值赋给int,long等数据类型时,系统会做一些额外的工作。如果是char,那么系统认为最高位是符号位,而int可能是16或者32位,那么会对最高位进行扩展(注意,赋给unsigned int也会扩展)而如果是unsigned char,那么不会扩展。最高位若为0时,二者没有区别,若为1时,则有区别了。同理可以推导到其它的类型,比如short, unsigned short,等等。
符号扩展:将一个较小的有符号类型扩展为较大的类型,其高地址部分一律填充为原来类型的最高位(符号位)。
零扩展:将一个较小的无符号类型扩展为较大的类型,其高地址部分一律填充0。
56. C++中vector如何缩容?
C++ 中 vector 本身只提供了扩容机制,但没有提供缩容。但我们可以利用swap函数来进行实现。原理是vector在析构时会自动释放持有的内存,那么我们就可以利用拷贝构造函数或赋值运算符将原来的vector变量赋值给一个临时的vector变量(可以用大括号括起来),然后调用swap交换二者,这样当退出大括号时,原来的大容量内存就会因为临时变量的析构而被回收。而我们原来的vector变量也换到了一个更小的容量,从而间接实现了缩容。
比如:
{
vector<int> tmp(arr);
tmp.swap(arr);
}
//到达这里时tmp已经调用了其析构函数,将内存释放了
或者将其封装成一个函数:
void clear_vector(vector<int> &arr) {
vector<int> tmp = arr;
tmp.swap(arr);
}
多维vector也同样适用。
57. 下面几个不同函数有什么区别?
#include <iostream>
using namespace std;
void show(int *a) {
cout << "1" << endl;
}
void show(const int* a) {
cout << "2" << endl;
}
void show(int* const a) {
cout << "3" << endl;
}
int main() {
int a = 1;
int* p1 = &a;
const int* p2 = &a;
int* const p3 = &a;
show(p1);
show(p2);
show(p3);
return 0;
}
其中 void show(int *a) 和 void show(int * const a) 在编译器看来都是一样的,即 void show(int *a)。
算法与数据结构
1. 说一下红黑树和AVL树的定义,特点,以及二者区别
定义
-
平衡二叉树又称为AVL树,是一种特殊的二叉排序树。其左右子树都是平衡二叉树,且左右子树高度之差的绝对值不超过1。将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF,那么平衡二叉树上的所有结点的平衡因子只可能是-1、0和1。只要二叉树上有一个结点的平衡因子的绝对值大于1,则该二叉树就是不平衡的。
-
红黑树是一种二叉查找树,但需要在每个结点增加一个存储位表示结点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树,相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,通常使用红黑树。
性质
红黑树:
- 每个节点非红即黑
- 根节点是黑的;
- 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
区别
-
AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;
-
红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
2. 说一下哈夫曼编码
哈夫曼编码是哈夫曼树的一种应用,广泛用于数据文件压缩。哈夫曼编码算法用字符在文件中出现的频率来建立使用0,1表示各字符的最优表示方式,其具体算法如下:
- 哈夫曼算法以自底向上的方式构造表示最优前缀码的二叉树T。
- 算法以C个叶结点开始,执行C-1次的“合并”运算后产生最终所要求的树T。
- 假设编码字符集中一字符c的频率是f(c)。以f为键值的优先队列Q用贪心选择策略有效地确定算法当前要合并的2棵具有最小频率的树。一旦2棵具有最小频率的树合并后,产生一棵新的树,其频率为合并的2棵树的频率之和,并将新树插入优先队列Q。经过n-1次的合并后,优先队列中只剩下一棵树,即所要求的树T。
3. 说一下map底层为什么用红黑树实现
红黑树是在AVL树的基础上提出来的。平衡二叉树又称为AVL树,是一种特殊的二叉排序树。其左右子树都是平衡二叉树,且左右子树高度之差的绝对值不超过1。
AVL树中以所有结点为根的树的左右子树高度之差的绝对值不超过1。因此AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;
而红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。所以红黑树在查找,插入删除的性能都是O(logn),且性能稳定,所以STL里面很多结构包括map底层实现都是使用的红黑树。
4. 说一下B+树
B+是一种多路搜索树,主要为磁盘或其他直接存取辅助设备而设计的一种平衡查找树,在B+树中,每个节点都可以有多个孩子,并且按照关键字大小有序排列。所有记录节点都是按照键值的大小顺序存放在同一层的叶节点中。相比B树,其具有以下几个特点:
- 每个节点上的指针上限为2d而不是2d+1(d为节点的出度)
- 内节点不存储data,只存储key
- 叶子节点不存储指针
5. 说一下map和unordered_map优点和缺点
对于map,其底层是基于红黑树实现的,优点如下:
- 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
- map的查找、删除、增加等一系列操作时间复杂度稳定为$O(logn)$
缺点如下:
- 查找、删除、增加等操作平均时间复杂度较慢,与n相关
对于unordered_map来说,其底层是一个哈希表,优点如下:
- 查找、删除、添加的速度快,时间复杂度为常数级O(1)
缺点如下:
- 因为unordered_map内部基于哈希表,以(key,value)对的形式存储,因此空间占用率高
- Unordered_map的查找、删除、添加的时间复杂度不稳定,平均为O(1),取决于哈希函数。极端情况下可能为O(n)
6. 说一下Top(K)问题
-
直接全部排序(只适用于内存够的情况)
当数据量较小的情况下,内存中可以容纳所有数据。则最简单也是最容易想到的方法是将数据全部排序,然后取排序后的数据中的前K个。
这种方法对数据量比较敏感,当数据量较大的情况下,内存不能完全容纳全部数据,这种方法便不适应了。即使内存能够满足要求,该方法将全部数据都排序了,而题目只要求找出top K个数据,所以该方法并不十分高效,不建议使用。
-
快速排序的变形 (只使用于内存够的情况)
这是一个基于快速排序的变形,因为第一种方法中说到将所有元素都排序并不十分高效,只需要找出前K个最大的就行。
这种方法类似于快速排序,首先选择一个划分元,将比这个划分元大的元素放到它的前面,比划分元小的元素放到它的后面,此时完成了一趟排序。如果此时这个划分元的序号index刚好等于K,那么这个划分元以及它左边的数,刚好就是前K个最大的元素;如果index > K,那么前K大的数据在index的左边,那么就继续递归的从index-1个数中进行一趟排序;如果index < K,那么再从划分元的右边继续进行排序,直到找到序号index刚好等于K为止。再将前K个数进行排序后,返回Top K个元素。这种方法就避免了对除了Top K个元素以外的数据进行排序所带来的不必要的开销。
-
最小堆法
这是一种局部淘汰法。先读取前K个数,建立一个最小堆。然后将剩余的所有数字依次与最小堆的堆顶进行比较,如果小于或等于堆顶数据,则继续比较下一个;否则,将其与堆顶元素交换,重新调整为最小堆。当遍历完全部数据后,最小堆中的数据即为最大的K个数。
-
分治法
将全部数据分成N份,前提是每份的数据都可以读到内存中进行处理,找到每份数据中最大的K个数。此时剩下
N*K个数据,如果内存不能容纳N*K个数据,则再继续分治处理,分成M份,找出每份数据中最大的K个数,如果M*K个数仍然不能读到内存中,则继续分治处理。直到剩余的数可以读入内存中,那么可以对这些数使用快速排序的变形或者归并排序进行处理。 -
Hash法
如果这些数据中有很多重复的数据,可以先通过hash法,把重复的数去掉。这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间。处理后的数据如果能够读入内存,则可以直接排序;否则可以使用分治法或者最小堆法来处理数据。
-
计数排序法
首先利用哈希表统计数组中个元素出现的次数,然后利用计数排序的思想,线性从大到小扫描过程中,前面有k-1个数则为第k大的数
7. 说一下快排最差情况推导
如果输入的数组最大(或者最小元素)被选为枢轴,那最坏的情况就来了:
1)数组已经是正序排过序的。 (每次最右边的那个元素被选为枢轴)
2)数组已经是倒序排过序的。 (每次最左边的那个元素被选为枢轴)
3)所有的元素都相同(1、2的特殊情况)
因为这些案例在用例中十分常见,所以这个问题可以通过要么选择一个随机的枢轴,或者选择一个分区中间的下标作为枢轴,或者(特别是对于相比更长的分区)选择分区的第一个、中间、最后一个元素的中值作为枢轴。有了这些修改,那快排的最差的情况就不那么容易出现了,
快速排序,在最坏情况退化为冒泡排序,需要比较$O(n^2)$次($n(n - 1)/2$次)。
8. 说一下hash表的实现,包括STL中的哈希桶长度常数
hash表的实现主要包括构造哈希和处理哈希冲突两个方面:
8.1 散列函数的构造方法:
-
直接定址法
$f(key) = a \times key + b$ (a, b 为常数)
简单并且不会产生冲突,但是需要提前知道关键字的分布情况,适合范围小并且连续的情况。实际应用中并不常用。
-
平方取中法
对一个数值做平方然后取其中间的几位数。例如key是1234,其平方是1522756,那么散列地址就是中间几位数,比如227。适合不知道key的范围,但是key的位数又不大的情况
-
除留余数法(重点)
$f(key) = key \mod p(p \le m)$
当散列表大小为m时,选择一个数值p,让key对p取模。(通常p选择小于等于m的最小质数或不包含小于20的质因子的合数)
实际中最常用的构造散列函数方法。
-
随机数法
$f(key) = random(key)(这里random是随机函数)$
当key的长度不等时,采用该方法比较合适
实际运用中应该视不同情况采用不同的散列函数,例如:
- 计算散列地址所需要的时间
- 关键字key的长度
- 散列表的大小
- 关键字key的分布情况
- 查找的频率
8.2 处理哈希冲突的方法:
-
开放定址法
$f_i(key) = (f(key) + d_i) \mod m(d_i = 1,2,3…m-1)$
所谓的开放定址法,就是一旦遇到冲突,就去寻找下一个空的散列地址,然后将其填入。这种每次加一的开放定址法我们称之为线性探测法
$f_i(key) = (f(key) + d_i) \mod m(d_i = 1^2,-1^2,2^2,-2^2…q^2, -q^2, q\le m/2)$
线性探测法会出现本来不是同义词的两个key争夺同一个散列地址的情况,这种情况我们称之为堆积,为了解决这种情况,我们在其基础上增加了平方运算,我们称之为二次探测法
-
再散列函数法
$f_i(key) = RH_i(key) (i = 1,2,…,k)$
散列表事先准备多个散列函数,每当出现地址冲突,就换一个散列函数。
-
链地址法(重点)
将散列表设置为指针数组,即每个元素存的都是一个指针,这样当遇到地址冲突时,就不用再找其它空的地址,而是直接将其链接到该地址的链表结尾。
可能会退化成整个散列表只有一个单链表,那么时间复杂度就退化成$O(n)$了
插入:SGI STL中哈希表的插入是首先根据键得到对应的单链表头,然后遍历链表检查是否已经存在该键,遍历完后若不存在,则将新的元素作为新的链表头插入链表;若已经存在,那么就将新的结点插入已经存在的结点之后(允许重复键的哈希表)。
SGI STL中称hash table表格内的元素为桶(bucket),表示的时哈希表中每个单元涵盖的不是一个结点,而是一桶结点(即链表)
虽然链地址法并不要求哈希表格大小必须为质数,但SGI STL仍然以质数来设计哈希表格大小,并且将28个质数(第一个质数为53,往后逐渐呈现大约两倍的关系)计算好,以备随时访问,同时提供一个函数,用来查询在这28个质数之中,“最接近某数并大于某数”的质数。
-
公共溢出区法
将所有冲突的关键字key都存在一个公共溢出区里
9. 说一下哈希表的桶个数为什么是质数,合数有何不妥?
哈希表的桶个数使用质数,可以最大程度减小冲突概率,使哈希后的数据分布得更加均匀。
如果使用合数,可能会造成很多数据分布会集中在某些点上,从而影响哈希表效率。
10. 说一下hash表如何rehash,以及怎么处理其中保存的资源
如果当前哈希表中所有元素加上待插入元素的总数大于哈希表中桶的数量(哈希表底层是使用vector实现,vector中元素为链表头结点),即bucket.size(),那么就会重建哈希表,而新的哈希表大小为当前哈希表大小的下一个质数(比当前大小大的最小质数),然后把原来的哈希表中元素全部重新哈希到新的哈希表中。–《Stl源码剖析》
“表格重建与否”的判断原则颇为奇特,是拿元素个数(把新增元素计入后)和bucket vector的大小来比。如果前者大于后者,就重建表格。由此可以判断,每个bucket(list)的最大容量和bucket vector的大小相同。
注意:这里把旧哈希表中元素全部映射到新的哈希表中的背景是SGI STL中的hash table的实现。其实现是链地址法,但是原映射表中的同义词在新哈希表中就不一定是同义词了,所以我们不能简单的将原哈希表中的链表头结点转移到新的哈希表中就好了,而是要对每一条链表中的每一个结点都重新做哈希运算,判断其落到新的哈希表中的哪个桶中,然后再将其转移到那个位置。
13. 说一下常见的加密方法
13.1 单向加密
单向加密又称为不可逆加密算法,其密钥是由加密散列函数生成的。单向散列函数一般用于产生消息摘要,密钥加密等,常见的有:
MD5(Message Digest Algorithm 5):是RSA数据安全公司开发的一种单向散列算法,非可逆,相同的明文产生相同的密文;
SHA(Secure Hash Algorithm):可以对任意长度的数据运算生成一个160位的数值。其变种有SHA192,SHA256,SHA384等;
CRC-32,主要用于提供校验功能;
算法特征:
-
输入一样,输出必然相同;
-
雪崩效应,输入的微小改变,将会引起结果的巨大变化;
-
定长输出,无论原始数据多大,结果大小都是相同的;
-
不可逆,无法根据特征码还原原来的数据;
13.2 对称加密
采用单钥密码系统的加密方法,同一个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单密钥加密。
特点:
-
加密方和解密方使用同一个密钥;
-
加密解密的速度比较快,适合数据比较长时的使用;
-
密钥传输的过程不安全,且容易被破解,密钥管理也比较麻烦;
优点:对称加密算法的优点是算法公开、计算量小、加密速度快、加密效率高。
缺点:对称加密算法的缺点是在数据传送前,发送方和接收方必须商定好秘钥,然后使双方都能保存好秘钥。其次如果一方的秘钥被泄露,那么加密信息也就不安全了。另外,每对用户每次使用对称加密算法时,都需要使用其他人不知道的唯一秘钥,这会使得收、发双方所拥有的钥匙数量巨大,密钥管理成为双方的负担。
13.3 非对称加密
非对称密钥加密也称为公钥加密,由一对公钥和私钥组成。公钥是从私钥提取出来的。可以用公钥加密,再用私钥解密,这种情形一般用于公钥加密,当然也可以用私钥加密,用公钥解密。常用于数字签名,因此非对称加密的主要功能就是加密和数字签名。
特征:
秘钥对,公钥(public key)和私钥(secret key)
主要功能:加密和签名
发送方用对方的公钥加密,接收方用自己的私钥解密,可以保证数据的机密性(公钥加密)。
发送方用自己的私钥加密,接收方使用发送方发过来的公钥解密,可以实现身份验证(数字签名)。
公钥加密算法很少用来加密数据,速度太慢,通常用来实现身份验证。
常用的非对称加密算法
RSA:由 RSA公司发明,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的;既可以实现加密,又可以实现签名。
DSA(Digital Signature Algorithm):数字签名算法,是一种标准的 DSS(数字签名标准)。
ECC(Elliptic Curves Cryptography):椭圆曲线密码编码。
操作系统
1. 说一下进程和线程的联系及区别
进程和线程的关系
- 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程是操作系统可识别的最小执行和调度单位。
- 资源分配给进程,同一进程的所有线程共享该进程的所有资源。 同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。
- 处理机分给线程,即真正在处理机上运行的是线程。
- 线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
进程与线程的区别
- 地址空间和其它资源(如打开文件):进程是资源分配的基本单位,线程不拥有资源,但线程可以访问隶属进程的资源。进程间资源相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
- 通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
- 调度和切换:线程上下文切换比进程上下文切换要快得多。线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
- 系统开销:由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
- 在多线程OS中,进程不是一个可执行的实体。
- 进程是资源分配的最小单位,线程是CPU调度的最小单位。
- 进程间不会相互影响 ;线程一个线程挂掉将导致整个进程挂掉。
- 进程编程调试简单可靠性高,但是创建销毁开销大;线程正相反,开销小,切换速度快,但是编程调试相对复杂。
2. 说一下进程间的通信方式
进程间通信(IPC,Inter-Process Communication)指至少两个进程或线程间传送数据或信号的一些技术或方法。主要方法有:管道、信号、共享内存、消息队列、信号量、套接字、文件。
2.1 管道Pipeline
管道主要包括无名管道和命名管道:管道可用于具有亲缘关系的父子进程间的通信,有名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信
- 普通管道PIPE:
- 它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端
- 它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)
- 它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
- 命名管道FIFO:
- FIFO可以在无关的进程之间交换数据
- FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
2.2 信号量semaphore
信号量(semaphore)与已经介绍过的 IPC 结构不同,在计算机里,信号量实际上就是一个简单整数。它是一个计数器,可以用来控制多个进程对共享资源的访问。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
特点:
- 信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
- 信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作(操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。)
- 每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
- 支持信号量组。
2.3 信号signal
我们为什么需要信号:
- 首先,如果使用管道和套接字方式来通信,必须事先在通信的进程间建立连接(创建管道或套接字),这需要消耗系统资源。
- 其次,通信是自愿的。即一方虽然可以随意向管道或套接字发送信息,但对方却可以选择接收的时机。即使对方对此充耳不闻,你也奈何不得。
- 再次,由于建立连接消耗时间,一旦建立,我们就想进行尽可能多的通信。而如果通信的信息量微小,如我们只是想通知一个进程某件事情的发生,则用管道和套接字就有点“杀鸡用牛刀”的味道,效率十分低下。
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
那么信号是什么呢?在计算机里,信号就是一个内核对象,或者说是一个内核数据结构。发送方将该数据结构的内容填好,并指明该信号的目标进程后,发出特定的软件中断。操作系统接收到特定的中断请求后,知道是有进程要发送信号,于是到特定的内核数据结构里查找信号接收方,并进行通知。接到通知的进程则对信号进行相应处理。
2.4 共享内存Shared Memory
