前言
跳表是什么?计算机专业的同学毕业了也不一定听说过,因为课本上根本没有跳表。包括鼎鼎大名的《算法4》和《算法导论》都没有提及跳表这一数据结构。我也是在看面经的过程中发现的,我发现大多数关于跳表的问题都会涉及到 redis ,于是我就去找了本 《Redis设计与实现》,看看其中关于跳表的描述,差不多就知道了跳表是个什么玩意。然后再去Google看一些大牛的分析文章,自己再将其总结一遍。
定义
跳表本质上其实就是个优化后的双向链表,是可以进行二分查找的有序链表。
跳表是一个随机化的数据结构,可以被看做二叉树的一个变种,它在性能上和红黑树,AVL树不相上下,但是跳表的原理非常简单,目前在 Redis 和 LeveIDB 中都有用到。
复杂度
| 算法 | 平均 | 最差 |
|---|---|---|
| 空间 | $O(N)$ | $O(NlogN)$ |
| 搜索 | $O(logN)$ | $O(N)$ |
| 插入 | $O(logN)$ | $O(N)$ |
| 删除 | $O(logN)$ | $O(N)$ |
原理
既然跳表的本质是个双向链表,那么它是如何进行二分查找的呢?当然不是重载运算符加号 “+”,再一个一个加上去。那么一个链表要如何才能实现二分查找呢?这就是理解跳表的核心问题。
我们不妨从时间复杂度的角度逆向进行分析吧!跳表的搜索、插入和删除的平均时间复杂度都是 $O(logN)$ ,这个时间复杂度一般对应的就是二分法。如果我们实现了二分查找,那么搜索的时间复杂度就能满足。如果搜索的时间复杂度为 $O(logN)$ ,那么插入的时间复杂度就是 $O(logN)$ 的查找插入位置 + $O(1)$ 的插入,也就是 $O(logN)$ 的时间复杂度,同理删除也能达到 $O(logN)$ 的时间复杂度。
现在我们的问题就是跳表是如何实现二分查找的?
答案是多级指针。什么意思呢?就是一个跳表的结点里面有一个基础的前向指针和后向指针,但是该结点可能会存在多个多级前向指针指针指向前面不同距离的结点。如图:
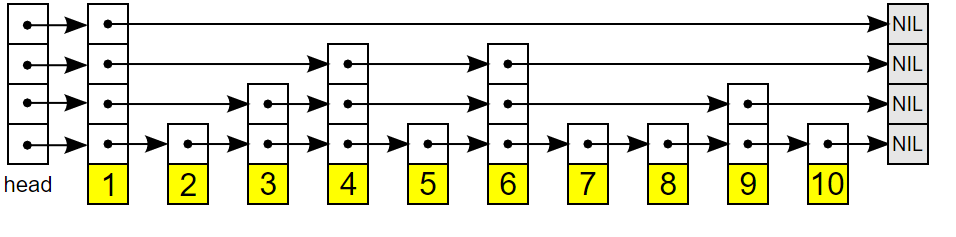
搜索时先从头结点的最高级指针遍历,如果下一结点值大于目标值,那么就说明目标值在当前结点和下一节点之间。于是在该结点我们取低一级指针,继续向前遍历,同样找到第一个大于目标值的结点,再该结点前一个结点停下,继续取低一级指针,依次循环以上操作,直到最后取到最低一级指针,也就是最原始的指针(指针指向下一节点,不会跳过结点)。当到达最低一级指针时,我们已经离目标值很近了,因此只需要简单的向前遍历就好了。如图:
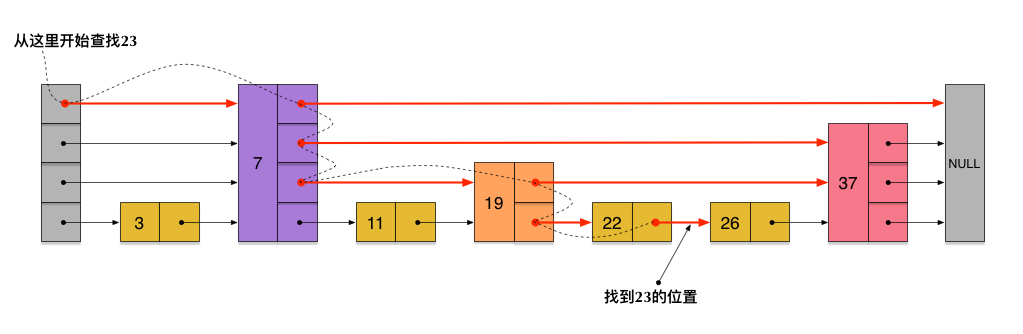
实现
我们就以 redis-6.0.5(当前最新稳定版) 中的实现为例,看一下跳表是如何实现的。
跳表结构
typedef char *sds; //sds.h
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
在文件 server.h 中我们可以看到跳表就是一个没有方法只有成员变量的结构体(C语言实现)。其中 zskiplistNode 是跳表结点,zskiplist 是跳表加上头尾结点将跳表结点包装起来的一个列表结构。
