前言
前面一篇文章研究了 select() 函数的 io 复用原理,我们发现 select 函数在性能上也存在几个缺点:调用 select 函数后如果集合中有文件描述符发生变化,我们还需要构造循环语句去找出发生变化的具体文件描述符;还有 select 函数调用会更改其传入的监视对象,即 fd_set 集合,所以调用 select 函数之前需要复制一份拷贝,并在每次调用 select 函数时传入该拷贝。
但其实提高 select 函数性能的障碍并不是表面上的循环语句,而是每次调用 select 函数时都需要重新传递监视对象信息。因为传递监视对象信息具有以下含义:
每次调用 select 函数时向操作系统传递监视对象信息
应用程序对操作系统传递数据将对程序造成很大负担,而且无法通过优化代码来解决,因此将成为性能上的致命弱点。那为何需要将监视对象信息传递给操作系统呢?select 函数是监视套接字变化的函数,而套接字是由操作系统管理的,所以 select 函数需要借助于操作系统才能完成功能。
而使用 epoll 则具有以下优点(似乎恰好对应于 select 的缺点):
- 无需编写以监视状态变化为目的的针对所有文件描述符的循环语句
- 调用对应于 select 函数的 epoll_wait 函数时无需每次都传递监视对象信息
epoll函数
综述
使用 epoll 需要知道 3 个函数:
- epoll_create():创建保存 epoll 文件描述符的空间
- epoll_ctl():向空间注册并注销文件描述符
- epoll_wait():与 select 函数类似,等待文件描述符发生变化
select 中为了保存监视对象文件描述符,直接声明了 fd_set 变量。但 epoll 方式下由操作系统负责保存监视对象文件描述符,因此需要向操作系统请求创建保存文件描述符的空间,此时使用的函数就是 epoll_create()。
此外,为了添加和删除监视对象文件描述符,select 方式中需要 FD_SET、FD_CLR 函数。但在 epoll 方式中,通过 epoll_ctl 函数请求操作系统完成。
最后,select 方式下调用 select 函数等待文件描述符的变化,而 epoll 中调用 epoll_wait 函数。还有,select 方式中通过 fd_set 变量查看监视对象的状态变化,而 epoll 方式中通过如下结构体 epoll_event 将发生变化的文件描述符单独集中到一起。
声明足够大的 epoll_event结构体数组 后,传递给 epoll_wait 函数时,发生变化的文件描述符信息将被填入该数组。因此无需像 select 函数那样针对所有文件描述符进行循环。

epoll_create函数
#include <sys/epoll.h>
int epoll_create(int size);
/*
返回值:
成功时返回非负整数的epoll文件描述符,失败时返回-1
参数:
size:epoll实例的大小
*/
调用epoll_create函数时创建的文件描述符保存空间称为“epoll例程”,通过参数size传递的值决定epoll例程的大小,但该值只是向操作系统提供建议,仅供操作系统参考。
epoll是从Linux的2.5.44版内核开始引入的,而2.6.8之后的Linux内核将完全忽略传入的size参数,因为内核会根据具体情况调整epoll例程的大小。但是size的值还是要填,而且不能为负数。
epoll 把用户关心的文件描述符上的事件放在内核里的一个事件表中,这样就无须像 select 和 poll 那样每次调用都要重复传入文件描述符集或事件集。但 epoll 需要一个额外的文件描述符,用来唯一标识内核中的这个事件表。而这个额外的文件描述符就是由 epoll_create 函数创建。
epoll_create 函数创建的资源与套接字相同,也有操作系统直接管理。因此,该函数和创建套接字的情况相同,也会返回文件描述符。也就是说,该函数返回的文件描述符主要用于区分 epoll 例程。需要终止时,与其它文件描述符相同,也要调用 close 函数。当指向一个实例的所有文件描述符都被 close() 后内核将销毁该 epoll 实例,并释放相关资源,以便再次利用。
epoll_ctl函数
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/*