共享内存就是两个进程共同拥有同一片内存。对于这片内存中的任何内容,二者均可以访问。要使用共享内存进行通信,一个进程首先需要创建一片内存空间专门作为通信用,而其他进程则将该片内存映射到自己的(虚拟)地址空间。这样,读写自己地址空间中对应共享内存的区域时,就是在和其他进程进行通信。
乍一看,共享内存有点像管道,有些管道不也是一片共享内存吗?这是形似而神不似。首先,使用共享内存机制通信的两个进程必须在同一台物理机器上;其次,共享内存的访问方式是随机的,而不是只能从一端写,另一端读,因此其灵活性比管道和套接字大很多,能够传递的信息也复杂得多。
共享内存的缺点是管理复杂,且两个进程必须在同一台物理机器上才能使用这种通信方式。共享内存的另外一个缺点是安全性脆弱。因为两个进程存在一片共享的内存,如果一个进程染有病毒,很容易就会传给另外一个进程。就像两个紧密接触的人,一个人的病毒是很容易传染另外一个人的。
这里需要注意的是,使用全局变量在同一个进程的进程间实现通信不称为共享内存。
它使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。
特点:
- 共享内存是最快的一种IPC,因为进程是直接对内存进行存取
- 因为多个进程可以同时操作,所以需要进行同步
- 信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问
共享内存API:
-
shmget
#include <sys/shm.h> int shmget(key_t key, size_t size, int shmflg); //key标识一段全局唯一的共享内存 //size表示要申请的共享内存大小 //shmflg表示共享内存标志在size大于0时,表示创建一段新的共享内存(内存会被初始化为0)。
在size等于0时,表示通过key获取已经存在的共享内存
shmget成功时返回一个正整数(共享内存的标识符);失败时返回-1。
-
shmat和shmdt
共享内存被创建或获取后,我们还不能立即访问它,而是需要先将它关联到进程的地址空间中。在使用完共享内存后,我们也需要将它从进程地址空间中分离。这两项任务就分别由shmat和shmdt来完成。
#include <sys/shm.h> void* shmat(int shm_id, const void* shm_addr, int shmflg); int shmdt(const void* shm_addr); //shm_id是由shmget调用后返回的共享内存标识符 //shm_addr指定将共享内存关联到进程的哪块地址空间 -
shmctl
shmctl系统调用控制共享内存的某些属性。定义如下:
#include <sys/shm.h> int shmctl(int shm_id, int command, struct shmid_ds* buf); //shm_id是由shmget调用后返回的共享内存标识符 //command参数指定要执行的命令命令如下:
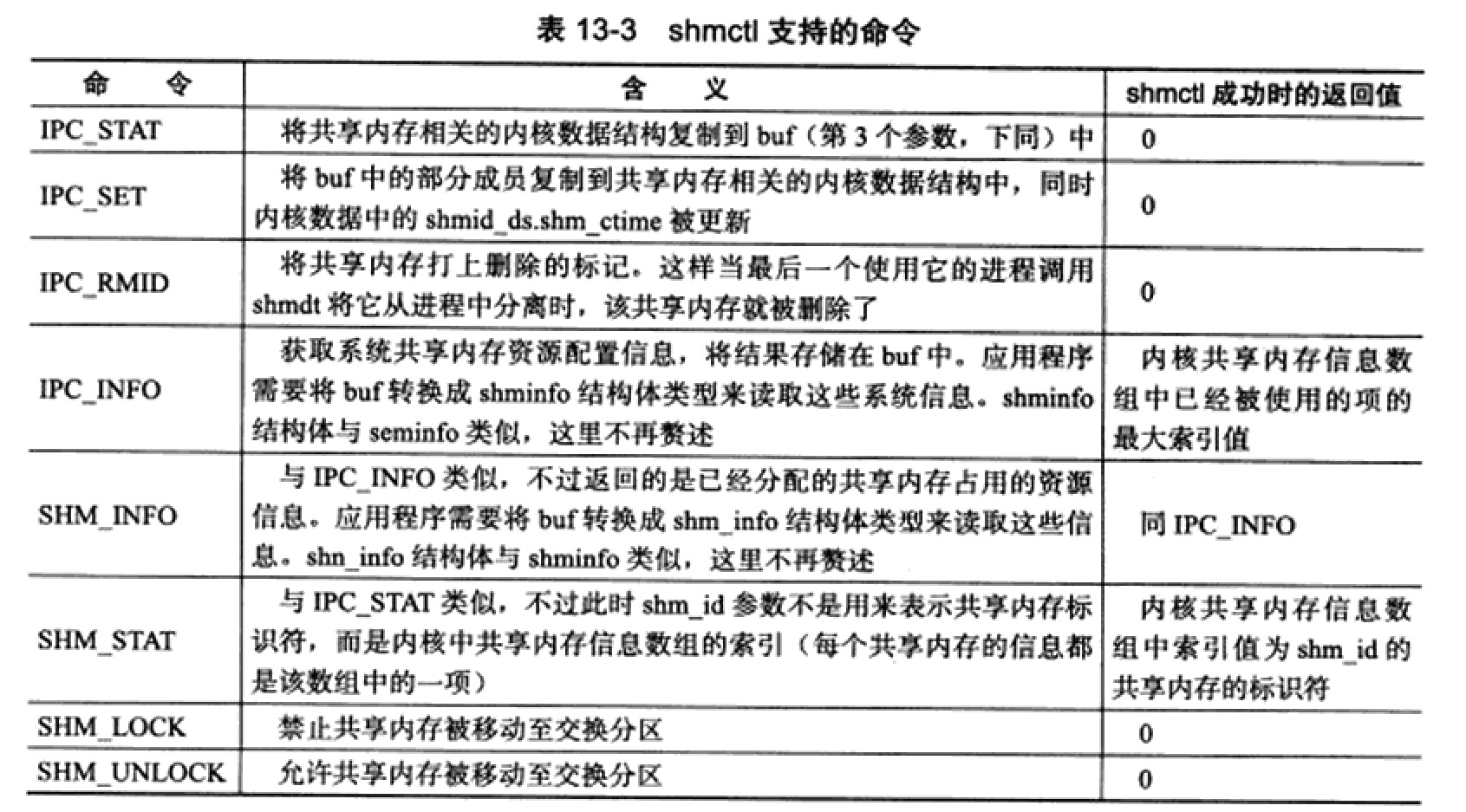
shmctl调用成功的返回值取决于 command 参数,失败时返回-1。
2.5 套接字socket
socket也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同主机之间的进程通信。
2.6 消息队列
消息队列是一列具有头和尾的消息排列。新来的消息放在队列尾部,而读取消息则从队列头部开始。
乍一看,这不是管道吗?一头读、一头写?没错。这的确看上去像管道,但它不是管道。首先,它无需固定的读写进程,任何进程都可以读写(当然是有权限的进程)。其次,它可以同时支持多个进程,多个进程可以读写消息队列。即所谓的多对多,而不是管道的点对点。另外,消息队列只在内存中实现。最后,它并不是只在UNIX和类UNIX操作系统中实现。几乎所有主流操作系统都支持消息队列。
3. 说一下线程间的通信(同步)方式
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
- 临界区(Critical Section):适合一个进程内的多线程访问公共区域或代码段时使用
- 互斥量 (Mutex):适合不同进程内多线程访问公共区域或代码段时使用,与临界区相似。
- 事件(Event):通过线程间触发事件实现同步互斥
- 信号量(Semaphore):与临界区和互斥量不同,可以实现多个线程同时访问公共区域数据,原理与操作系统中PV操作类似,先设置一个访问公共区域的线程最大连接数,每当有一个线程访问共享区资源数就减一,直到资源数小于等于零。
临界区
通过多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问;
互斥量
互斥量又称互斥锁,主要用于线程互斥,不能保证按序访问,可以和条件锁一起实现同步。当进入临界区时,需要获得互斥锁并且加锁;当离开临界区时,需要对互斥锁解锁,以唤醒其他等待该互斥锁的线程。其主要的系统调用如下:
-
pthread_mutex_init:初始化互斥锁
-
pthread_mutex_destroy:销毁互斥锁
-
pthread_mutex_lock:以原子操作的方式给一个互斥锁加锁,如果目标互斥锁已经被上锁,pthread_mutex_lock 调用将阻塞,直到该互斥锁的占有者将其解锁。
-
pthread_mutex_unlock:以一个原子操作的方式给一个互斥锁解锁。
信号量
为控制具有有限数量的用户资源而设计的,它允许多个线程在同一时刻去访问同一个资源,但一般需要限制同一时刻访问此资源的最大线程数目。
它只取自然数值,并且只支持两种操作:
-
P(SV):如果信号量SV大于0,将它减一;如果SV值为0,则挂起该线程。
-
V(SV):如果有其他线程因为等待SV而挂起,则唤醒,然后将SV+1;否则直接将SV+1。
其系统调用为:
-
sem_wait(sem_t *sem):以原子操作的方式将信号量减1,如果信号量值为0,则sem_wait将被阻塞,直到这个信号量具有非0值。
-
sem_post(sem_t *sem):以原子操作将信号量值+1。当信号量大于0时,其他正在调用sem_wait等待信号量的线程将被唤醒。
事件(信号)
通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作
6. 说一下线程同步和线程互斥的区别
同步,又称直接制约关系,是指多个线程(或进程)为了合作完成任务,必须严格按照规定的某种先后次序来运行。
互斥,又称间接制约关系,是指系统中的某些共享资源,一次只允许一个线程访问。当一个线程正在访问该临界资源时,其它线程必须等待。
区别
- 互斥是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
- 同步是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。
- 同步其实已经实现了互斥,所以同步是一种更为复杂的互斥。互斥是一种特殊的同步。
7. 说一下select、poll、epoll
7.1 select
- 单个进程可监视的fd数量被限制,默认1024
- 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低
- 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
7.2 poll
- 它没有最大连接数的限制,原因是它是基于链表来存储
- 大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义
- “水平触发”,如果报告了fd后,没有被处理,那么下次触发poll时会再次报告该fd
7.3 epoll
- 没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口)
- 效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
- 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
7.4 总结
(1)select==>时间复杂度O(n)
它仅仅知道有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的。链表结点是结构体,该结构体保存描述符的信息,每增加一个文件描述符就向链表中加入一个结构体,结构体只需要拷贝一次到内核态。poll解决了select重复初始化的问题。轮寻排查的问题未解决。
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以同时监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
8. 说一下孤儿进程和僵尸进程?
孤儿进程(Orphan Process):一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。孤儿进程是没有父进程的进程,照看孤儿进程这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
僵尸进程:一个子进程在其父进程还没有调用wait()或waitpid()的情况下退出,这个子进程就是僵尸进程。任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理。这是每个子进程在结束时都要经过的阶段。如果子进程在exit()之后,父进程没有来得及处理,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量地产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
9. 说一下Linux虚拟地址空间
虚拟内存技术使得不同进程在运行过程中,它所看到的是自己独自占有了当前系统的4G内存。所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。 事实上,在每个进程创建加载时,内核只是为进程“创建”了虚拟内存的布局,具体就是初始化进程控制表中内存相关的链表,实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射),等到运行到对应的程序时,才会通过缺页异常,来拷贝数据。还有进程运行过程中,要动态分配内存,比如malloc时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
请求分页系统、请求分段系统和请求段页式系统都是针对虚拟内存的,通过请求实现内存与外存的信息置换。
好处
- 扩大地址空间;
- 内存保护:每个进程运行在各自的虚拟内存地址空间,互相不能干扰对方。虚存还对特定的内存地址提供写保护,可以防止代码或数据被恶意篡改。
- 公平内存分配。采用了虚存之后,每个进程都相当于有同样大小的虚存空间。
- 当进程通信时,可采用虚存共享的方式实现。
- 当不同的进程使用同样的代码时,比如库文件中的代码,物理内存中可以只存储一份这样的代码,不同的进程只需要把自己的虚拟内存映射过去就可以了,节省内存
- 虚拟内存很适合在多道程序设计系统中使用,许多程序的片段同时保存在内存中。当一个程序等待它的一部分读入内存时,可以把CPU交给另一个进程使用。在内存中可以保留多个进程,系统并发度提高
- 在程序需要分配连续的内存空间的时候,只需要在虚拟内存空间分配连续空间,而不需要实际物理内存的连续空间,可以利用碎片
代价
- 虚存的管理需要建立很多数据结构,这些数据结构要占用额外的内存
- 虚拟地址到物理地址的转换,增加了指令的执行时间。
- 页面的换入换出需要磁盘I/O,这是很耗时的
- 如果一页中只有一部分数据,会浪费内存,产生内存碎片。
10. 说一下操作系统中的程序的内存结构

一个程序本质上都是由BSS段、data段、text段三个部分组成的。可以看到一个可执行程序在存储(没有调入内存)时分为代码段、数据区和未初始化数据区三部分。可执行程序在运行时又多出两个区域:栈区和堆区。
- BSS段(未初始化数据区):通常用来存放程序中未初始化的全局变量和静态变量的一块内存区域。BSS段属于静态分配,程序结束后静态变量资源由系统自动释放。不占用可执行文件的大小,它是由链接器来获取内存的。
- 数据段:分为读写数据段(rw data) 和 只读数据段(ro data)。存放程序中已初始化的全局变量的一块内存区域。数据段也属于静态内存分配,在编译时已经分配了空间。数据段包含经过初始化的全局变量以及它们的值。BSS段的大小从可执行文件中得到,然后链接器得到这个大小的内存块,紧跟在数据段的后面。当这个内存进入程序的地址空间后全部清零。包含数据段和BSS段的整个区段此时通常称为数据区。
- 代码段:存放程序执行代码的一块内存区域。在编译时已经分配了空间,并且内存区域属于只读。在代码段中,也有可能包含一些只读的常数变量
- 栈区:存放函数的参数值、局部变量等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存放到栈中。然后这个被调用的函数再为他的自动变量和临时变量在栈上分配空间。每调用一个函数就会在当前栈顶产生一个新的栈帧。栈区是从高地址位向低地址位增长的,是一块连续的内存区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小。
- 堆区:用于动态分配内存,位于BSS和栈中间的地址区域。由程序员申请分配和释放。堆是从低地址位向高地址位增长,采用链式存储结构。频繁的malloc/free会造成内存空间的不连续,产生碎片。当申请堆空间时库函数是按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多。
1 #include <iostream>
2 using namespace std;
3
4 int global_1 = 1; //全局变量 rw区
-- 5 static int static_1 = 1; //全局静态变量 rw区
6
7 int global_2; //未初始化全局变量 BSS区
-- 8 static int static_2; //未初始化全局静态变量 BSS区
9
-- 10 const int global_3 = 3; //const全局变量 ro区 (更改该区域会发生段错误)
-- 11 const static int static_3 = 3; //const全局静态变量 ro区(更改该区域会发生段错误)
12
13 int main() {
-- 14 static int static_tmp_1 = 1; //初始化局部静态变量 BSS区
-- 15 static int static_tmp_2; //未初始化局部静态变量 BSS区
16
-- 17 int tmp_1 = 1; //初始化局部变量 栈区
-- 18 int tmp_2; //未初始化局部变量 没有分配内存
19
-- 20 const int tmp_const_1 = 2; //初始化局部const变量 栈区
21
22 return 0;
23 }
11. 说一下操作系统中的缺页中断
malloc()和mmap()等内存分配函数,在分配时只是建立了进程虚拟地址空间,并没有分配虚拟内存对应的物理内存。当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常。
缺页中断:在请求分页系统中,可以通过查询页表中的状态位来确定所要访问的页面是否存在于内存中。每当所要访问的页面不在内存中时,就会产生一次缺页中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存。
缺页本身是一种中断,与一般的中断一样,需要经过4个处理步骤:
- 保护CPU现场
- 分析中断原因
- 转入缺页中断处理程序进行处理
- 恢复CPU现场,继续执行
但是缺页中断是由于所要访问的页面不存在于内存时,由硬件所产生的一种特殊的中断,因此,与一般的中断存在区别:
- 在指令执行期间产生和处理缺页中断信号
- 一条指令在执行期间,可能产生多次缺页中断
- 缺页中断返回时,执行产生中断的一条指令,而一般的中断返回是,执行下一条指令。
12. 说一下fork和vfork的区别
12.1 fork
创建一个和当前进程映像一样的进程可以通过fork( )系统调用:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
成功调用fork( )会创建一个新的进程,它几乎与调用fork( )的进程一模一样,这两个进程都会继续运行(运行次序无法预知)。在子进程中,成功的fork( )调用会返回0。在父进程中fork( )返回子进程的pid。如果出现错误,fork( )返回一个负值。
Linux采用了写时复制的方法,以减少fork时对父进程空间进程整体复制带来的开销。如果进程从来就不需要修改资源,则不需要进行复制。在使用虚拟内存的情况下,写时复制(Copy-On-Write)是以页为基础进行的。所以,只要进程不修改它全部的地址空间,那么就不必复制整个地址空间。在fork( )调用结束后,父进程和子进程都相信它们有一个自己的地址空间,但实际上它们共享父进程的原始页,接下来这些页又可以被其他的父进程或子进程共享。
在调用fork( )时,写时复制是有很大优势的。因为大量的fork之后都会跟着执行exec,那么复制整个父进程地址空间中的内容到子进程的地址空间完全是在浪费时间:如果子进程立刻执行一个新的二进制可执行文件的映像,它先前的地址空间就会被交换出去。写时复制可以对这种情况进行优化。
12.2 vfork
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
vfork( )会挂起父进程直到子进程终止或者运行了一个新的可执行文件的映像。通过这样的方式,vfork( )避免了地址空间的按页复制。在这个过程中,父进程和子进程共享相同的地址空间和页表项。实际上vfork( )只完成了一件事:复制内部的内核数据结构。因此,子进程也就不能修改地址空间中的任何内存。
fork和vfork的区别
- fork( )的子进程拷贝父进程的数据段和代码段;vfork( )的子进程与父进程共享数据段
- fork( )的父子进程的执行次序不确定;vfork( )保证子进程先运行,在调用exec或exit之前与父进程数据是共享的,在它调用exec或exit之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
- 当需要改变共享数据段中变量的值,则拷贝父进程。
13. 说一下如何修改文件最大句柄数?
背景:linux默认最大文件句柄数是1024个,在linux服务器文件并发量比较大的情况下,系统会报”too many open files”的错误。故在linux服务器高并发调优时,往往需要预先调优Linux参数,修改Linux最大文件句柄数。
两种方法:
-
ulimit -n <可以同时打开的文件数>,将当前进程的最大句柄数修改为指定的参数(注:该方法只针对当前进程有效,重新打开一个shell或者重新开启一个进程,参数还是之前的值)首先用
ulimit -a查询Linux相关的参数:core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 94739 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) 94739 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited其中,open files就是最大文件句柄数,默认是1024个。
修改Linux最大文件句柄数:
ulimit -n 2048, 将最大句柄数修改为 2048个。 -
对所有进程都有效的方法,修改Linux系统参数
vim /etc/security/limits.conf 添加
* soft nofile 65536 * hard nofile 65536将最大句柄数改为65536
修改以后保存,注销当前用户,重新登录,修改后的参数就生效了
14. 说一下并发(concurrency)和并行(parallelism)
- 并发(concurrency):指宏观上看起来两个程序在同时运行,比如说在单核cpu上的多任务。但是从微观上看两个程序的指令是交织着运行的,你的指令之间穿插着我的指令,我的指令之间穿插着你的,在单个周期内只运行了一个指令。这种并发并不能提高计算机的性能,只能提高效率。
- 并行(parallelism):指严格物理意义上的同时运行,比如多核cpu,两个程序分别运行在两个核上,两者之间互不影响,单个周期内每个程序都运行了自己的指令,也就是运行了两条指令。这样说来并行的确提高了计算机的效率。所以现在的cpu都是往多核方面发展。
15. 说一下操作系统中的页表寻址
页式内存管理,内存分成固定长度的一个个页片。操作系统为每一个进程维护了一个从虚拟地址到物理地址的映射关系的数据结构,叫页表,页表的内容就是该进程的虚拟地址到物理地址的一个映射。页表中的每一项都记录了这个页的基地址。通过页表,由逻辑地址的高位部分先找到逻辑地址对应的页基地址,再由页基地址偏移一定长度就得到最后的物理地址,偏移的长度由逻辑地址的低位部分决定。一般情况下,这个过程都可以由硬件完成,所以效率还是比较高的。页式内存管理的优点就是比较灵活,内存管理以较小的页为单位,方便内存换入换出和扩充地址空间。
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射关系。
一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。
16. 说一下为什么有了进程还要有线程?
