前言
我们都知道服务器是用来服务大众的,因而其必须支持用户的并发访问。而我们普通的 socket 是阻塞式的,即服务器在空闲时处于监听状态,有用户连接请求时则创建一个新的 socket 来与用户交互。在服务器与用户交互的这段时间,服务器的监听功能处于瘫痪状态(不能向外界做出反馈),也不能处理其它用户的请求,因为服务器在专注于 send() 和 recv() (或者 sendto()/recvfrom(),与用户交互)。而用户与服务器之间一般也不会很快就断开连接,并且两者之间的交互频率还低得惊人(相对于 cpu 频率),这显然是浪费了服务器的计算资源啊!如何才能更大效率的利用服务器呢?
使用fork()
方式1 是使用 fork() 函数创建子进程,外层循环控制服务器始终处于监听状态,一旦有用户连接请求,就创建子进程,子进程会复制父进程当前的环境,因而可以在子进程中处理与用户交互的细节,而在父进程中继续监听,等待其它连接请求。这种方式可以实现并发处理,但是使用多进程的方式,并且一个进程只处理一个用户的连接,难免显得太过于笨重。因为复制进程是比较费时费力的,但是你却用一个进程去处理一个小小的连接,未免太看不起进程了。
使用select()
于是就有了方式2,也就是我现在要研究的东西,他就是 select() 函数。我们先回顾 fork() 的处理过程,然后再想想如何改进。fork() 函数创建一个和当前进程几乎相同的子进程,我们就是在监听并 accept 客户端的连接后得到了连接客户端的 clientSocket,此时我们调用 fork() 创建子进程。然后子进程中也有一个 clientSocket,我们就是利用子进程中的 clientSocket 套接字来与客户端通讯实现并发处理的。但是我们擦亮眼睛发现,子进程中还有 listenSocket,客户端服务器地址、端口配置等等一系列信息都没有使用呢?偌大的一个进程我们只需要其中的一个 clientSocket,但是我们却为了它复制了整个进程,这也就是使用子进程处理并发效率低的原因之一。有没有办法把客户端的连接请求统一处理,把大量的 clientSocket 使用一个容器装起来,当其中某个 socket 有通讯需要的时候我们再找到它并用它来与对应的客户端通讯?有,就是 select() 处理机制。
使用 select() 函数可以将多个文件描述符(当然也包括 socket 套接字)集中到一起统一监视。使用步骤如下:

设置文件描述符
我们使用一个叫 fd_set 的数据结构(实际上是 long 型数组)来存储我们要监视的文件描述符。这里注意我们的文件描述符是 int 型的整数,但是在 fd_set 中是用位 (bit) 来表示文件描述符的。百度百科上说 fd_set 实际上是 long 型数组,那么它是如何使用 1bit 来存储 1 个文件描述符呢?为了测试我的猜想,我在linux环境下写了个测试程序:
1 #include <sys/time.h>
2 #include <sys/types.h>
3 #include <unistd.h>
4
5 #include <stdio.h>
6
7 int main(int argc, char* argv[]) {
8 fd_set fds;
9 FD_ZERO(&fds);//初始化为0
10 while (true) {
11 int i;