返回值:成功时返回0,失败时返回-1
参数:
epfd:用于注册监视对象的 epoll 例程的文件描述符
op:用于指定监视对象的添加、删除或更改等操作
fd:需要注册的监视对象文件描述符
event:监视对象的事件类型
*/
函数的意思是向 epoll 例程epfd中op文件描述符fd,主要目的是监视event中的事件。epoll_event 结构体上面已经介绍了,这里只需要再说明一下op参数,该参数可以有以下取值:
- EPOLL_CTL_ADD:将文件描述符注册到 epoll 例程中
- EPOLL_CTL_MOD:更改注册的文件描述符的关注事件发生情况
- EPOLL_CTL_DEL:从 epoll 实例中删除文件描述符
例如:
epoll_ctl(A,EPOLL_CTL_ADD,B,C);//向例程A中注册文件描述符B,主要目的是监视参数C中的事件
epoll_ctl(A,EPOLL_CTL_DEL,B,NULL);//从epoll例程中删除文件描述符B
最后我们再详细看一下第四个参数event,我们知道这是一个结构体,其中有两个成员,一个是事件events,一个是 union 联合体,这里取联合体中的int fd,也就是文件描述符。这里在带入epoll_ctl函数之前,我们需要先填充该结构体的两个成员变量,其中的文件描述符是哪个文件呢?其实就是epoll_ctl函数的第3个参数,也就是我们要注册的文件描述符(也不知道结构体中已经带有了为什么还要多传入一个参数)。例如:
struct epoll_event event;
......
event.events = EPOLLIN;//发生需要读取数据的情况(事件)时
event.data.fd = sockfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &event);
......
上述代码将 sockfd 注册到 epoll 例程 epfd 中,并在需要读取数据的情况下产生了相应的事件。
然后我们来看看epoll_event的成员 events 中可以保存的常量及所指的事件类型:
- EPOLLIN:需要读取数据的情况
- EPOLLOUT:输出缓冲为空,可以立即发送数据的情况
- EPOLLPRI:收到 OOB 数据的情况(文件有紧急数据可读)
- EPOLLHUP:文件被挂断(本端)。这个事件是一直监控的,即使没有明确指定
- EPOLLRDHUP:断开连接或半关闭的情况(对端),这在边缘触发方式下非常有用
- EPOLLERR:发生错误的情况
- EPOLLET:以边缘触发的方式得到事件通知,默认的是水平触发,所以我们并未看到 EPOLLLT
- EPOLLONESHOT:发生一次事件后,相应文件描述符不再收到事件通知,因此需要向 epoll_ctl 函数的第 2 个参数传递 EPOLL_CTL_MOD,再次设置事件
- EPOLLWAKEUP:如果 EPOLLONESHOT 和 EPOLLET 清除了,并且进程拥有 CAP_BLOCK_SUSPEND 权限,那么这个标志能够保证事件在挂起或者处理的时候,系统不会挂起或休眠
可以通过位或运算同时传递多个上述参数。
epoll_wait函数
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
/*
返回值:成功时返回发生事件的文件描述符数(大于等于0),失败时返回-1
参数:
epfd:表示事件发生监视范围的epoll例程的文件描述符
events:保存发生事件的文件描述符集合的 结构体数组 地址
maxevents:第二个参数中可以保存的最大事件数
timeout:以微妙为单位的等待时间,传递-1时,一直等待直到有事件发生
*/
函数调用示例:
int event_cnt;
struct epoll_event * ep_events;
......
ep_events = malloc(sizeof(struct epoll_event) * EPOLL_SIZE);//EPOLL_SIZE是宏常量
......
event_cnt = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1);
......