进程可以使多个程序能并发执行,以提高资源的利用率和系统的吞吐量;但是其具有一些缺点:进程在同一时间只能干一件事。进程在执行的过程中如果阻塞,整个进程就会挂起,即使进程中有些工作不依赖于等待的资源,仍然不会执行。
因此,操作系统引入了比进程粒度更小的线程,作为并发执行的基本单位,从而减少程序在并发执行时所付出的时空开销,提高并发性。和进程相比,线程的优势如下:
-
从资源上来讲,线程是一种非常”节俭”的多任务操作方式。在linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种”昂贵”的多任务工作方式。
-
从切换效率上来讲,运行于一个进程中的多个线程,它们之间使用相同的地址空间,而且线程间彼此切换所需时间也远远小于进程间切换所需要的时间。据统计,一个进程的开销大约是一个线程开销的30倍左右。
-
从通信机制上来讲,线程间通信机制更方便。对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过进程间通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其他线程所用,这不仅快捷,而且方便。
除以上优点外,多线程程序作为一种多任务、并发的工作方式,还有如下优点:
1、使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
2、改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序才会利于理解和修改。
17. 说一下单核机器上写多线程程序,是否需要考虑加锁,为什么?
在单核机器上写多线程程序,仍然需要线程锁。因为线程锁通常用来实现线程的同步和通信。在单核机器上的多线程程序,仍然存在线程同步的问题。因为在抢占式操作系统中,通常为每个线程分配一个时间片,当某个线程时间片耗尽时,操作系统会将其挂起,然后运行另一个线程。如果这两个线程共享某些数据,不使用线程锁的前提下,可能会导致共享数据修改而引起冲突。
18. 说一下OS缺页置换算法
当访问一个内存中不存在的页,并且内存已满,则需要从内存中调出一个页或将数据送至磁盘对换区,替换一个页,这种现象叫做缺页置换。当前操作系统最常采用的缺页置换算法如下:
18.1 FIFO
- FIFO(先进先出)算法:置换最先调入内存的页面,即置换在内存中驻留时间最久的页面。
- 思想:最近刚访问的,将来访问的可能性比较大。
- 实现:使用一个队列,新加入的页面放入队尾,每次淘汰队首的页面,即最先进入的数据,最先被淘汰。
- 弊端:无法体现页面冷热信息
18.2 LFU
- LFU(Least Frequently Used,最少使用算法)
- 思想:如果数据过去被访问多次,那么将来被访问的频率也更高。
- 概述:最近最不常使用,缓存容量满的时候,置换使用频次最小的那个。
- 实现:每个数据块一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。每次淘汰队尾数据块。(HashMap 加上小顶堆。每次排序,容量满则置换堆头。)
- 开销:排序开销。
- 弊端:缓存颠簸。
18.3 LRU
- LRU(Least Recently Used,最久未使用算法):置换最近一段时间以来最长时间未访问过的页面。根据程序局部性原理,刚被访问的页面,可能马上又要被访问;而较长时间内没有被访问的页面,可能最近不会被访问。
- 思想:如果数据最近被访问过,那么将来被访问的几率也更高。
- 概述:最近最少使用,缓存容量满的时候,置换最长时间没有使用的那个。
- 实现:HashMap 加上双向链表。访问过的数据就移动到链表头,容量满了删除链表尾。
- 优点:LRU算法对热点数据命中率是很高的。
18.4 LRU-K
-
LRU-K(最久未使用K次淘汰算法)
LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
当前最常采用的就是LRU算法。
19. 说一下多进程和多线程的使用场景
多进程模型的优势是CPU,而多线程模型主要优势为线程间切换代价较小,因此适用于I/O密集型的工作场景,I/O密集型的工作场景经常会由于I/O阻塞导致频繁的切换线程。同时,多线程模型也适用于单机多核分布式场景。
多进程模型,适用于CPU密集型。同时,多进程模型也适用于多机分布式场景中,易于多机扩展。
20. 说一下死锁发生的条件以及如何解决死锁
如果一个进程集合中的每个进程都在等待只能由该进程集合中的其它进程才能引发的事件,那么,该进程集合就是死锁的。
——《现代操作系统第三版》
一个简单的例子:有两个进程分别称为A、B,两个资源分别为1、2,两个进程都需要获取1、2才能继续运行。此时如果A获取了1,B获取了2,那么接下来A一定会请求获取2,B也一定会请求获取1。而2已经被B使用,因此A只能等待B释放;同样1已经被A使用,B只能等待A释放。A、B都在等待,但没有人会释放,这样的等待是没有结果的。这样就导致了死锁。
死锁是指两个或两个以上进程在执行过程中,因争夺资源而造成的相互等待的现象。死锁发生的四个必要条件如下:
- 互斥条件:进程所分配到的资源不允许其他进程访问,若其他进程访问该资源,只能等待,直至占有该资源的进程使用完成后释放该资源;
- 请求和保持条件:进程获得一定的资源后,又对其他资源发出请求,但是该资源可能被其他进程占有,此时请求阻塞,但该进程不会释放自己已经占有的资源
- 不可剥夺条件:进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用后自己释放
- 环路等待条件:进程发生死锁后,必然存在一个进程-资源之间的环形链
处理死锁总的来说有以下四种策略:
策略一:直接忽略
最简单的解决方法是鸵鸟算法:把头埋到沙子里,假装根本没有问题发生。适用于死锁发生的频率特别低,如死锁平均每5年发生一次。
策略二:检查死锁并恢复
让死锁发生,检测它们是否发生,一旦发生死锁,采取行动解决死锁。
检测死锁
-
每种类型只有一个资源的死锁检测
这样的系统可能有一台扫描仪、一台CD刻录机、一台绘图仪和一台磁带机,但每种类型的资源都不超过一个。可以对这样的系统构造一张资源分配图,如果这张图包含了一个或一个以上的环,那么死锁就存在。在此环中的任何一个进程都是死锁进程。如果没有这样的环,系统就没有发生死锁。
1)A进程持有R资源,且需要S资源。 2)B进程不持有任何资源,但需要T资源。 3)C进程不持有任何资源,但需要S资源。 4)D进程持有U资源,且需要S资源和T资源。 5)E进程持有T资源,且需要V资源。 6)F进程持有W资源,且需要S资源。 7)G进程持有V资源,且需要U资源。 问题是:“系统是否存在死锁?如果存在的话,死锁涉及了哪些进程?”
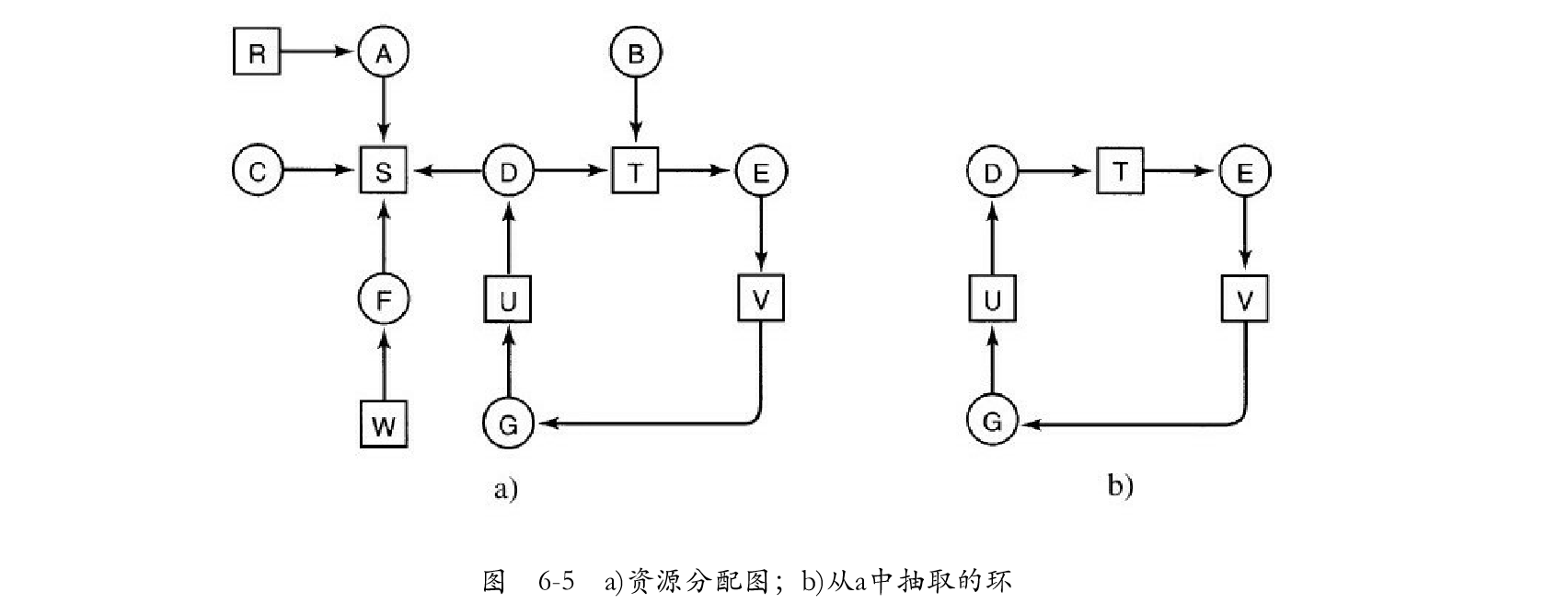
-
每种类型多个资源的死锁检测
现在我们提供一种基于矩阵的算法来检测从P1 到Pn 这n个进程中的死锁。假设资源的类型数为m,E1 代表资源类型1,E2 代表资源类型2,Ei 代表资源类型i(1≤i≤m)。E是现有资源向量(existing resource vector),代表每种已存在的资源总数。假设A是可用资源向量(available resource vector),那么 Ai 表示当前可供使用的资源数(即没有被分配的资源)。现在我们需要两个数组:C代表当前分配矩阵(current allocation matrix),R代表请求矩阵(request matrix)。C的第i行代表进程Pi 当前所持有的每一种类型资源的资源数。所以,Cij 代表进程i所持有的资源j的数量。同理,Rij 代表Pi 所需要的资源j的数量。如图:
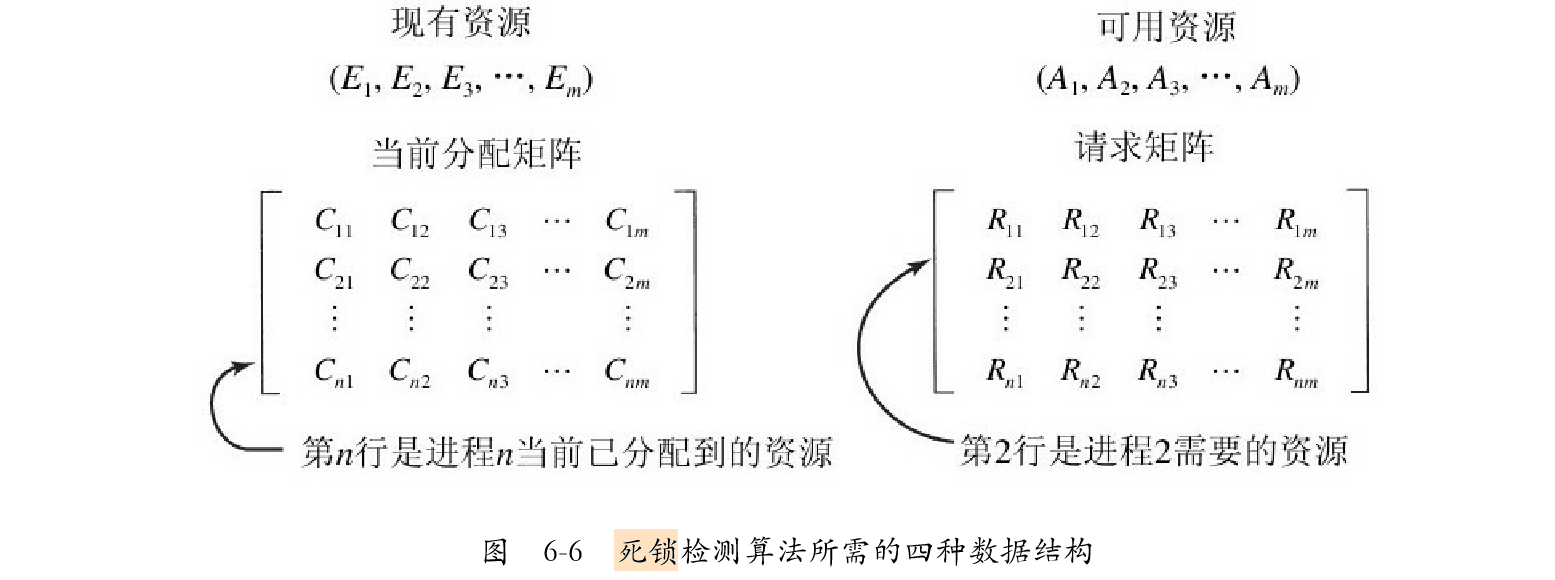
关于资源有一个重要的恒等式:$\sum_{i=1}^{n}{C_{ij}+E_{ij}=E_j}$
换言之,如果我们将资源j所有已分配的数量和可供使用的数量加起来,就是该资源的总数。
我们定义向量A和向量B之间的关系为 $A\le B 当且仅当 A_i \le B_i (0 \le i \le m)$
每个进程起初都是没有标记过的。算法开始会对进程做标记,进程被标记后就表明它们能够被执行,不会进入死锁。当算法结束时,任何没有标记的进程都是死锁进程。该算法假定了一个最坏情形:所有的进程在退出以前都会不停地获取资源。
死锁检测算法如下: 1)寻找一个没有标记的进程Pi ,对于它而言R矩阵的第i行向量小于或等于A。 2)如果找到了这样一个进程,那么将C矩阵的第i行向量加到A中,标记该进程,并转到第1步。 3)如果没有这样的进程,那么算法终止。 算法结束时,所有没有标记过的进程(如果存在的话)都是死锁进程。
算法的第1步是寻找可以运行完毕的进程,该进程的特点是它有资源请求并且该请求可被当前的可用资源满足。这一选中的进程随后就被运行完毕,在这段时间内它释放自己持有的所有资源并将它们返回到可用资源库中。然后,这一进程被标记为完成。如果所有的进程最终都能运行完毕的话,就不存在死锁的情况。如果其中某些进程一直不能运行,那么它们就是死锁进程。虽然算法的运行过程是不确定的(因为进程可按任何行得通的次序执行),但结果总是相同的。
-
其它的死锁检测算法有:
- 一、每当有资源请求时去检测。毫无疑问越早发现越好,但这种方法会占用昂贵的CPU时间。
- 二、每隔k分钟检测一次。
- 三、当CPU的使用率降到某一域值时去检测
从死锁中恢复
-
利用抢占恢复
在不通知原进程的情况下,将某一资源从一个进程强行取走给另一个进程使用,接着又送回,这种做法是否可行主要取决于该资源本身的特性。
-
利用回滚恢复
如果系统设计人员以及主机操作员了解到死锁有可能发生,他们就可以周期性地对进程进行检查点检查(checkpointed)。进程检查点检查就是将进程的状态写入一个文件以备以后回滚。该检查点中不仅包括存储映像,还包括了资源状态,即哪些资源分配给了该进程。为了使这一过程更有效,新的检查点不应覆盖原有的文件,而应写到新文件中。这样,当进程执行时,将会有一系列的检查点文件被累积起来。
-
通过杀死进程恢复
一种方法是杀掉环中的一个进程。如果走运的话,就可以解除死锁状态,其他进程将可以继续。运气不好,就需要继续杀死别的进程直到打破死锁环
另一种方法是选一个环外的进程作为牺牲品以释放该进程的资源。在使用这种方法时,选择一个要被杀死的进程要特别小心,它应该正好持有环中某些进程所需的资源
如果可以,最好杀死可以从头开始重新运行而且不会带来副作用的进程。比如,编译进程可以被重复运行,由于它只需要读入一个源文件和产生一个目标文件。如果将它中途杀死,它的第一次运行不会影响到第二次运行。
策略三:避免死锁
仔细对资源进行分配,动态地避免死锁。——银行家算法。
安全状态就是这样一个状态:存在一个事件序列,保证所有的进程都能完成。不安全状态就不存在这样的保证。银行家算法可以通过拒绝可能引起不安全状态的请求来避免死锁。
-
单个资源的银行家算法:
该模型基于一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度。算法要做的是判断对请求的满足是否会导致进入不安全状态。如果是,就拒绝请求;如果满足请求后系统仍然是安全的,就予以分配。在图6-11a中我们看到4个客户A、B、C、D,每个客户都被授予一定数量的贷款单位(比如1单位是1千美元),银行家知道不可能所有客户同时都需要最大贷款额,所以他只保留10个单位而不是22个单位的资金来为客户服务。这里将客户比作进程,贷款单位比作资源,银行家比作操作系统。
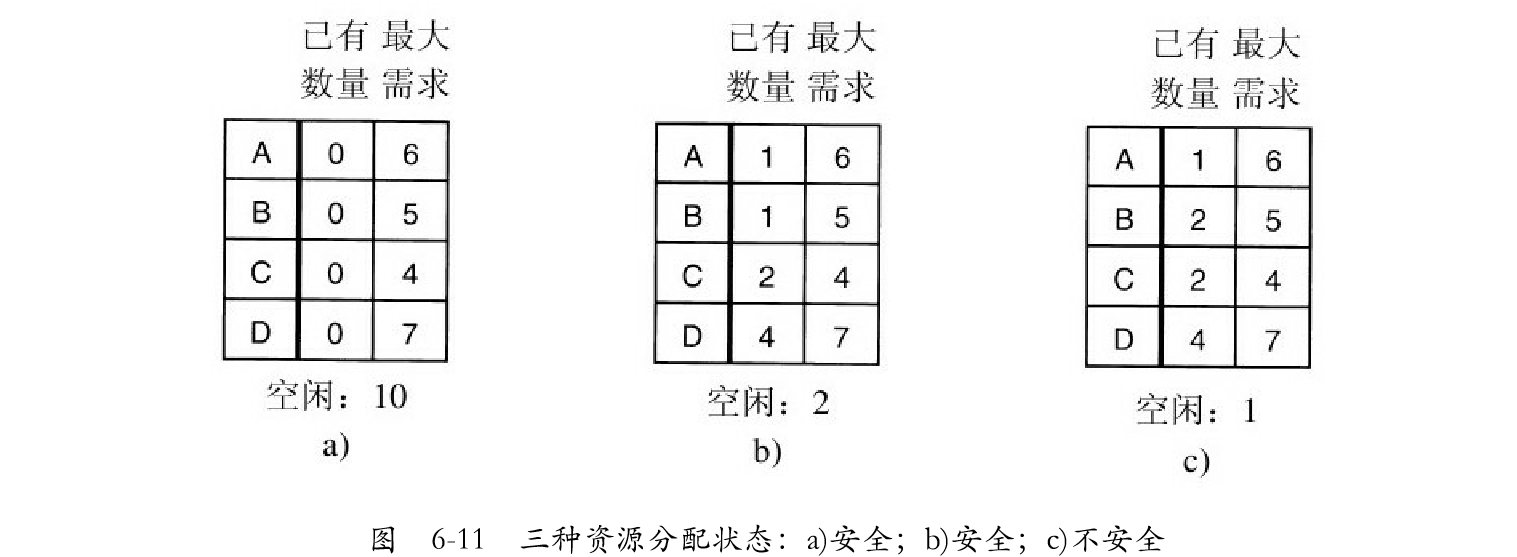
在某一时刻,具体情况如图6-11b所示。这个状态是安全的,由于保留着2个单位,银行家能够拖延除了C以外的其他请求。因而可以让C 先完成,然后释放C所占的4个单位资源。有了这4个单位资源,银行家就可以给D或B分配所需的贷款单位,以此类推。
考虑假如向B提供了另一个他所请求的贷款单位,如图6-11b所示,那么我们就有如图6-11c所示的状 态,该状态是不安全的。如果忽然所有的客户都请求最大的限额,而银行家无法满足其中任何一个的要求,那么就会产生死锁。不安全状态并不一定引起死锁,由于客户不一定需要其最大贷款额度,但银行家不敢抱这种侥幸心理。
银行家算法就是对每一个请求进行检查,检查如果满足这一请求是否会达到安全状态。若是,那么就满足该请求;若否,那么就推迟对这一请求的满足。为了看状态是否安全,银行家看他是否有足够的资源满足某一个客户。如果可以,那么这笔投资认为是能够收回的,并且接着检查最接近最大限额的一个客户,以此类推。如果所有投资最终都被收回,那么该状态是安全的,最初的请求可以批准。
-
多个资源的银行家算法
可以把银行家算法进行推广以处理多个资源。图6-12说明了多个资源的银行家算法如何工作。 在图6-12中我们看到两个矩阵。左边的矩阵显示出为5个进程分别已分配的各种资源数,右边的矩阵显示了使各进程完成运行所需的各种资源数。这些矩阵就是图6-6中的C和R。和一个资源的情况一样,各进程在执行前给出其所需的全部资源量,所以在系统的每一步中都可以计算出右边的矩阵。
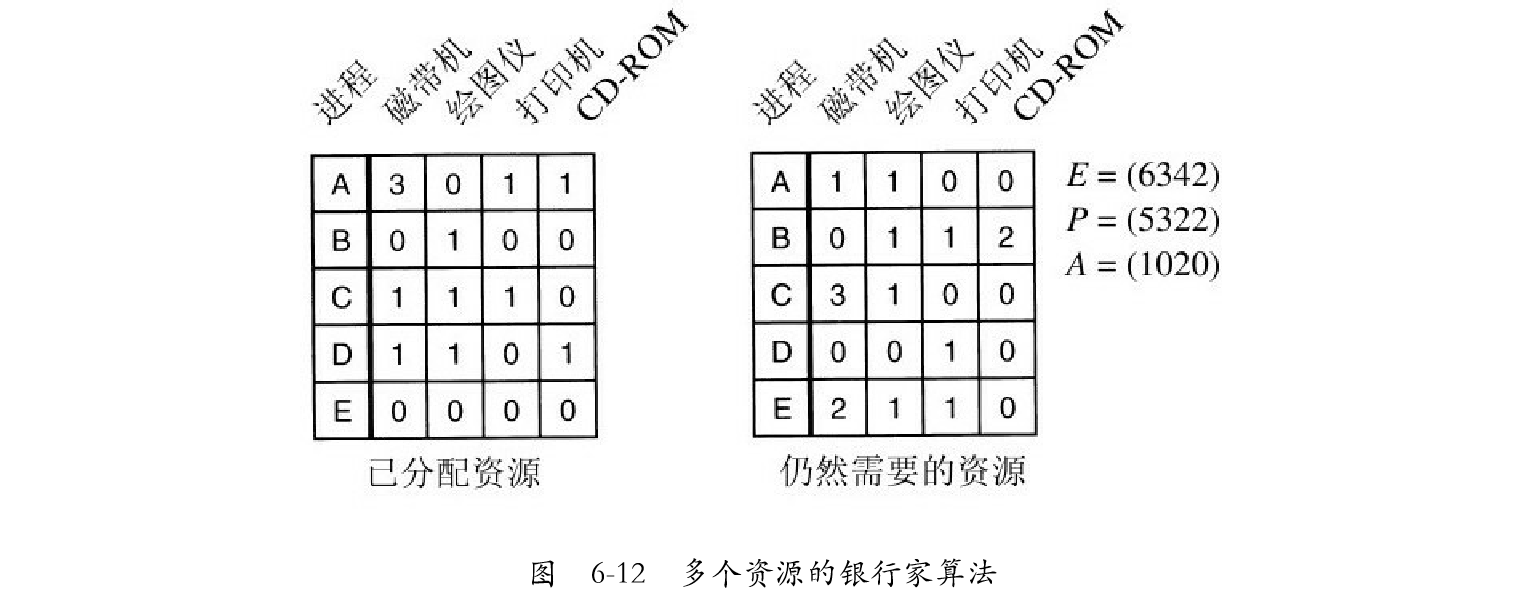