zskiplistNode
- ele 是个字符指针,应该是指向结点要存储的用户数据。
- score 是个 double 类型的分值,跳表就是以该值进行比较排序的
- backward 后向指针,指向后面一个结点(上一个)。用来逆向访问,不过每个结点只有一个后向指针,因此每次只能后退至前一个结点。
- level[] 是个结构数组,里面每个元素都存储了一个前向指针和一个无符号的长整型变量。结构数组的大小就是该结点的层数。结构体中的变量:
- forward 前向指针,指向前一个结点(下一个)
- span 跨度,表示与前一个结点的距离,用来计算每个结点在跳表中的按大小排列的排位:在查找某个结点的过程中,将沿途访问过的所有层的跨度累计起来,得到的结果就是该节点在跳跃表中的排位。
zskiplist
- header 头结点。用来在$O(1)$的时间复杂度内定位头结点
- tail 尾结点。用来在$O(1)$的时间复杂度内定位尾结点
- length 表中结点数量。用来在$O(1)$的时间复杂度内得到跳跃表的长度
- level 表中层数最大结点的层数。用来在$O(1)$的时间复杂度内获得跳表中层数最高的结点的层数。注意表头结点的层高不算在内。
一个例子
带有不同层高的结点之间的指向关系
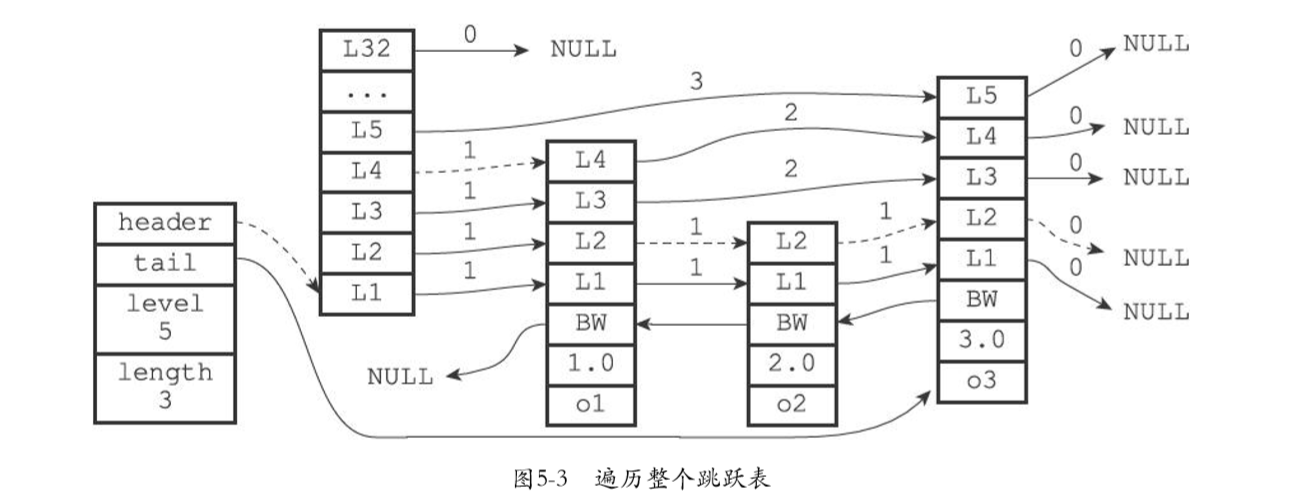
创建跳表
我们看到zslCreate函数就是创建并返回一个空的跳表,其中头结点被赋值,但尾结点被赋值为NULL。
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
我们进一下zmalloc函数看看它都干了些什么。
//看一下zmalloc
static void (*zmalloc_oom_handler)(size_t) = zmalloc_default_oom;
void *zmalloc(size_t size) {
void *ptr = malloc(size+PREFIX_SIZE);
if (!ptr) zmalloc_oom_handler(size);
#ifdef HAVE_MALLOC_SIZE
update_zmalloc_stat_alloc(zmalloc_size(ptr));
return ptr;
#else
*((size_t*)ptr) = size;
update_zmalloc_stat_alloc(size+PREFIX_SIZE);
return (char*)ptr+PREFIX_SIZE;
#endif
}
//看一下zmalloc_default_oom
static void zmalloc_default_oom(size_t size) {
fprintf(stderr, "zmalloc: Out of memory trying to allocate %zu bytes\n",
size);
fflush(stderr);
abort();
}
再进一下zslCreateNode函数
/* Create a skiplist node with the specified number of levels.