调用函数后,返回发生事件的文件描述符数,同时在第二个参数指向的缓冲区中保存发生事件的文件描述符集合。因此无需像select那样插入针对所有文件描述符的循环。
具体来说,就是如果检测到事件,就将所有就绪的事件从内核事件表(由 epfd 参数指定)中复制到它的第二个参数 ep_events 指向的数组中。这个数组只用于输出 epoll_wait 检测到的就绪事件,而不像 select、poll 的数组参数那样既用于传入用户注册的事件,又用于输出内核检测到的就绪事件。因此极大地提高了应用程序索引就绪文件描述符的效率。
使用epoll实现简单echo服务器
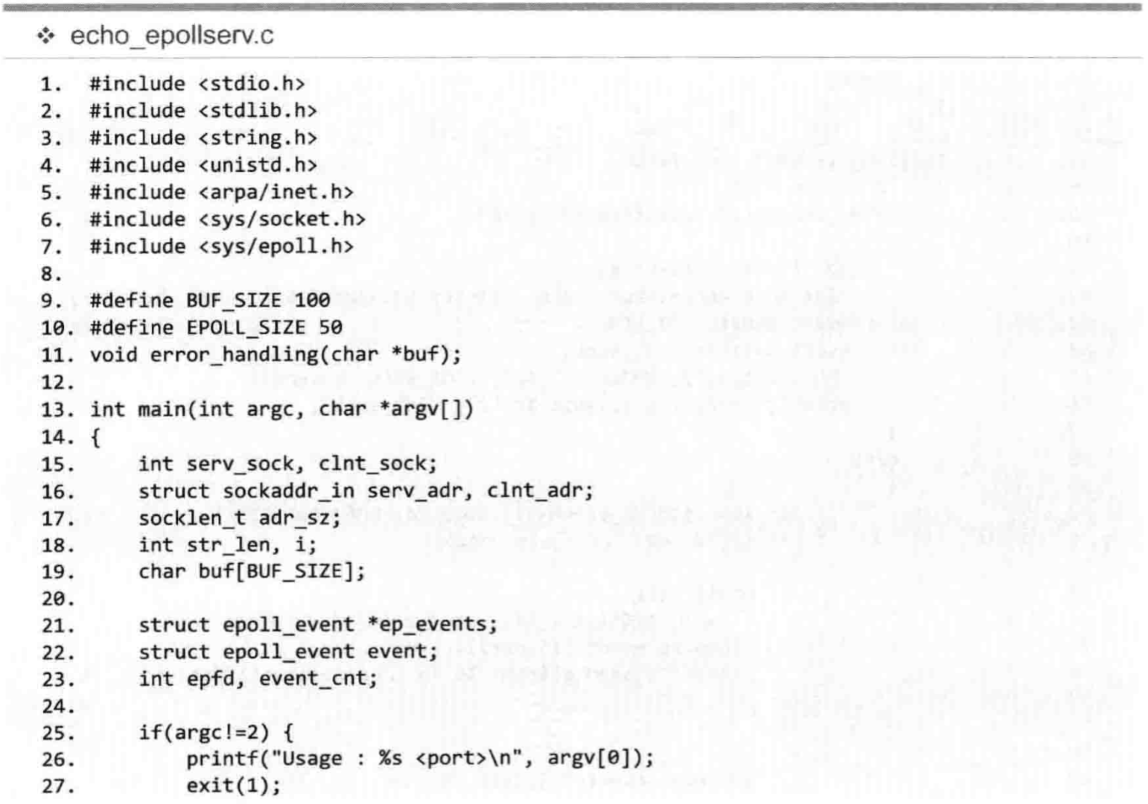


如果理解了上一篇select的文章,那么看懂上面的服务器代码就很容易了。
水平触发和边缘触发
epoll分为两种工作方式LT和ET。
LT(level triggered) 是默认/缺省的工作方式,同时支持 block和no_block socket。这种工作方式下,内核会通知你一个 fd 是否就绪,然后才可以对这个就绪的 fd 进行 I/O 操作。就算你没有任何操作,系统还是会继续提示 fd 已经就绪,不过这种工作方式出错会比较小,传统的 select/poll 就是这种工作方式的代表。
ET(edge-triggered) 是高速工作方式,仅支持 no_block socket,这种工作方式下,当 fd 从未就绪变为就绪时,内核会通知 fd 已经就绪,并且内核认为你知道该 fd 已经就绪,不会再次通知了,除非因为某些操作导致 fd 就绪状态发生变化。如果一直不对这个 fd 进行I/O操作,导致fd变为未就绪时,内核同样不会发送更多的通知,因为only once。所以这种方式下,出错率比较高,需要增加一些检测程序。
例如服务器输入缓冲区收到 50 字节的数据时,水平触发和边缘触发都会通知该事件。但服务器读取 20 字节还剩下 30 字节时,水平触发仍会通知该事件。也就是说,水平触发是只要缓冲区中有数据,就会再次注册该事件。而边缘触发方式中输入缓冲区收到数据时仅注册一次该事件,之后即使该缓冲区中仍有数据,也不会再次注册。
个人理解
我们可以利用脉冲信号来辅助理解,水平触发就是指信号处于高位的水平时,就会一直触发;而边缘触发只有在上升沿时才会触发。
使用边缘触发
......
int flag = fcntl(fd, F_GEFL, 0);
fcntl(fd, F_SETFL, flag|O_NONBLOCK);//设置socket为非阻塞模式
event.events = EPOLLIN|EPOLLET; //设置事件为边缘触发