图6-12最右边的三个向量分别表示现有资源E、已分配资源P和可用资源A。由E可知系统中共有6台磁带机、3台绘图仪、4台打印机和2台CD-ROM驱动器。由P可知当前已分配了5台磁带机、3台绘图仪、2台打印机和2台CD-ROM驱动器。该向量可通过将左边矩阵的各列相加获得,可用资源向量可通过从现有资源中减去已分配资源获得。
检查一个状态是否安全的算法如下: 1)查找右边矩阵中是否有一行,其没有被满足的资源数均小于或等于A。如果不存在这样的行,那么系统将会死锁,因为任何进程都无法运行结束(假定进程会一直占有资源直到它们终止为止)。 2)假若找到这样一行,那么可以假设它获得所需的资源并运行结束,将该进程标记为终止,并将其资源加到向量A上。 3)重复以上两步,或者直到所有的进程都标记为终止,其初始状态是安全的;或者所有进程的资源需求都得不到满足,此时就是发生了死锁。
-
银行家算法的意义与缺点
该算法虽然很有意义但缺乏实用价值,因为很少有进程能够在运行前就知道其所需资源的最大值。而且进程数也不是固定的,往往在不断地变化(如新用户的登录或退出),况且原本可用的资源也可能突然间变成不可用(如磁带机可能会坏掉)。因此,在实际中,如果有,也只有极少的系统使用银行家算法来避免死锁。
死锁避免从本质上来说是不可能的,因为它需要获知未来的请求,而这些请求是不可预知的。
策略四:破坏死锁条件
解决死锁的方法即破坏上述四个条件之一,主要方法如下:
-
破坏互斥条件
如果资源不被一个进程所独占,那么死锁肯定不会产生。当然,允许两个进程同时使用打印机会造成混乱,通过采用假脱机打印机(spooling printer)技术可以允许若干个进程同时产生输出。该模型中惟一真正请求使用物理打印机的进程是打印机守护进程,由于守护进程决不会请求别的资源,所以不会因打印机而产生死锁。
-
破坏占有和等待条件
只要禁止已持有资源的进程再等待其他资源便可以消除死锁。一种实现方法是规定所有进程在开始执行前请求所需的全部资源。如果所需的全部资源可用,那么就将它们分配给这个进程,于是该进程肯定能够运行结束。如果有一个或多个资源正被使用,那么就不进行分配,进程等待。
这种方法的一个直接问题是很多进程直到运行时才知道它需要多少资源。实际上,如果进程能够知道它需要多少资源,就可以使用银行家算法。另一个问题是这种方法的资源利用率不是最优的。例如,有一个进程先从输入磁带上读取数据,进行一小时的分析,最后会写到输出磁带上,同时会在绘图仪上绘出。如果所有资源都必须提前请求,这个进程就会把输出磁带机和绘图仪多控制住一小时。
(但一些大型机批处理系统要求用户在所提交的作业的第一行列出它们需要多少资源。然后,系统立即分配所需的全部资源,并且直到作业完成才回收资源。虽然这加重了编程人员的负担,也造成了资源的浪费,但这的确防止了死锁。)
另一种破坏占有和等待条件的方案是,要求当一个进程请求资源时,先暂时释放其当前占用的所有资源,然后再尝试一次获得所需的全部资源。
-
破坏不可抢占条件
通过虚拟化的方式可以消除一些资源的死锁,如打印机。假脱机打印机向磁盘输出,并且只允许打印机守护进程访问真正的物理打印机,这种方式可以消除涉及打印机的死锁,然而却可能带来由磁盘空间导致的死锁。但是对于大容量磁盘,要消耗完所有的磁盘空间一般是不可能的。
然而,并不是所有的资源都可以进行类似的虚拟化。例如,数据库中的记录或者操作系统中的表都必须被锁定,因此存在出现死锁的可能。
-
消除环路等待条件
消除环路等待有几种方法。
一种是保证每一个进程在任何时刻只能占用一个资源,如果要请求另外一个资源,它必须先释放第一个资源。但假若进程正在把一个大文件从磁带机上读入并送到打印机打印,那么这种限制是不可接受的。
另一种避免出现环路等待的方法是将所有资源统一编号,现在的规则是:进程可以在任何时刻提出资源请求,但是所有请求必须按照资源编号的顺序(升序)提出。若按此规则,资源分配图中肯定不会出现环。
缺点:尽管对资源编号的方法消除了死锁的问题,但几乎找不出一种使每个人都满意的编号次序。当资源包括进程表项、假脱机磁盘空间、加锁的数据库记录及其他抽象资源时,潜在的资源及各种不同用途的数目会变得很大,以至于使编号方法根本无法使用。
21. 说一下操作系统中的结构体对齐,字节对齐
为什么需要字节对齐?
- 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次。
22. 怎么理解操作系统里的内存碎片,有什么解决办法?
内存碎片分为:内部碎片和外部碎片。
-
内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;
内部碎片是处于区域内部或页面内部的存储块。占有这些区域或页面的进程并不使用这个存储块。而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。(比如分页模式下的一个程序的最后一个页面,可能只使用页面的前一小部分)
-
外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。外部碎片是出于任何已分配区域或页面外部的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。
单道连续分配只有内部碎片。多道固定连续分配既有内部碎片,又有外部碎片。
使用伙伴系统算法。
23. 说一下用户模式和内核模式
不同的模式可以限制一个应用可以执行的指令以及它可以访问的地址空间范围。
处理器通常借助某个控制寄存器的一个模式位(mode bit)来提供这种功能。
- 当设置了模式位,进程就运行在内核模式中。这时该进程可以执行指令集中的任何指令,可以访问系统中的任何内存位置
- 没有设置模式位时,进程运行在用户模式。不可以执行特权指令,如停止处理器、改变模式位或者发起一个I/O操作。不可以访问地址空间中内核区的代码和数据。但是可以通过系统调用接口间接访问。
进程从用户模式变为内核模式的唯一方法是通过诸如中断、故障、或者陷入系统调用这样的异常。当异常发生时,控制传递到异常处理程序,处理器将程序从用户模式改为内核模式,使得处理程序运行在内核模式中。当它返回到应用程序代码时,处理器就把内核模式改回用户模式。
24. 说一下比莱蒂异常
Belady异常,在虚拟内存中,增加物理页面数而缺页次数反而增加的异常现象叫做比莱蒂异常。
应对策略是继续增加物理页面数,直到该现象消失为止或者直接改变页面替换算法。
注意:只有FIFO算法会产生Belady异常。
25. 说一下页式、段式、段页式内存管理
25.1 页式内存管理
页式内存管理是将物理内存用作物理磁盘的高速缓存,高速缓存与磁盘之间数据交换的单位就是页面。页面是固定大小的一个存储区域。程序存储在磁盘上,当程序运行时,必要的部分被加载到内存中,当然是分页加载,CPU首先在内存中找对应的页面,但是一开始内存中肯定没有,因此发生缺页中断,然后再从磁盘得到对应页面放入物理内存对应的页面,最后CPU才从物理内存读取页面数据。
CPU读取的是一个虚拟地址,分为页面号和页面偏移值两部分,页面号用于找到数据在物理内存的对应页面首地址,页面偏移值用于在对应页面内确定物理地址。由页面号找到物理内存中对应页面的方法是使用一个叫做页表的数据结构,页表中存放的是虚拟页面到物理页面的映射,页表还可以判断一个页面是否已经存在于物理内存中。如果页表中表项过多,也可以采用多级页表,将顶级页表常驻于内存。
25.2 段式内存管理
将一个程序分成多个段,每个段都独享一个虚拟地址空间,即每个段可能拥有相同的虚拟地址,但是由于段号不同,映射到的物理内存自然也不同。和页式管理类似,段式内存管理也有一个重要的数据结构,那就是段表,段表是存储虚拟段号到该段所在物理段的首地址的映射。
25.3 段页式内存管理
段页式管理就是将程序分为多个逻辑段,在每个段里面又进行分页,即将分段和分页组合起来使用。这样做 的目的就是想同时获得分段和分页的好处。
由于段页式管理模式是在段里面分页,而每个段占据一个虚地址空间,这就意味着一个程序将对应多个页 表。那么一个程序如何管理多个页表呢?简单!由段号在段表里面获得所应该使用的页表,然后在该页表里面查找物理页面号。
注意:段号不占用虚拟地址空间位数!如何实现:使用单独的寄存器来存放段号,或者将段号隐含在指令操作码里,即每条指令都隐含了自己到底属于哪一个逻辑段。
26. 说一下内存抖动
在更换页面时,如果更换的页面是一个很快就会被再次访问的页面,则在此次缺页中断后很快又会发生新的 缺页中断。在最坏情况下,每次新的访问都是对一个不在内存的页面进行访问,即每次内存访问都产生一次缺页中断,这样每次内存访问皆变成一次磁盘访问,而由于磁盘访问速度比内存慢了将近一百万倍,因此整个系统的效率急剧下降。这种现象就称为内存抖动,或者抽打、抽筋(tras-hing)。
- 如果是因为页面替换策略失误,当然可以修改替换算法来解决这个问题
- 如果是因为运行的程序太多,造成至少一个程序无法同时将所有频繁访问的页面调入内存,则需要降低多道编程的度数。通过减少同时运行的程序个数而使得每个程序都有足够的资源来运行而不产生抖动
27. 说一下进程和线程,区别,哪个效率高,为什么
进程与线程的选择取决于以下几点:
- 需要频繁创建销毁的优先使用线程;因为对进程来说创建和销毁一个进程代价是很大的。
- 线程的切换速度快,所以在需要大量计算,切换频繁时用线程,还有耗时的操作使用线程可提高应用程序的响应
- 因为对CPU系统的效率使用上线程更占优,所以可能要发展到多机分布的用进程,多核分布用线程;
- 并行操作时使用线程,如C/S架构的服务器端并发线程响应用户的请求;
- 需要更稳定安全时,适合选择进程;需要速度时,选择线程更好。
28. epoll 是否是线程安全的
epoll 是线程安全的。epoll是通过锁来保证线程安全的, epoll中粒度最小的自旋锁ep->lock(spinlock)用来保护就绪的队列, 互斥锁ep->mtx用来保护epoll的重要数据结构红黑树
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
struct eventpoll{ .... /*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/ struct rb_root rbr; /*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/ struct list_head rdlist; .... };
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。
当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
通过红黑树和双链表数据结构,并结合回调机制,造就了epoll的高效。
29. 说一下线程安全
定义
在拥有共享数据的多条线程并行执行的程序中,线程安全的代码会通过同步机制保证各个线程都可以正常且正确的执行,不会出现数据污染等意外情况。 ——百度百科
多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他操作,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。
线程安全问题大多是由全局变量及静态变量引起的,局部变量逃逸也可能导致线程安全问题。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
——百度百科
意义
线程安全, 是指变量或方法( 这些变量或方法是多线程共享的) 可以在多线程的环境下被安全有效的访问。这说明了两方面的问题:
(1)可以从多个线程中调用, 无需调用方有任何操作;
(2)可以同时被多个线程调用, 无需线程之不必要的交互。
30. 说一下自旋锁
概念
何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。
——百度百科
原理
跟互斥锁一样,一个执行单元要想访问被自旋锁保护的共享资源,必须先得到锁,在访问完共享资源后,必须释放锁。如果在获取自旋锁时,没有任何执行单元保持该锁,那么将立即得到锁;如果在获取自旋锁时锁已经有保持者,那么获取锁操作将自旋在那里,直到该自旋锁的保持者释放了锁。由此我们可以看出,自旋锁是一种比较低级的保护数据结构或代码片段的原始方式,这种锁可能存在两个问题:
- 死锁。试图递归地获得自旋锁必然会引起死锁:递归程序的持有实例在第二个实例循环,以试图获得相同自旋锁时,不会释放此自旋锁。在递归程序中使用自旋锁应遵守下列策略:递归程序决不能在持有自旋锁时调用它自己,也决不能在递归调用时试图获得相同的自旋锁。此外如果一个进程已经将资源锁定,那么,即使其它申请这个资源的进程不停地疯狂“自旋”,也无法获得资源,从而进入死循环。
- 过多占用cpu资源。如果不加限制,由于申请者一直在循环等待,因此自旋锁在锁定的时候,如果不成功,不会睡眠,会持续的尝试,单cpu的时候自旋锁会让其它process动不了. 因此,一般自旋锁实现会有一个参数限定最多持续尝试次数. 超出后, 自旋锁放弃当前time slice. 等下一次机会。
优点
- 自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快
- 非自旋锁在获取不到锁的时候会进入阻塞状态,从而进入内核态,当获取到锁的时候需要从内核态恢复,需要线程上下文切换。 (线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能)
31. 多线程可以访问其它线程的栈空间吗?