* The SDS string 'ele' is referenced by the node after the call. */
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
销毁跳表结点
/* Free the specified skiplist node. The referenced SDS string representation
* of the element is freed too, unless node->ele is set to NULL before calling
* this function. */
void zslFreeNode(zskiplistNode *node) {
sdsfree(node->ele);
zfree(node);
}
//跟进一下sdsfree函数
/* Free an sds string. No operation is performed if 's' is NULL. */
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}
//再跟进一下s_free函数
#define s_free zfree
//竟然是个宏定义?算了继续跟进zfree函数
void zfree(void *ptr) {
#ifndef HAVE_MALLOC_SIZE
void *realptr;
size_t oldsize;
#endif
if (ptr == NULL) return;
#ifdef HAVE_MALLOC_SIZE
update_zmalloc_stat_free(zmalloc_size(ptr));
free(ptr);
#else
realptr = (char*)ptr-PREFIX_SIZE;
oldsize = *((size_t*)realptr);
update_zmalloc_stat_free(oldsize+PREFIX_SIZE);
free(realptr);
#endif
}
//不跟了,太多调用关系了
销毁跳表
/* Free a whole skiplist. */
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
zfree(zsl->header);
while(node) {
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
zfree(zsl);
}
//可以看到先通过头结点得到第一个结点,然后头结点就没用了,直接销毁
//然后就是利用最低级指针遍历所有结点,
//通过销毁节点函数一一销毁
//最后是zfree掉 跳表这个变量
插入结点
变量
- update:这是一个结点数组,保存了待插入结点插入后的每一级指针的上一个结点(back),即跨度会受到影响的结点
- x:一个结点,前期用作遍历的普通变量,后期指向待插入结点
- level:新插入结点的指针层数
- rank[i]:结点update[i]的排位,用于计算新的跨度
流程
首先查找要插入的位置,这个过程中记录下新插入结点每一级指针的的后向结点update[i],同时记录其排位rank[i]。方便后续更新。
调用随机函数取得新结点的指针层数,然后调用创建结点函数得到新结点。
最后将第一步查找得到的update和rank信息用上,更新新的指针指向和跨度。
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
这个随机函数有必要列出来一下
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
删除结点
变量
- update数组:这是一个结点数组,保存了待删除结点的每一级指针的上一个结点(back),即删除节点后跨度会受到影响的结点
- x:一个结点指针,前期用作遍历的普通变量,后期指向待删除结点
流程
首先查找待删除结点位置,并记录update结点数组。
如果找到待删除结点并且该结点的分数和内容都匹配,那么就将其删除,否则说明没找到,返回0。
/* Delete an element with matching score/element from the skiplist.
* The function returns 1 if the node was found and deleted, otherwise
* 0 is returned.
*
* If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise
* it is not freed (but just unlinked) and *node is set to the node pointer,
* so that it is possible for the caller to reuse the node (including the
* referenced SDS string at node->ele). */
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
//跟进zslDeleteNode函数
/* Internal function used by zslDelete, zslDeleteRangeByScore and
* zslDeleteRangeByRank. */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
查找结点
通过排位查找
该方法的查找很简单,就是从最高层级向低级遍历,累加遇到的跨度,直到达到参数rank即可返回当前结点。否则返回null。
/* Finds an element by its rank. The rank argument needs to be 1-based. */
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
if (traversed == rank) {
return x;
}
}
return NULL;
}
后记
这是第一次看redis源码,之前打算暑假看看redis源码,但这一看就看傻了,一个文件就有几千行代码,总共一百多文件,这谁顶得住啊!不看了,看看书了解一下就打住。跳表的部分也还有好大一部分没看,就先看这些吧!
参考资料
- http://zhangtielei.com/posts/blog-redis-skiplist.html
- https://baike.baidu.com/item/%E8%B7%B3%E8%A1%A8/22819833
- 《Redis设计与实现》