event.data.fd = fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &event); //注册事件
......
str_len = read(ep_events[i].data.fd, buf, BUF_SIZE);
......
if (str_len < 0) {
if (errno == EAGAIN) {
//缓冲区为空
}
}
......
-
为什么需要使用 errno?
边缘触发方式中,接收数据时仅注册一次该事件,因为这种特点,一旦发生输入相关事件,就应该读取输入缓冲区中的全部数据,因此需要验证输入缓冲区是否为空。而 read 函数返回 -1,变量 errno 中的值为 EAGAIN 时,说明没有数据可读。
-
为什么需要设置 socket 为非阻塞?
在边缘触发方式下,以阻塞方式工作的 read&write 函数有可能引起服务端的长时间停顿。因此,边缘触发方式中一定要采用非阻塞 read&write 函数。
select、poll和epoll的区别
| 系统调用 | select | poll | epoll |
|---|---|---|---|
| 事件集合 | 用户通过3个参数分别传入感兴趣的可读、可写以及异常等事件,内核通过对这些参数的在线修改来反馈其中的就绪事件。这使得用户每次调用select都要重置这3个参数 | 统一处理所有事件类型,因此只需一个事件集参数。用户通过pollfd.events传入感兴趣的事件,内核通过修改pollfd.events反馈其中就绪的事件 | 内核通过一个事件表直接管理用户感兴趣的所有事件。因此每次调用epoll_wait时,无须反复传入用户感兴趣的事件。epoll_wait系统调用的参数events仅用来反馈就绪的事件 |
| 应用程序索引就绪文件描述符的时间复杂度 | O(n) | O(n) | O(1) |
| 最大支持文件描述符数 | 一般有最大限制 | 65535 | 65535 |
| 工作模式 | LT | LT | 支持ET高效模式 |
| 内核实现和工作效率 | 采用轮询方式来检测就绪事件。算法时间复杂度为O(n) | 采用轮询方式来检测就绪事件。算法时间复杂度为O(n) | 采用回调方式来检测就绪事件。算法时间复杂度为O(1) |
关于 epoll 的学习就先到这里吧,虽然学习得不够彻底,但是也还是从完全的不会到学会并理解了。以后有时间再看看 epoll 的源码实现吧!
参考资料
- https://www.cnblogs.com/my_life/articles/3968782.html
- https://blog.lucode.net/linux/epoll-tutorial.html
- 《TCP/IP网络编程》第17章