可以,但没必要,这很危险,有可能破坏栈的结构,让这个线程出现严重的错误。
一个进程内部的所有线程都共享该进程的地址空间,因此互相访问没有阻碍。
内存模型有很多种,Windows和Linux(以及大多数操作系统)使用的都是平坦模型,这种模式下,整个地址空间都是对任务可见的。换句话任意线程都可以访问用户空间的任意地址,不管这个地址是属于某个线程的线程栈,还是属于其它内存区域。
线程之间不存在任何的隔离手段,地址空间的隔离只发生在进程与进程之间。
所谓“新开一条线程”,实质上就是另外申请了一块内存,然后把这块内存当作堆栈,维护另外一条函数调用链。
而所谓“线程获得执行权”呢,实质上就是把对应线程的栈顶指针等信息载入CPU的栈指示器,使得它沿着这条调用链继续执行下去,执行一段时间,把它的栈顶指针等信息找个地方保存、然后载入另一个线程的栈顶指针等信息,这就是所谓的“线程切换”。
线程和进程的区别就在于,线程只有调用链,而进程还包含常量区、全局变量区等其他区域,同时还有各种资源的所有权。
换句话说,操作系统认为,诸如动态申请内存、内核对象等各种资源,哪怕是在某个线程里面申请的,它的所有权仍然属于进程所有——所以,线程退出除了会清理调用链信息外,并不释放其他资源;而进程退出就会自动归还它申请的各种资源(某些特殊资源除外:并不能盲目认为一旦进程退出一切就会变回原样)。
1、所有线程都是在各自独立的栈区维护的调用链(以及执行现场)
2、线程局部变量处于各自所属的栈区
3、不允许跨线程直接传递局部变量的引用/指针,因为它们随时可能失效
这点一定要注意。和单线程程序不同,跨线程传递局部变量指针给被调用者是没有丝毫保障的;传了,就一定会出事!
4、线程中取得的、进程生存期有效的资源,要么直接/间接挂载到全局变量/全局静态变量上,要么就一定要在线程结束前释放。不然就会造成资源泄露(搜索不被全局变量和局部变量索引的内存并主动释放,这正是垃圾回收的原理)。
5、线程由谁启动这个信息并不在调用链上。换句话说,所有线程都是平等的,它们各自独立使用自己的专属栈区(但主线程较为特殊,大多实现中,它的退出就意味着进程结束;除此之外,它们是平等的)。
作者:invalid s 链接:https://www.zhihu.com/question/323415592/answer/676335264 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
32. 说一下虚拟技术
虚拟技术把一个物理实体转换为多个逻辑实体。
主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
33. 说一下中断
外中断
由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求。此外还有时钟中断、控制台中断等。
异常
由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
陷入
在用户程序中使用系统调用。
34. 说一下进程调度算法
不同环境的调度算法目标不同,因此需要针对不同环境来讨论调度算法。
1. 批处理系统
批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
1.1 先来先服务 first-come first-serverd(FCFS)
非抢占式的调度算法,按照请求的顺序进行调度。
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
1.2 短作业优先 shortest job first(SJF)
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
1.3 最短剩余时间优先 shortest remaining time next(SRTN)
最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
2. 交互式系统
交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
2.1 时间片轮转
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:
- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
- 而如果时间片过长,那么实时性就不能得到保证。
2.2 优先级调度
为每个进程分配一个优先级,按优先级进行调度。
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
2.3 多级反馈队列
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,..。进程在第一个队列没执行完,就会被移到下一个队列。这种方式下,之前的进程只需要交换 7 次。
每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
3. 实时系统
实时系统要求一个请求在一个确定时间内得到响应。
分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
35. 使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}
36. 说一下Linux中进程状态
| 状态 | 说明 |
|---|---|
| R | running or runnable (on run queue) 正在执行或者可执行,此时进程位于执行队列中。 |
| D | uninterruptible sleep (usually I/O) 不可中断阻塞,通常为 IO 阻塞。 |
| S | interruptible sleep (waiting for an event to complete) 可中断阻塞,此时进程正在等待某个事件完成。 |
| Z | zombie (terminated but not reaped by its parent) 僵死,进程已经终止但是尚未被其父进程获取信息。 |
| T | stopped (either by a job control signal or because it is being traced) 结束,进程既可以被作业控制信号结束,也可能是正在被追踪。 |
| I | 空闲状态(idle) |
37. 说一下操作系统中的缓存
一般来说高速缓存(cache,读作cash)是一个小而快速的存储设备。它作为存储在更大、也更慢的设备中的数据对象的缓冲区域。使用高速缓存的过程称为缓存(caching,读作cashing)。
如果按照容量以及速度来将存储器划分为不同层级,那么存储器层次结构中的每一层都缓存来自较低一层(容量更大、速度更慢)的数据对象。例如,本地磁盘作为通过网络从远程磁盘取出文件的缓存,主存作为本地磁盘上数据的缓存,依此类推,直到最小的缓存——CPU寄存器组。
计算机网络
1. 说一下网络五层or七层
TCP/IP模型原为四层,五层模型是TCP/IP四层模型和OSI七层模型混合后的产物。
实际五层
(1)应用层
支持不同的网络应用,应用协议仅仅是网络应用的一个组成部分,运行在不同主机上的进程则使用应用层协议进行通信。主要的协议有:http、ftp、telnet、smtp、pop3等。
(2)传输层
负责为信源和信宿提供应用程序进程间的数据传输服务,这一层上主要定义了两个传输协议,传输控制协议即TCP和用户数据报协议UDP。工作在此层的设备有四层路由器、四层交换机等。
(3)网络层
负责将数据报(datagram)独立地从信源发送到信宿,主要解决路由选择、拥塞控制和网络互联等问题。工作在此层的设备有路由器、三层交换机等。
(4)数据链路层
负责将IP数据报封装成合适在物理网络上传输的帧格式,或将从物理网络接收到的帧解封,取出IP数据报交给网络层。工作在此层的设备有网桥、网卡、以太网交换机等。
(5)物理层
负责将比特流在结点间传输,即负责物理传输。该层的协议既与链路有关也与传输介质有关。工作在此层的设备有中继器、集线器、双绞线等。
OSI模型七层
OSI(Open System Interconnection)模型有7层结构,每层都可以有几个子层。 OSI的7层从上到下分别是 7 应用层 6 表示层 5 会话层 4 传输层 3 网络层 2 数据链路层 1 物理层 ;其中高层(即7、6、5、4层)定义了应用程序的功能,下面3层(即3、2、1层)主要面向通过网络的端到端,点到点的数据流。
各层功能
7 应用层(Application)
与其它计算机进行通讯的一个应用,它是对应应用程序的通信服务的。是允许访问OSI环境的手段,传输单位为APDU,主要包括的协议为 TELNET,HTTP,FTP,NFS,SMTP等。
6 表示层(Presentation)
这一层的主要功能是定义数据格式及加密。对数据进行翻译、加密和压缩,传输单位为PPDU,主要包括的协议为JPEG ASII
5 会话层(Session)
它定义了如何开始、控制和结束一个会话,传输单位为SPDU,主要包括的协议为RPC NFS
4 传输层(Transport)
提供端到端的可靠报文传递和错误恢复,传输单位为报文,主要包括的协议为TCP UDP
3 网络层(Network)
负责数据包从源到宿的传递和网际互连,传输单位为包,主要包括的协议为IP ARP ICMP
2 数据链路层(Data Link)
它定义了在单个链路上如何传输数据。将比特组装成帧和点到点的传递,传输单位为帧,主要包括的协议为MAC VLAN PPP
1 物理层(Physical)
物理层: 通过媒介传输比特,确定机械及电气规范,传输单位为bit,主要包括的协议为:IEE802.3 CLOCK RJ45
网络数据流协议图
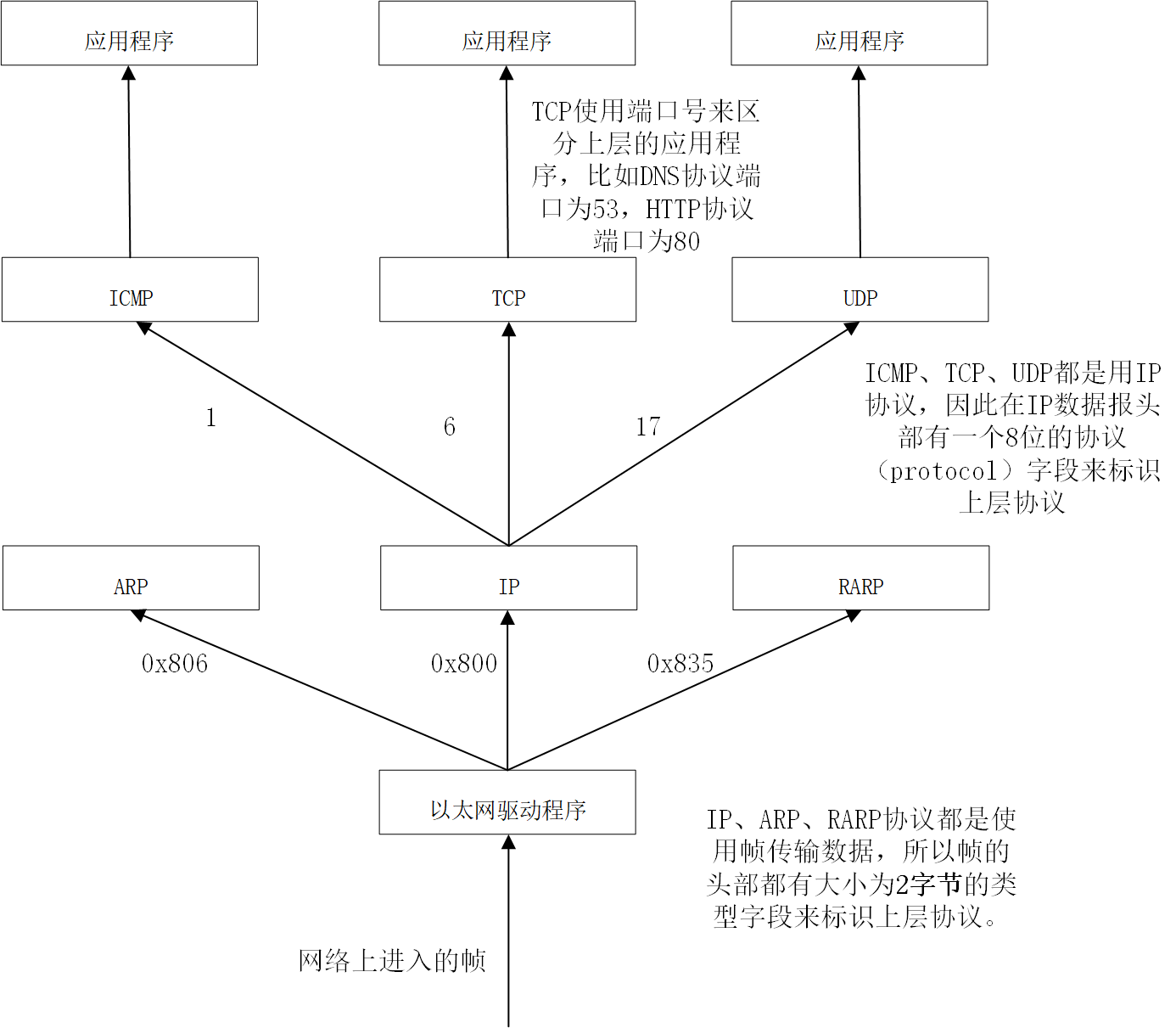
2. 说一下TCP和UDP有什么区别
TCP协议报文格式:
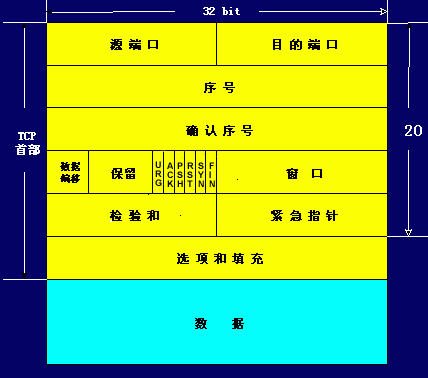
UDP协议报文格式:

TCP—传输控制协议,提供的是面向连接、可靠的字节流服务(基于流的数据没有长度限制,数据源源不断地从一端流向另一端)。
- 当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。
- TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP—用户数据报协议,是一个简单的面向数据报的运输层协议,为应用层提供不可靠、无连接和基于数据报的服务。
- UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。
- 由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快
- 每个UDP数据报都有一个长度,接收端必须以该长度为最小单位将其所有内容一次性读出,否则数据将被截断。
3. 说一下编写socket套接字的步骤
sockets(套接字)编程有三种,流式套接字(SOCK_STREAM),数据报套接字(SOCK_DGRAM),原始套接字(SOCK_RAW);基于TCP的socket编程是采用的流式套接字。基于UDP的socket编程是采用的数据报套接字。
TCP
服务器端程序的编写步骤:
- 创建套接字描述符(socket)。
- 设置服务器的IP地址和端口号(需要转换为网络字节序的格式)。
- 将套接字描述符绑定到服务器地址(bind)。
- 调用listen()函数使套接字成为一个监听套接字。
- 调用accept()函数来接受客户端的连接,这时返回一个新的socket,利用新的socket就可以和客户端通信了。
- 处理客户端的连接请求(send() and recv())。
- 终止连接,继续监听。
客户端程序编写步骤:
- 创建套接字描述符(socket)。
- 设置服务器的IP地址和端口号(需要转换为网络字节序的格式)。
- 调用connect()函数来建立与服务器的连接。
- 调用读写函数发送或者接收数据(send()/recv())。
- 断开连接,关闭套接字描述符(close)。
UDP
服务器端程序的编写步骤:
- 创建套接字描述符。
#int mysocket = socket(AF_INET,SOCK_DGRAM,0);- 设置服务器的IP地址和端口号(需要转换为网络字节序的格式)。
- 将套接字描述符绑定到服务器地址(bind)。
- 处理客户端的连接请求(recvfrom()/sendto())
客户端程序的编写步骤:
- 创建套接字描述符(socket)。
- 设置服务器的IP地址和端口号(需要转换为网络字节序的格式)。
- 调用读写函数发送或者接收数据(sendto()/recvfrom())。
- 断开连接,关闭套接字描述符(close)。
4. 说一下TCP三次握手和四次挥手, 以及各个状态的作用
三次握手
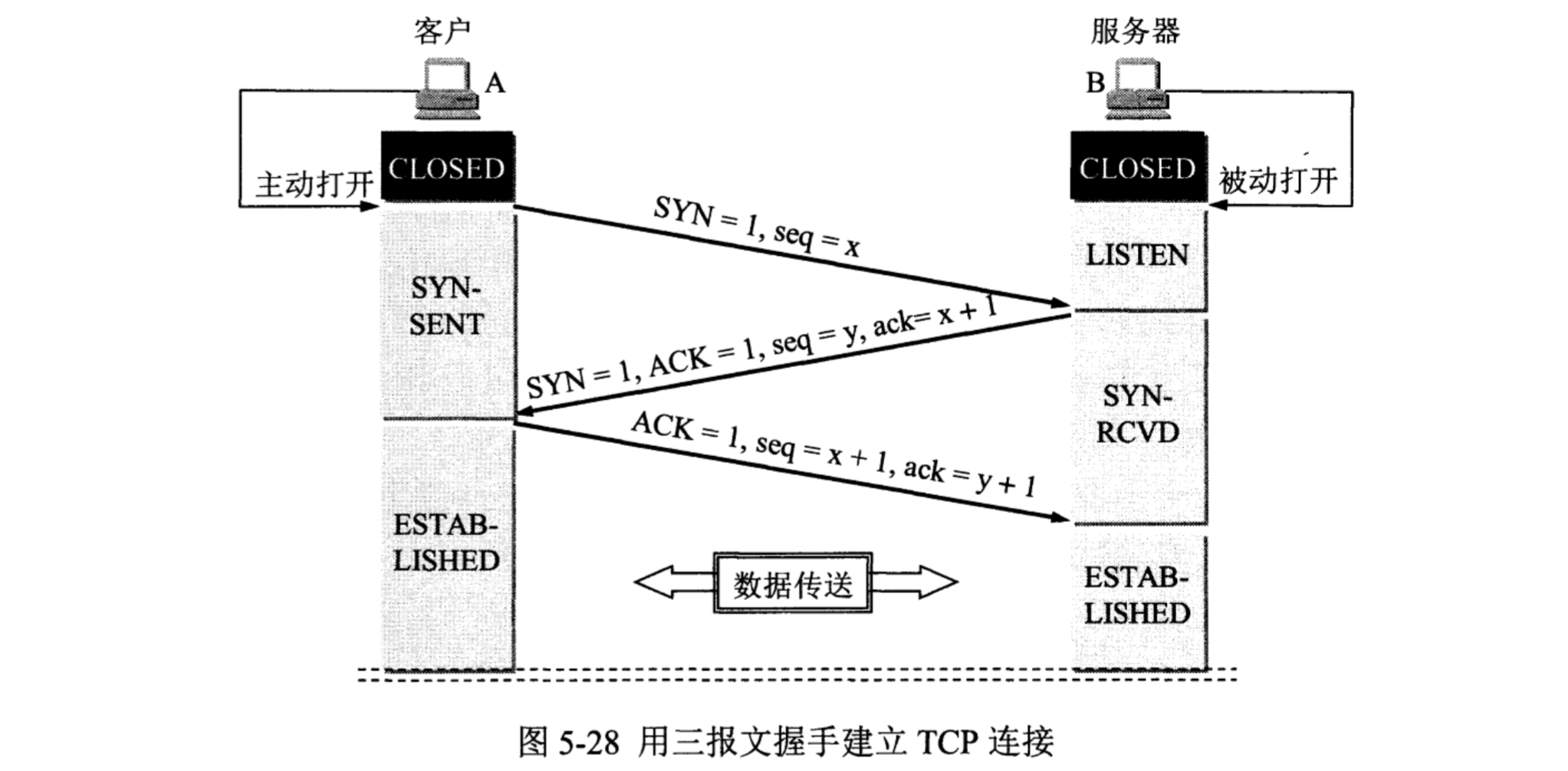
- 服务端的TCP进程先创建传输控制块TCB,然后服务器的TCP进程就处于LISTEN监听状态,等待客户端的连接请求
- 客户端的TCP进程创建传输控制块TCB,随机选择一个初始序号seq=x,向服务端发出请求报文段,报文段中的SYN=1(TCP规定SYN=1的报文段不能携带数据,但要消耗一个序号),然后客户端的TCP进程进入SYN-SENT(SYN已发送)状态
- 服务端收到客户端的TCP连接请求后,随机选择一个初始序号seq=y,发送一个确认报文段,其中SYN、ACK都置1(该报文段也不能携带数据,但消耗一个序号),确认序号是ack=x+1,然后服务端进入SYN-RCVD(SYN已收到)状态
- 客户端的TCP进程收到服务端的确认连接后,还要向服务端给出确认,确认报文段的ACK标志位置1(该报文段可以携带数据,如果不携带数据则不消耗序号),确认序号ack=y+1,自己的序号为seq=x+1,这时TCP连接已经建立,客户端进入ESTABLISHED(已连接)状态
- 服务端收到客户端的确认后,也进入ESTABLISHED(已连接)状态
上述三次握手的第二次握手,也就是服务器的确认报文段可以拆分成两个报文段,即先发送一个确认报文段(ACK=1, ack=x+1),再发送一个同步报文段(SYN=1, seq=y),这样就变成了四次握手了,效果是一样的。
为什么客户端最后还要再发送一次确认呢?一问一答不就可以建立连接了吗?这主要是为了防止已失效的连接请求报文段突然到达服务端而产生错误。具体情况:
客户端发送的第一个TCP请求报文段由于没有到达服务端,因此客户端收不到服务端的确认,超时后客户端再次发送一个TCP请求,这次成功达到服务端并建立连接,完成通讯后断开连接。现在问题来了,客户端发送的第一个请求报文段此时晚点到达了服务端,服务端就会把它当作一次新的请求,于是回复确认报文,此时如果只是两次握手,那么连接就此建立。由于客户端并没有发出新的请求,因此不会理睬服务端的确认,也不会向服务端发送数据。但服务端却私以为TCP连接已经建立,就一直等待客户端发来数据,于是服务端就浪费了大量资源。
四次挥手
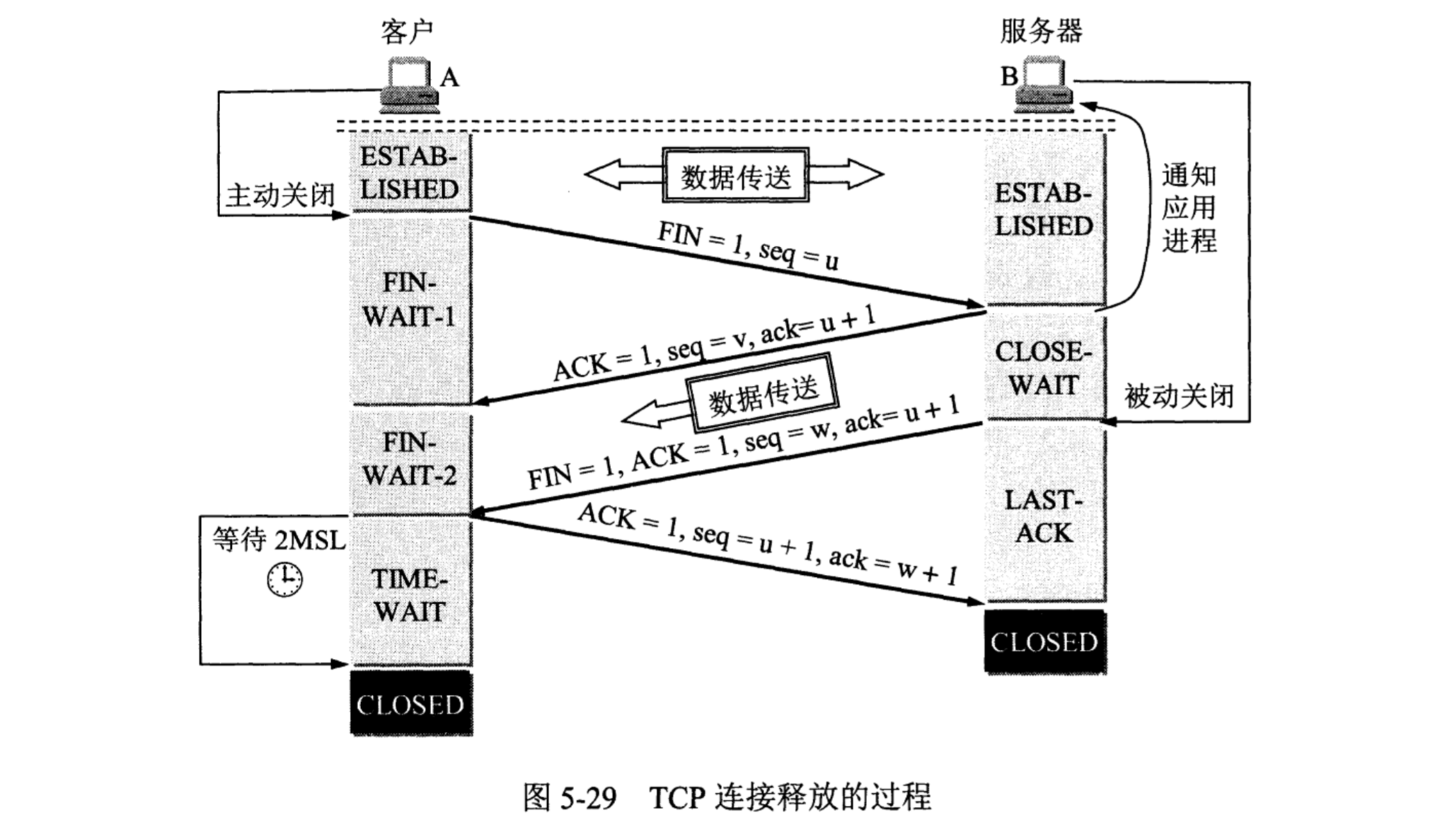
TCP连接的双方都可以断开连接,但一般是客户端断开连接居多。一开始客户端和服务端都处于ESTABLISHED状态。
-
客户端停止发送数据,并向服务端发送连接释放报文段请求断开连接。其中报文段首部FIN标志位置1(TCP规定FIN报文段即使不携带数据也要消耗一个序号),发送序号为seq=u,它等于前面已发送数据的最后一个字节的序号加1,然后进入FIN-WAIT-1(终止等待1)状态。
-
服务端收到客户端的断开连接请求后就发出确认报文段,确认号是ack=u+1,发送序号seq=v,它等于服务端前面已发送的数据的最后一个字节的序号加1,然后进入CLOSE-WAIT(关闭等待)状态。
此时的TCP连接已经处于半关闭(half-close)状态,即客户端已经不能发送数据了,但服务端还可以发送。若服务端继续发送数据,则客户端仍要接收。
-
客户端收到服务端发送的确认后,就进入FIN-WAIT-2状态,等待服务端发出连接释放报文段
-
服务端发送连接释放报文段,其中FIN标志位置1,发送序号为w(在半连接状态服务端可能又发送了一些数据),确认号还是ack=u+1,因为没有收到过客户端的数据。然后服务端就进入LAST-ACK(最后确认)状态,等待来自客户端的最后的确认。
-
客户端在收到服务端发送的连接释放报文段后,回复最后的确认报文段,其中ACK标志位置1,确认号ack=w+1,发送序号为seq=u+1。然后进入TIME-WAIT(时间等待)状态。
此时TCP连接还没有释放,必须经过时间等待计时器(TIME-WAIT timer) 设置的时间2MSL后,客户端才进入CLOSED状态,当客户端撤销了相应的传输控制块TCB后,就结束了此次的TCP连接。
最长报文段寿命(Maximum Segment Lifetime, MSL),RFC793建议设为2分钟,即MSL=2分钟,2MSL=4分钟。
-
服务端只要收到了客户端发出的确认,就进入CLOSED状态。同样服务端撤销了相应的传输控制块TCB后,就结束了此次的TCP连接。
为什么客户端在TIME-WAIT状态必须等待2MSL的时间呢?
第一,为了保证客户端发送的最后一个ACK报文段能到达服务端:
等待2MSL时间主要目的是怕最后一个 ACK包对方没收到,那么对方在超时后将重发第三次握手的FIN包,主动关闭端接到重发的FIN包后可以再发一个ACK应答包
第二,防止“已失效的连接请求报文段”出现在新的连接中:
客户端在发送完最后一个ACK确认报文段后,再经过时间2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。例如:一个新的连接刚好建立在当前关闭的端口之上(IP和端口都相同),如果没有2MSL的等待时间,那么新的连接很可能收到原来连接的应用程序数据。(可以通过socket的SO_REUSEADDR选项来强制进程立即使用处于time-wait状态的连接占用的端口)
这种2 M S L等待的另一个结果是这个 T C P连接在2 M S L等待期间,定义这个连接的插口 (客户的I P地址和端口号,服务器的 I P地址和端口号)不能再被使用。这个连接只能在 2 M S L 结束后才能再被使用。 遗憾的是,大多数 T C P实现(如伯克利版)强加了更为严格的限制。在 2 M S L等待期间, 插口中使用的本地端口在默认情况下不能再被使用。我们将在下面看到这个限制的例子。
保活计时器
除了时间等待计时器外,TCP还有一个保活计时器(keepalive timer)。在TCP连接过程中,如果客户端由于出现故障或其它原因导致不能收发消息,那么服务器就无法再收到客户端发来的消息了,但是服务器又不能一直等待,那会耗费大量资源。那么就需要用到保活计时器了。
保活计时器通常设置为2小时,服务器每次收到客户端发来的消息后就重置保活计时器。若两个小时没有收到客户端的消息,服务端就发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文段后仍无客户端的回应,服务端就认为客户端出现了故障,于是关闭连接。
TCP的有限状态机
实线表示客户端,虚线表示服务器端。
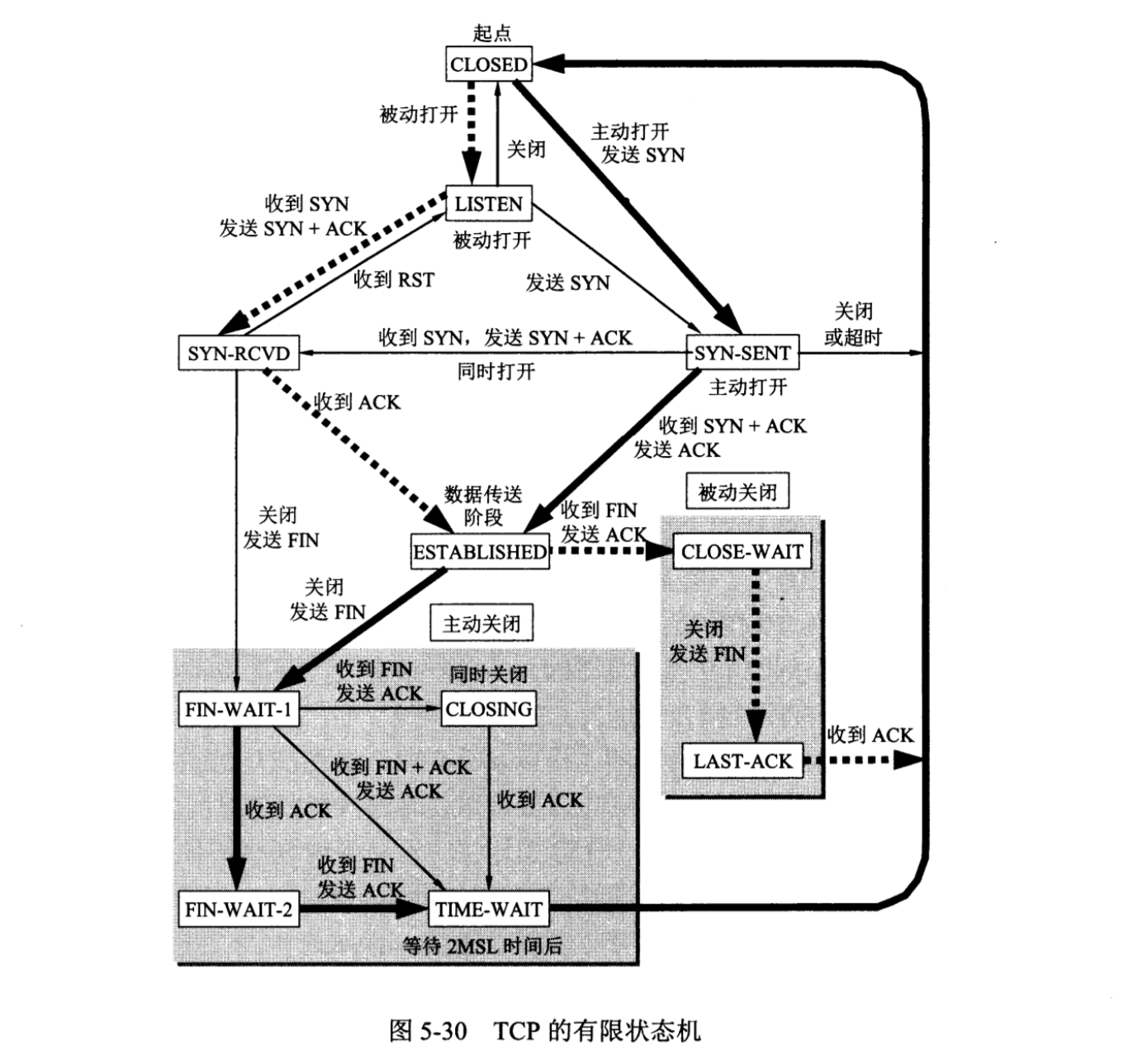
5. 说一下HTTP协议
http是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。
工作原理
HTTP是基于客户/服务器模式,且面向连接的。典型的HTTP事务处理有如下的过程:
(1)客户与服务器建立连接;
(2)客户向服务器提出请求;
(3)服务器接受请求,并根据请求返回相应的文件作为应答;
(4)客户与服务器关闭连接。
客户与服务器之间的HTTP连接是一种一次性连接,它限制每次连接只处理一个请求,当服务器返回本次请求的应答后便立即关闭连接,下次请求再重新建立连接。
HTTP是一种无状态协议,即服务器不保留与客户交易时的任何状态。
报文格式
请求报文格式:
请求行 - 通用信息头 - 请求头 - 实体头 - 报文主体
应答报文格式:
状态行 - 通用信息头 - 响应头 - 实体头 - 报文主体
请求方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | get | 请求指定的页面信息并返回实体主体 |
| 2 | head | 类似get,不过返回的响应无内容,用于获取报头 |
| 3 | post | 向指定资源提交数据(如提交表单或上传文件) |
| 4 | put | 从客户端向服务器传送的数据取代指定的文档的内容 |
| 5 | delete | 请求服务器删除指定的页面 |
| 6 | connect | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器 |
| 7 | options | 允许客户端查看服务器的性能 |
| 8 | trace | 回显服务器收到的请求,主要用于测试或诊断 |
| 9 | patch | 是对 PUT 方法的补充,用来对已知资源进行局部更新 |
状态码
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
6. 从浏览器输入 URL 到页面展示过程发生了什么?
参考:https://segmentfault.com/a/1190000022262262
一、解析输入
发生这个过程的前提,用户在地址栏中输入了 URL,而地址栏会根据用户输入,做出如下判断:
- 输入的是非
URL结构的字符串,则会用浏览器默认的搜索引擎搜索该字符串 - 输入的是
URL结构字符串,则会构建完整的URL结构,浏览器进程会将完整的URL通过进程间通信,即IPC,发送给网络进程
二、请求过程
在网络进程接收到 URL 后,并不是马上对指定 URL 进行请求。首先,我们需要进行 DNS 解析域名得到对应的 IP,然后通过 ARP 解析 IP 得到对应的 MAC(Media Access Control Address)地址。
DNS解析
DNS 解析域名的过程分为以下几个步骤:
- 询问浏览器
DNS缓存 - 询问本地操作系统
DNS缓存(即查找本地host文件) - 询问
ISP(Internet Service Provider)互联网服务提供商(例如电信、移动)的DNS服务器 - 询问根服务器,这个过程可以进行递归和迭代两种查找的方式,两者都是先询问顶级域名服务器查找
数据通信
-
建立
TCP连接(三次握手) - 数据传输:
- 服务端接收到数据包,并发送确认数据包已收到的消息到客户端,不断重复这个过程
- 客户端在发送一个数据包后,未接收到服务端的确定消息,则重新发送该数据包,即
TCP的重发机制 - 当接收完所有的数据包后,接收端会按照
TCP头中的需要进行排序,形成完整的数据
- 断开
TCP连接(四次挥手)
三、数据处理
当网络进程接收到的响应报文状态码,进行相应的操作。例如状态码为 200 OK 时,会解析响应报文中的 Content-Type 首部字段,例如我们这个过程 Content-Type 会出现 application/javascript、text/css、text/html,即对应 Javascript 文件、CSS 文件、HTML 文件。
创建渲染进程
当前需要渲染 HTML 时,则需要创建渲染进程,用于后期渲染 HTML。而对于渲染进程,如果是同一站点是可以共享一个渲染进程,例如 a.abc.com 和 c.abc.com 可以共享一个渲染渲染进程。否则,需要重新创建渲染进程
需要注意的是,同站指的是顶级域名和二级域名相等
开始渲染
在创建完渲染进程后,网络进程会将接收到的 HTML、JavaScript 等数据传递给渲染进程。而在渲染进程接收完数据后,此时用户界面上会发生这几件事:
- 更新地址栏的安全状态
- 更新地址栏的
URL - 前进后退此时
enable,显示正在加载状态 - 更新网页
渲染过程
- 解析
HTML生成DOM树 - 解析
CSS生成CSSOM - 加载或执行
JavaScript - 生成渲染树(
Render Tree) - 布局
- 分层
- 生成绘制列表
- 光栅化
- 显示
7. 说一下TCP怎么保证可靠性
1. 保证对方正确收到:超时重传(序列号+确认应答)
数据到达接收方,接收方需要发出一个确认应答,表示已经收到该数据段,并且确认序号会说明了它下一次需要接收的数据序列号。如果发送方迟迟未收到确认应答,那么可能是发送的数据丢失,也可能是确认应答丢失,这时发送方在等待一定时间后会进行重传。这个时间一般是2*RTT(报文段往返时间)+一个偏差值。重传后将新的重传时间设置为原来的两倍。
2. 保证对方收到有序:滑动窗口协议
滑动窗口指的是发送窗口(swnd)和接收方的接收窗口(rwnd)(区别于拥塞窗口cwnd),一般发送窗口等于接收窗口,在发送窗口内的TCP可以一次性发送出去以提高信道利用率。而接收方采用累积确认,即接收方也不必对收到的每个分组逐个发送确认,而是在收到几个分组后,对按序到达的最后一个分组发送确认。例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
发送窗口位置由窗口前沿和后沿的位置共同决定。后沿位置有不动(没有收到新的确认)和前移(收到新的确认)两种状态。而前沿比较复杂,一般是前移,也可能不动,也可能后移:
-
前沿位置不动
可能是没有收到新的确认,对方窗口大小也没有变化;也可能是收到了新的确认但是对方告诉的窗口变小了。使得发送窗口前沿刚好不动。
-
前沿位置后移(
TCP不建议,可能产生错误)对方告诉的窗口缩小了。
使用窗口控制,如果数据段1001-2000丢失,后面数据每次传输,确认应答都会不停地发送序号为1001的应答,表示我要接收1001开始的数据,发送端如果收到3次相同应答,就会立刻进行重发;但还有种情况有可能是数据都收到了,但是有的应答丢失了,这种情况不会进行重发,因为发送端知道,如果是数据段丢失,接收端不会放过它的,会疯狂向它提醒……
3. 拥塞控制(网络优化)
拥塞控制就是为了约束发送窗口的大小,因此定义了一个拥塞窗口,原则是只要网络没有阻塞拥塞窗口就可以一直增大,最终发送窗口大小为min(拥塞窗口,接收窗口)。
慢启动:拥塞窗口大小设置为1(单位为最大报文段SMSS(Sender Maximum Segment Size)的数值),每接收到一个确认,拥塞窗口的值增加量为N,其中N是现在刚刚确认的字节数。这样经过一个传输轮次后,拥塞窗口值就翻倍(1 2 4 8)。
拥塞避免:为了防止慢启动中拥塞窗口增长过大引起网络阻塞,设置了一个慢启动的门限ssthresh。当拥塞窗口大小小于该门限时,继续使用慢启动,当大于等于该门限时,则启用拥塞避免。拥塞避免就是每经过一个往返时间RTT后就将发送方的拥塞窗口增加一个单位(min(N, SMSS))
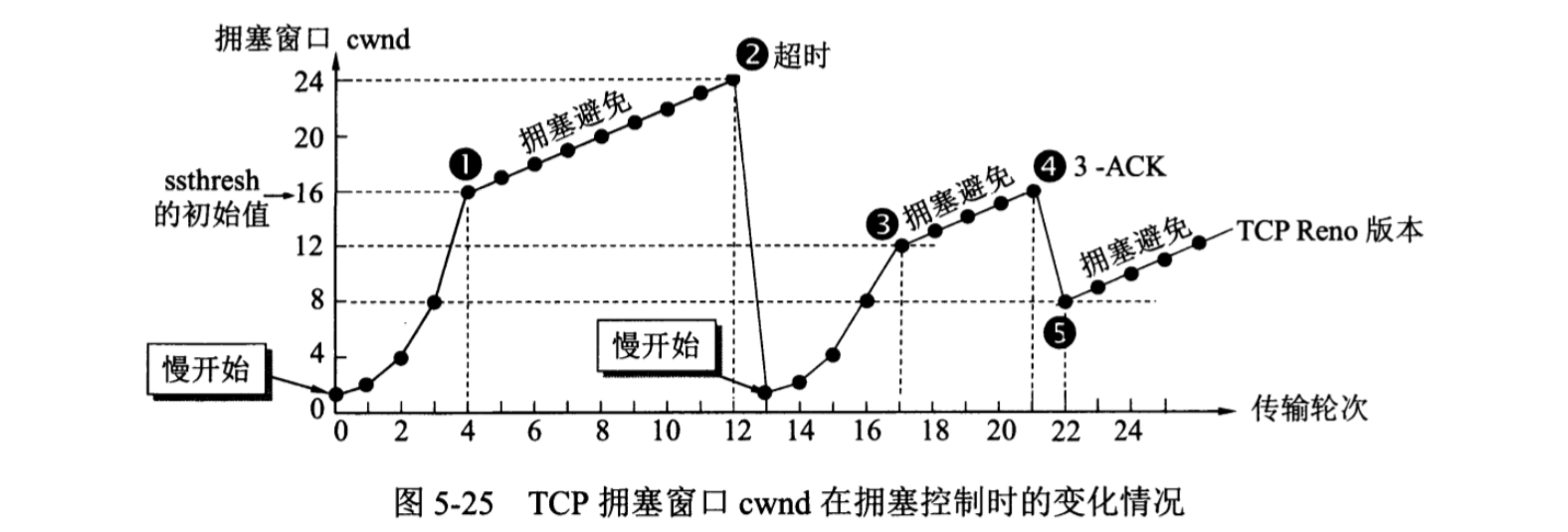
有了上面两个方案后,就可以根据具体情况来使用具体方案了:
超时:当出现超时时,发送方认定当前网络为拥塞,于是调整门限值ssthresh为当前拥塞窗口大小的一半,同时将拥塞窗口置1,重新开始慢启动
3-ACK(快重传):发送方一连收到3个对统一报文段的确认,就应当立即重传,并且调整门限值ssthresh 和拥塞窗口大小 为当前拥塞窗口大小的一半,直接进入拥塞避免状态。注意:快重传要求接收方不能等到自己要发送数据时才进行稍待确认,而是立即发送确认。
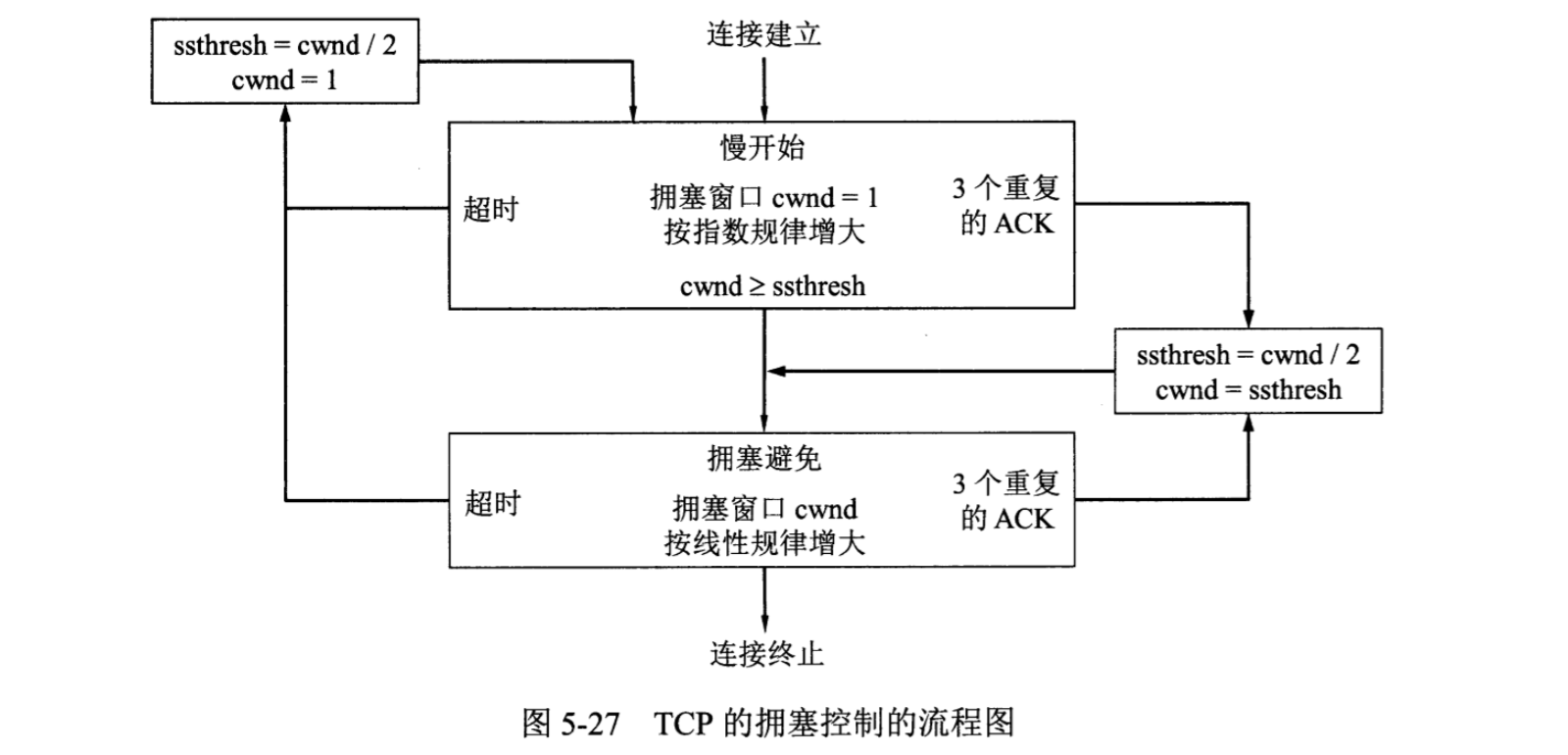
8. 说一下HTTP和HTTPS的不同
HTTPS = HTTP + 加密 + 认证 + 完整性检测
HTTP协议和HTTPS协议区别如下:
- 安全性方面:HTTP协议是以明文的方式在网络中传输数据,而HTTPS协议传输的数据则是经过TLS加密后的,HTTPS具有更高的安全性
- 协议方面:HTTPS在TCP三次握手阶段之后,还需要进行SSL 的handshake,协商加密使用的对称加密密钥
- HTTPS协议需要服务端申请证书,浏览器端安装对应的根证书
- HTTP协议端口是80,HTTPS协议端口是443
HTTPS优点:
-
HTTPS传输数据过程中使用密钥进行加密,所以安全性更高
-
HTTPS协议可以认证用户和服务器,确保数据发送到正确的用户和服务器
HTTPS缺点:
- HTTPS速度慢,握手阶段延时较高:由于在进行HTTP会话之前还需要进行SSL握手,会消耗大量CPU和内存资源
- HTTPS部署成本高:一方面HTTPS协议需要使用证书来验证自身的安全性,所以需要购买CA证书;另一方面由于采用HTTPS协议需要进行加解密的计算,占用CPU资源较多,需要的服务器配置高
9. 说一下MAC地址和IP地址各自的作用
MAC地址是一个硬件地址,用来定义网络设备的位置,主要由数据链路层负责。而IP地址是IP协议提供的一种统一的地址格式,为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
10. 说一下TCP/IP数据链路层的交互过程
数据包到达网络层准备往数据链路层发送的时候,首先会去自己的ARP缓存表(存着IP-MAC对应关系)去查找改目标IP的MAC地址,如果查到了,就将目标IP的MAC地址封装到链路层数据包的包头。如果缓存中没有找到,会发起一个广播:who is ip XXX tell ip XXX,所有收到广播的机器看这个IP是不是自己的,如果是自己的,则以单拨的形式将自己的MAC地址回复给请求的机器。
11. 传递到IP层怎么知道报文该给哪个应用程序,它怎么区分是UDP报文还是TCP报文
根据端口区分。看IP头中的协议标识字段,17是UDP,6是TCP
12. 说一下POST和GET的区别
概括
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
区别
- GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
- get参数通过url传递,post放在request body中(浏览器)。
- get请求在url中传递的参数是有长度限制的,而post没有(浏览器)。
- get比post更不安全,因为参数直接暴露在url中,所以不能用来传递敏感信息。
- get请求只能进行url编码,而post支持多种编码方式。
- get请求参数会被完整保留在浏览历史记录里,而post中的参数不会被保留。
- GET产生一个TCP数据包;POST产生两个TCP数据包(浏览器)。
13. 说一下数字证书是什么,里面都包含那些内容
13.1 概念:
数字证书是数字证书在一个身份和该身份的持有者所拥有的公/私钥对之间建立了一种联系,由认证中心(CA)或者认证中心的下级认证中心颁发的。根证书是认证中心与用户建立信任关系的基础。在用户使用数字证书之前必须首先下载和安装。
认证中心是一家能向用户签发数字证书以确认用户身份的管理机构。为了防止数字凭证的伪造,认证中心的公共密钥必须是可靠的,认证中心必须公布其公共密钥或由更高级别的认证中心提供一个电子凭证来证明其公共密钥的有效性,后一种方法导致了多级别认证中心的出现。
13.2 数字证书颁发过程:
数字证书颁发过程如下:用户产生了自己的密钥对,并将公共密钥及部分个人身份信息传送给一家认证中心。认证中心在核实身份后,将执行一些必要的步骤,以确信请求确实由用户发送而来,然后,认证中心将发给用户一个数字证书,该证书内附了用户和他的密钥等信息,同时还附有对认证中心公共密钥加以确认的数字证书。当用户想证明其公开密钥的合法性时,就可以提供这一数字证书。
13.3 内容:
数字证书的格式普遍采用的是X.509V3国际标准,一个标准的X.509数字证书包含以下一些内容:
1、证书的版本信息;
2、证书的序列号,每个证书都有一个唯一的证书序列号;
3、证书所使用的签名算法;
4、证书的发行机构名称,命名规则一般采用X.500格式;
5、证书的有效期,通用的证书一般采用UTC时间格式;
6、证书所有人的名称,命名规则一般采用X.500格式;
7、证书所有人的公开密钥;
8、证书发行者对证书的签名。
14. 说一下阻塞,非阻塞,同步,异步
阻塞和非阻塞:调用者在事件没有发生的时候,一直在等待事件发生,不能去处理别的任务这是阻塞。调用者在事件没有发生的时候,可以去处理别的任务这是非阻塞。
同步和异步:调用者必须循环地去查看事件有没有发生,这种情况是同步。调用者不用自己去查看事件有没有发生,而是等待着注册在事件上的回调函数通知自己,这种情况是异步
POSIX定义
- 同步IO操作:导致请求进程阻塞,直到IO操作完成
- 异步IO操作:不导致请求进程阻塞
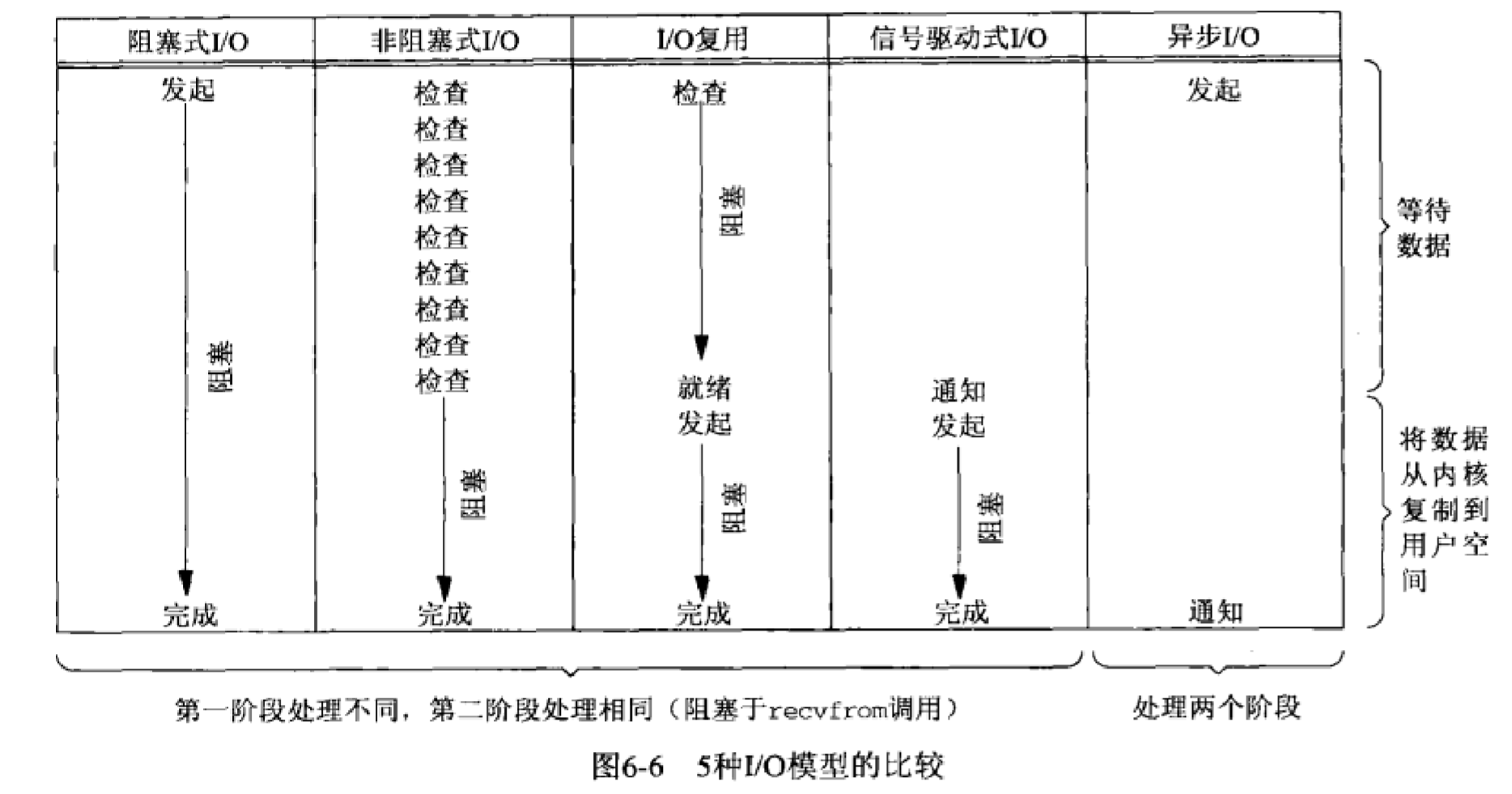
15. 说一下FTP 连接方式与传输模式
FTP连接方式
- 控制连接:标准端口为21,用于发送 FTP 命令
- 数据连接:标准端口为20,用于上传和下载数据
- 数据连接的建立类型:
- 主动模式:服务端主动从 20 端口向客户端发起连接
- 被动模式:服务端在某个端口范围内等待客户端的连接
FTP传输模式
- 文本模式:ASCII 模式,以文本序列传输数据
- 二进制模式:Binary 模式,以二进制序列传输数据
16. 说一下HTTPs建立连接的过程
-
首先是三次握手建立TCP连接
-
客户端发出请求
首先,客户端(通常是浏览器)先向服务器发出加密通信的请求,这被叫做ClientHello请求(TLS协议),其中TCP中push和ACK被置1。报文中包含客户端支持的SSL的指定版本、加密组件(Cipher Suite)列表(所支持的加密算法以及密钥长度)。
TLS包中包含一个随机序列值,客户端支持的加解密算法、
-
服务器回应
服务器先发送一个普通的TCP报文,其中ACK置1,表示对ClientHello的确认。
然后服务器再发送一个TLS包(Server Hello),其中PSH和ACK置1。TLS包中包含SSL版本以及加密组件(从收到的客户端加密组件列表中筛选出来的),以及服务器自己的有效证书。
-
客户端回应
客户端使用事先内置的可信中心的证书中的公钥对服务器证书上的数字签名进行验证,如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。验证服务器证书有效后,从服务器证书中提取服务器公钥。客户端此时会生成一个随机数(用作或用来生成对称密钥),并用公钥加密后发送给服务器。
-
服务端确认
服务端收到客户端的随机数后,会马上回复一个普通的TCP报文(ACK置1),表示确认收到。然后使用自己的私钥解密得到对称密钥。到此为止密钥协商完成,之后就是使用对称密钥进行通信。
那么客户端是如何验证服务器发过来的证书的呢?
- 客户端浏览器会预置根证书, 里面包含
CA公钥 - 服务器去CA申请一个证书
- CA用自己的签名去签一个证书,指纹信息保存在证书的数字摘要里面, 然后发送给服务器
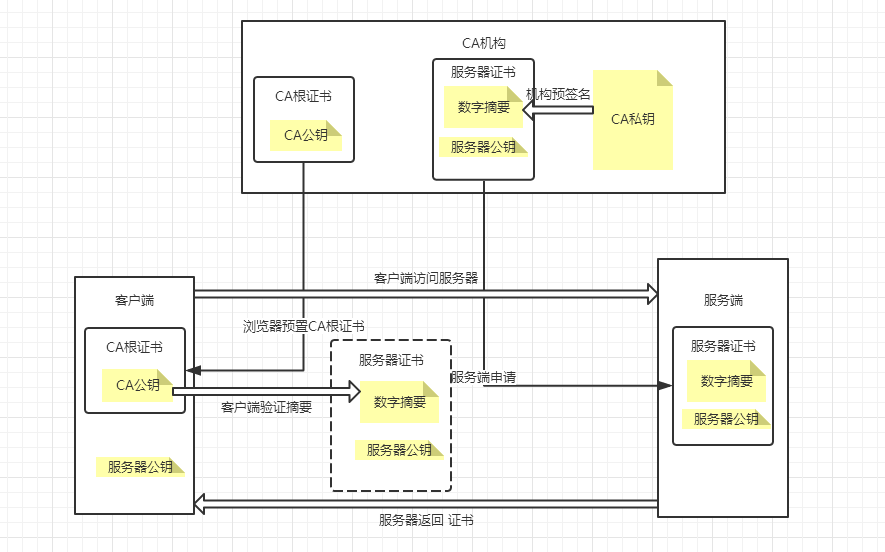
17. 说一下http1.1和1.0的区别
-
支持的方法
方法 说明 支持的HTTP协议版本 GET 获取资源 1.1、1.0 POST 传输实体主体 1.0、1.1 HEAD 获得报文首部 1.0、1.1 PUT 传输文件 1.0、1.1 DELETE 删除文件 1.0、1.1 OPTIONS 询问支持的方法 1.1 TRACE 追踪路径 1.1 CONNECT 要求用隧道协议连接代理 1.1 LINK 建立和资源之间的联系 1.0 UNLINK 断开连接关系 1.0 -
缓存处理,在HTTP1.0 中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
-
范围请求,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了
range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。Range: bytes=501-1000 (请求501-1000字节)
Range: bytes=501- (请求501字节之后的全部)
-
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
-
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
-
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理。长连接在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。流水线使得客户端不必每次都要等到收到服务器的响应就可以发送另一个HTTP请求,就像TCP窗口一样可以一次性发送多个HTTP请求。
18. 请你简单讲解一下,负载均衡 反向代理模式的优点、缺点
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
反向代理负载均衡技术是把将来自internet上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
优点:
- 反向代理负载均衡能以软件方式来实现,如apache mod_proxy、netscape proxy等,也可以在高速缓存器、负载均衡器等硬件设备上实现
- 反向代理负载均衡可以将优化的负载均衡策略和代理服务器的高速缓存技术结合在一起,提升静态网页的访问速度,提供有益的性能
- 由于网络外部用户不能直接访问真实的服务器,具备额外的安全性(同理,NAT负载均衡技术也有此优点)。
其缺点主要表现在以下两个方面:
-
反向代理是处于OSI参考模型第七层应用的,所以就必须为每一种应用服务专门开发一个反向代理服务器,这样就限制了反向代理负载均衡技术的应用范围,现在一般都用于对web服务器的负载均衡。
-
针对每一次代理,代理服务器就必须打开两个连接,一个对外,一个对内,因此在并发连接请求数量非常大的时候,代理服务器的负载也就非常大了,在最后代理服务器本身会成为服务的瓶颈。
一般来讲,可以用它来对连接数量不是特别大,但每次连接都需要消耗大量处理资源的站点进行负载均衡,如search等。
19. 说一下常用的14个HTTP状态码
2xx 成功
-
200 OK
请求被正常处理
-
204 No Content
请求处理成功,但没有资源可以返回
-
206 Partial Content
客户端执行基于范围的请求,服务端成功响应
3xx重定向
-
301 Moved Permanently
永久性重定向。表示服务端的资源的URI已更新,客户端需要使用新的URI才可以正确访问
-
302 Found
临时性重定向。和301相似,但302表示的是资源是临时移动,换句话说,已移动的资源对应的URI将来还有可能会发生改变
-
303 See Other
表示对应的资源还有其它的URI,应使用GET定向地获取请求的资源
当301、302、303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送。
301、302标准是禁止将POST方法改变成GET的,但是实际使用时大家都会改变。
-
304 Not Modified
该状态码表示客户端发送附带条件的请求时,服务器端允许请求访问资源,但未满足条件时的情况。304状态码返回时,不包含任何响应的主体。304虽然被划分到3xx类别中,但是和重定向没有任何关系。
-
307 Temporary Redirect
临时重定向。该状态码与302有着相同的含义。但是307会遵守浏览器标准,不会将POST变成GET。
4xx客户端错误
-
400 Bad Request
该状态码表示请求报文中存在语法错误,服务器无法理解。
-
401 Unauthorized
该状态码表示发送的请求需要有通过HTTP认证的认证信息。若之前已经进行过一次请求,则表示用户认证失败。
返回含有401的响应必须包含一个适用于被请求资源的WWW-Authenticate首部用以质询用户信息。当浏览器初次接收到401响应,会弹出用于认证的对话窗口。
-
403 Forbidden
该状态码表示请求资源的访问被服务器拒绝了,而服务器没必要给出拒绝的理由。
可能的原因有:未获得文件系统的授权、访问权限出现问题等。
-
404 Not Found
该状态码表示服务器上无法找到请求对应的资源。当然服务器也可以在拒绝访问时使用。
5xx服务器错误
-
500 Internal Server Error
服务器端在执行请求时发生了错误
-
503 Service Unavailable
该状态码表示服务器当前正处于超负荷运行或正在进行停机维护,导致现在无法处理请求。如果事先知道解除以上状况需要的时间,最好写入Retry-After首部字段后再返回给客户端。
20. 说一下MSS和MTU
-
IP头部:20字节
-
TCP头部:20字节
-
MTU:Maximum Transmission Unit,最大传输单元。是包或帧的最大长度。
-
MSS: Maximum Segment Size,最大报文段长度。是TCP数据包每次能够传输的最大数据分段。
为了达到最佳的传输效能,TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以一般MSS值1460
通讯双方会根据双方提供的MSS值得最小值确定为这次连接的最大MSS值。
21. 说一下IP分片与重组
物理网络层一般要限制每次发送数据帧的最大长度。任何时候 IP 层接收到一份要发送的 IP 数据报时,它要判断向本地哪个接口发送数据(选路),并查询该接口获得其 MTU(最大传输单元)。IP把 MTU 与数据报长度进行比较,如果需要则进行分片。分片可以发生在原始发送端主机上,也可以发生在中间路由器上。 把一份 IP 数据报分片以后,只有到达目的地才进行重新组装(这里的重新组装与其他网络协议不同,它们要求在下一站就进行进行重新组装,而不是在最终的目的地)。重新组装由目的端的 IP 层来完成,其目的是使分片和重新组装过程对运输层(TCP和UDP)是透明的, 除了某些可能的越级操作外。已经分片过的数据报有可能会再次进行分片(可能不止一次)。IP 首部中包含的数据为分片和重新组装提供了足够的信息。
当 IP 数据报被分片后,每一片都成为一个分组,具有自己的 IP 首部,并在选择路由时与其他分组独立。这样,当数据报的这些片到达目的端时有可能会失序,但是在 IP 首部中有足够的信息让接收端能正确组装这些数据报片。
为什么在中间路由器上不会进行IP重组呢?
- 因为无法保证IP数据报是否经由同一个路径传送。 因此,途中即使等待片刻,数据包也有可能无法到达目的地。
- 此外,拆分之后的每个分片也有可能会在途中丢失。
- 即使在途中某一处被重新组装,但如果下一站再经过其他路由时还会面临被分片的可能。这会给路由器带来多余的负担,也会降低网络传送效率。
路径MTU发现
分片机制也有它的不足。首先,路由器的处理负荷加重。随着时代的变迁,计算机网络的物理传输速度不断上升。这些高速的链路,对路由器和计算机网络提出了更高的要求。另一方面,随着人们对网络安全的要求提高,路由器需要做的其他处理也越来越多,如网络过滤(过滤是指只有带有一定特殊参数的IP数据报才能通过路由器。这里的参数可以是发送端主机、接收端主机、TCP或UDP端口号或者TCP的SYN标志或ACK标志等。) 等。因此,只要允许,是不希望由路由器进行IP数据包的分片处理的。
其次,在分片处理中,一旦某个分片丢失,则会造成整个 IP 数据报作废。
为了应对以上问题,产生了一种新的技术“路径MTU发现”(Path MTU Discovery(也可以缩写为 PMTUD。))。所谓路径MTU(Path MTU)是指从发送端主机到接收端主机之间不需要分片时最大MTU的大小,即路径中存在的所有数据链路中最小的MTU。而路径MTU发现从发送主机按照路径MTU的大小将数据报分片后进行发送。进行路径MTU发现,就可以避免在中途的路由器上进行分片处理,也可以在TCP中发送更大的包。现在,很多操作系统都已经实现了路径MTU发现的功能。
路径MTU发现原理
路径MTU发现的工作原理如下: 首先在发送端主机发送IP数据报时将其首部的分片禁止标志位设置为1。根据这个标志位,途中的路由器即使遇到需要分片才能处理的大包,也不会去分片,而是将包丢弃。随后,通过一个ICMP的不可达消息将数据链路上MTU的值给发送主机(具体来说,以ICMP不可达消息中的分片需求(代码4)进行通知。然而,在有些老式的路由器中,ICMP可能不包含下一个MTU值。这时,发送主机端必须不断增减包的大小,以此来定位一个合适的MTU值。) 。 下一次,从发送给同一个目标主机的IP数据报获得ICMP所通知的MTU值以后,将它设置为当前MTU。 发送主机根据这个MTU对数据报进行分片处理。如此反复,直到数据报被发送到目标主机为止没有再收到任何ICMP,就认为最后一次ICMP所通知的MTU即是一个合适的MTU值。那么,当MTU的值比较多时,最少可以缓存(缓存是指将反复使用的信息暂时保存到一个可以即刻获取的位置。) 约10分钟。在这10分钟内使用刚刚求得的MTU,但过了这10分钟以后则重新根据链路上的MTU做一次路径MTU发现。(需要一个定时器?) 前面是UDP的例子。那么在TCP的情况下,根据路径MTU的大小计算出最大段长度(MSS),然后再根据这些信息进行数据报的发送。因此,在TCP中如果采用路径MTU发现,IP层则不会再进行分片处理。
22. 说一下网络层与数据链路层的关系
数据链路层提供直连两个设备之间的通信功能。与之相比,作为网络层的IP则负责在没有直连的两个网 络之间进行通信传输。那么为什么一定需要这样的两个层次呢?它们之间的区别又是什么呢?
我们以送快递为例,快递公司将快递送到每个用户手中。对于快递本身来说,快递需要从打包点出发,经过飞机/火车/汽车/轮船/三轮车等等交通工具运输,到达了一个又一个快递点,最后由快递员送给我们。
这里每一种交通工具就相当于数据链路层,只能在直连的两个快递点(设备)之间传输数据,而快递公司负责将快递发送给最终的目标地址,属于点对点通信。
23. 说一下字节流服务与数据报服务的区别?
它们的区别对应到实际编程中,则体现为通信双方是否必须执行相同次数的读、写操作。当发送端应用程序连续多次写操作时, TCP模块先将这些数据放入TCP发送缓冲区中。当TCP模块真正开始发送数据时,发送缓冲区中这些等待发送的数据可能被封装成一个或多个TCP报文段发出。因此,应用程序执行的读操作次数和TCP模块接收到的TCP报文段个数之间也没有固定的数量关系。
这就是字节流的概念:应用程序对数据的发送和接收是没有边界限制的。UDP则不然,发送端应用程序每执行一次写操作,UDP模块就将其封装成一个UDP数据报并发送之。接收端必须及时针对每一个UDP数据报执行读操作(通过recvfrom系统调用),否则就会丢包。并且,如果用户没有指定足够的应用程序缓冲区来读取UDP数据,则UDP数据将被截断。
24. 说一下透明传输
透明表示一个实际存在的事物看起来好像不存在一样。
帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。
25. 若HTTP首部字段重复了会如何?
当HTTP首部字段中出现了两个或两个以上具有相同首部字段名时会怎么样?这种情况在规范内尚未明确,根据浏览器内部处理逻辑的不同,结果可能不太一样。有些浏览器会优先处理第一次出现的首部字段,而有些浏览器则会优先处理最后出现的首部字段。
数据库
1. 请你说一说数据库索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。
数据库索引是为了增加查询速度而对表字段附加的一种标识,是对数据库表中一列或多列的值进行排序的一种结构。
DB在执行一条Sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。
优点
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点
-
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
添加索引原则
- 在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
- 只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
- 定义为
text、image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。 - 当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
2. 请你说一说数据库事务
数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。 通过将一组相关操作组合为一个要么全部成功要么全部失败的单元,可以简化错误恢复并使应用程序更加可靠。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。事务是数据库运行中的逻辑工作单位,由DBMS中的事务管理子系统负责事务的处理。
事务具有4个基本特征,分别是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Duration),简称ACID。
1)原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,[删删删]因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
2)一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
3)隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
4)持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务已经正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
3. 请你说一说数据库隔离
同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
不同的隔离级别:
-
Read Uncommitted(读取未提交内容):最低的隔离级别,什么都不需要做,一个事务可以读到另一个事务未提交的结果。所有的并发事务问题都会发生。
-
Read Committed(读取提交内容):只有在事务提交后,其更新结果才会被其他事务看见。可以解决脏读问题。
-
Repeated Read(可重复读):在一个事务中,对于同一份数据的读取结果总是相同的,无论是否有其他事务对这份数据进行操作,以及这个事务是否提交。可以解决脏读、不可重复读。
-
Serialization(可串行化):事务串行化执行,隔离级别最高,牺牲了系统的并发性。可以解决并发事务的所有问题。
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
4. 请你说一说inner join和left join
-
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
-
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
-
inner join(等值连接) 只返回两个表中联结字段相等的行
5. 请你说一说数据库的三大范式
-
第一范式:当关系模式R的所有属性都不能再分解为更基本的数据单位时,称R是满足第一范式,即属性不可分
-
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式
-
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,即非主属性不传递依赖于键码
6. 请你介绍一下mysql的MVCC机制
MVCC是一种多版本并发控制机制,是MySQL的InnoDB存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。MVCC是通过保存数据在某个时间点的快照来实现该机制,其在每行记录后面保存两个隐藏的列,分别保存这个行的创建版本号和删除版本号,然后Innodb的MVCC使用到的快照存储在Undo日志中,该日志通过回滚指针把一个数据行所有快照连接起来。
7. 请问SQL优化方法有哪些
-
通过建立索引对查询进行优化
-
对查询进行优化,应尽量避免全表扫描
8. 请你说一下MySQL引擎和区别
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
MySQL存储引擎主要有: MyIsam、InnoDB、Memory、Blackhole、CSV、Performance_Schema、Archive、Federated、Mrg_Myisam。
但是最常用的是InnoDB和Mylsam。
InnoDB
InnoDB是一个事务型的存储引擎,有行级锁定和外键约束,底层使用B+树实现。
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
适用场景
-
经常更新的表,适合处理多重并发的更新请求。
-
支持事务。
-
可以从灾难中恢复(通过bin-log日志等)。
-
外键约束。只有他支持外键。
-
支持自动增加列属性auto_increment。
索引结构
-
InnoDB也是B+Treee索引结构。Innodb的索引文件本身就是数据文件,即B+Tree的数据域存储的就是实际的数据,这种索引就是聚集索引。这个索引的key就是数据表的主键,因此InnoDB表数据文件本身就是主索引。
-
InnoDB的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以Innodb不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样B+Tree的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
Mylsam
MyIASM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT或UPDATE数据时即写操作需要锁定整个表,效率便会低一些。MyIsam 存储引擎独立于操作系统,也就是可以在windows上使用,也可以比较简单的将数据转移到linux操作系统上去。
适用场景:
-
不支持事务的设计,但是并不代表着有事务操作的项目不能用MyIsam存储引擎,可以在service层进行根据自己的业务需求进行相应的控制。
-
不支持外键的表设计。
-
查询速度很快,如果数据库insert和update的操作比较多的话比较适用。
-
整天对表进行加锁的场景。
-
MyISAM极度强调快速读取操作。
-
MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
缺点:就是不能在表损坏后主动恢复数据。
索引结构:
- MyISAM索引用的B+ tree来储存数据,MyISAM索引的指针指向的是键值的地址,地址存储的是数据。B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。
InnoDB和Mylsam的区别
-
事务:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持,提供事务支持以及外部键等高级数据库功能。
-
性能:MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快。
-
行数保存:InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count()语句包含where条件时,两种表的操作是一样的。
-
索引存储:对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。MyISAM支持全文索引(FULLTEXT)、压缩索引,InnoDB不支持。
MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
InnoDB存储引擎被完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB存储它的表&索引在一个表空间中,表空间可以包含数个文件(或原始磁盘分区)。这与MyISAM表不同,比如在MyISAM表中每个表被存在分离的文件中。InnoDB 表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上。
-
服务器数据备份:InnoDB必须导出SQL来备份,LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
MyISAM应对错误编码导致的数据恢复速度快。MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
-
锁的支持:MyISAM只支持表锁。InnoDB支持表锁、行锁 行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
9. 请你回答一下mongodb和redis的区别
-
内存管理机制上:Redis 数据全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的 LRU 算法删除数据。MongoDB 数据存在内存,由 linux系统 mmap 实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘。
-
支持的数据结构上:Redis 支持的数据结构丰富,包括hash、set、list等。MongoDB 数据结构比较单一,但是支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富
10. 请你来说一说Redis的定时机制怎么实现的
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件:文件事件(服务器对套接字操作的抽象)和时间事件(服务器对定时操作的抽象)。Redis的定时机制就是借助时间事件实现的。
一个时间事件主要由以下三个属性组成:id:时间事件标识号;when:记录时间事件的到达时间;timeProc:时间事件处理器,当时间事件到达时,服务器就会调用相应的处理器来处理时间。一个时间事件根据时间事件处理器的返回值来判断是定时事件还是周期性事件
一个时间事件主要由以下三个属性组成:id:时间事件标识号;when:记录时间事件的到达时间;timeProc:时间事件处理器,当时间事件到达时,服务器就会调用相应的处理器来处理时间。一个时间事件根据时间事件处理器的返回值来判断是定时事件还是周期性事件。
11. 请你来说一说Redis是单线程的,但是为什么这么高效呢?
虽然Redis文件事件处理器以单线程方式运行,但是通过使用I/O多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与Redis服务器中其他同样以单线程运行的模块进行对接,这保持了Redis内部单线程设计的简单性。
12. 请问Redis的数据类型有哪些,底层怎么实现?
1)字符串:整数值、embstr编码的简单动态字符串、简单动态字符串(SDS)
2)列表:压缩列表、双端链表
3)哈希:压缩列表、字典
4)集合:整数集合、字典
5)有序集合:压缩列表、跳跃表和字典
13. 请问Redis的rehash怎么做的,为什么要渐进rehash,渐进rehash又是怎么实现的?
因为redis是单线程,当K很多时,如果一次性将键值对全部rehash,庞大的计算量会影响服务器性能,甚至可能会导致服务器在一段时间内停止服务。不可能一步完成整个rehash操作,所以redis是分多次、渐进式的rehash。渐进性哈希分为两种:
1)操作redis时,额外做一步rehash
对redis做读取、插入、删除等操作时,会把位于table[dict->rehashidx]位置的链表移动到新的dictht中,然后把rehashidx做加一操作,移动到后面一个槽位。
2)后台定时任务调用rehash
后台定时任务rehash调用链,同时可以通过server.hz控制rehash调用频率
14. 请你来说一下Redis和memcached的区别
- 数据类型 :redis数据类型丰富,支持set liset等类型;memcache支持简单数据类型,需要客户端自己处理复杂对象
- 持久性:redis支持数据落地持久化存储;memcache不支持数据持久存储。
- 分布式存储:redis支持master-slave复制模式;memcache可以使用一致性hash做分布式。
- value大小不同:memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
- 数据一致性不同:redis使用的是单线程模型,保证了数据按顺序提交;memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
- cpu利用:redis单线程模型只能使用一个cpu,可以开启多个redis进程