12 scanf("%d", &i);
13 FD_SET(i, &fds);
14 printf("%d\t->\t0x%X\n", i, *(long*)&fds);//强行解析数组中第一个long大小的数据
15 FD_CLR(i, &fds);//每次清零
16 }
17 return 0;
18 }
下面是其输出:
0
0 -> 0x1
1
1 -> 0x2
2
2 -> 0x4
3
3 -> 0x8
4
4 -> 0x10
5
5 -> 0x20
6
6 -> 0x40
7
7 -> 0x80
8
8 -> 0x100
9
9 -> 0x200
10
10 -> 0x400
11
11 -> 0x800
12
12 -> 0x1000
由于我们每次设置了一个文件描述符后就清零了,因此上面的都只是一个文件描述符的情况,那么我们不清零,看看多个文件描述符并存是怎样一番景象(把上面的程序的清零注释掉):
1 #include <sys/time.h>
2 #include <sys/types.h>
3 #include <unistd.h>
4
5 #include <stdio.h>
6
7 int main(int argc, char* argv[]) {
8 fd_set fds;
9 FD_ZERO(&fds);//初始化为0
10 while (true) {
11 int i;
12 scanf("%d", &i);
13 FD_SET(i, &fds);
14 printf("%d\t->\t0x%X\n", i, *(long*)&fds);//强行解析数组中第一个long大小的数据
15 //FD_CLR(i, &fds);//每次清零
16 }
17 return 0;
18 }
继续看看输出:
0
0 -> 0x1
0
0 -> 0x1
1
1 -> 0x3
1
1 -> 0x3
2
2 -> 0x7
5
5 -> 0x27
15
15 -> 0x8027
为了简单起见,上面的程序输出使用 16 进制表示,但是很容易转换到二进制(草稿纸上写一下结论就出来了)。从上面的输出我们可以知道,如果我们传入的文件描述符的取值是从 0 开始的非负整数,那么一个文件描述符的值加 1 就是其在fd_set中的内存相对位置(以bit为单位)。
例如:
开始传入文件描述符为0,那么从地址&fd_set起第(0+1)位就置为1,如果把前32位解析为long其值就为0x1,二进制形式:
(高位)0000 0000 0000 0001(低位)
再传入文件描述符为1,那么从地址&fd_set起第(1+1)位就置为1,如果把前32位解析为long其值就为0x3,二进制形式:
(高位)0000 0000 0000 0011(低位)
再传入文件描述符为2,那么从地址&fd_set起第(2+1)位就置为1,如果把前32位解析为long其值就为0x7,二进制形式:
(高位)0000 0000 0000 0111(低位)
再传入文件描述符为5,那么从地址&fd_set起第(5+1)位就置为1,如果把前32位解析为long其值就为0x27,二进制形式:
(高位)0000 0000 0010 0111(低位)
再传入文件描述符为15,那么从地址&fd_set起第(15+1)位就置为1,如果把前32位解析为long其值就为0x8027,二进制形式:
(高位)1000 0000 0010 0111(低位)
当然,文件描述符一定可能会大于 15,如果超出了 sizeof(long) 也不用担心,笔者认为我们只需要将 fd_set 看成是 bit 型数组,那么一切就好理解了。
理解了文件描述符在 fd_set 里的存储方式,那么我们要怎么把文件描述符放进去呢?难道要我们自己去用指针将对应的位置为 1?怎么可能那么复杂!实际上,在fd_set变量中注册或更改值的操作都可以由下列宏来完成:
- void FD_ZERO(fd_set *fdset):将 fdset 的所有位初始化为 0 。
- void FD_SET(int fd, fd_set *fdset):在 fdset 中注册文件描述符fd的信息。
- void FD_CLR(int fd, fd_set *fdset):从 fdset 中清除文件描述符fd的信息。
- int FD_ISSET(int fd, fdset *fdset):返回 fdset 中文件描述符fd对应的位的值(0 or 1)
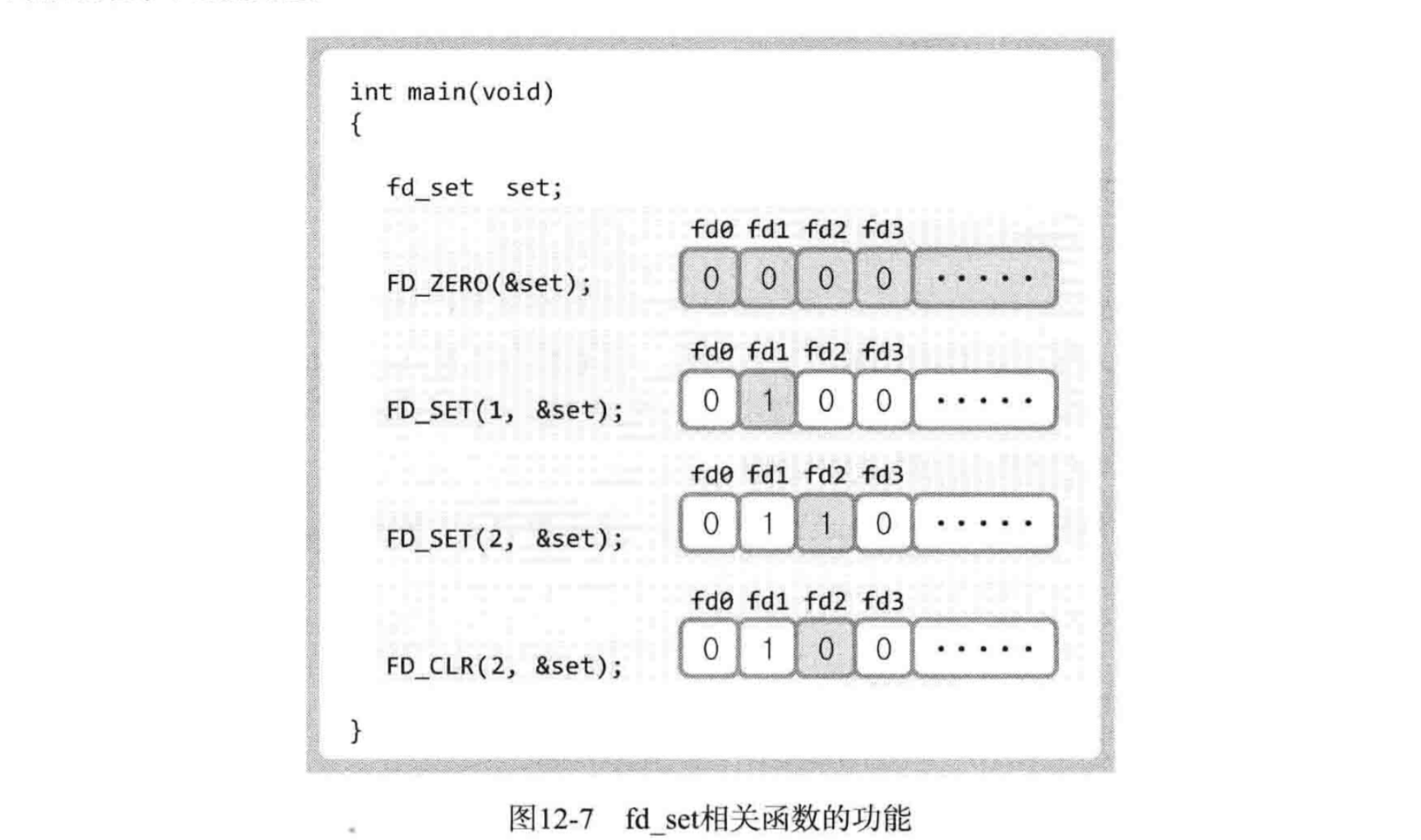
指定监视范围
首先了解一下select函数及其参数含义:
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int maxfd, fd_set *readset, fd_set *writeset,
fd_set *exceptset, struct timeval *timeout);
/*
返回值:
成功时返回3个set中文件描述符总数之和,失败时返回-1
参数:
maxfd:所有文件描述符中最大值加1
readset:用来读的文件描述符
writeset:用来写的文件描述符
exceptset:用来观察是否异常的文件描述符
timeout:在该时间内若没有文件描述符发生变动则进入阻塞状态
*/
言归正传,文件描述符的监视范围与 select 函数的第一个参数 maxfd 有关。既然是范围,那么一定要知道要监视的文件描述符的数量吧?由于文件描述符的值是从 0 开始,并且每次新建文件描述符时,新的描述符的值会在旧的值上自增 1,故只需要将文件描述符中最大值加一就能得到数量了,这也是为什么 maxfd 解释为最大文件描述符的值加 1 的原因。select 函数就是通过第一个参数 maxfd 知道要监视的文件描述符的数量的。
设置超时
函数的超时时间与函数的最后一个参数有关,其中 timeval 结构体定义如下:
struct timeval {
long tv_sec; //seconds
long tv_usec; //microseconds
}
本来 select 函数只有在监视的文件描述符发生变化时才返回,如果没有发生变化,则进入阻塞状态直到有变化发生。设定超时时间就是为了防止这种事情发生,只要设定了超时时间,即使文件描述符未发生变化,如果超过了超时时间,select() 函数就会返回,此时返回值为 0。如果不想设置超时,则传入 NULL,表示阻塞直到有变化发生。如果将 timeval 的两个成员都设置为 0,那么 select 将立即返回。
调用select函数后查看调用结果
我们先弄清楚一个问题,select() 函数是如何知道哪些文件描述符发生了变化呢?假设传入的某个 fd_set 如下:
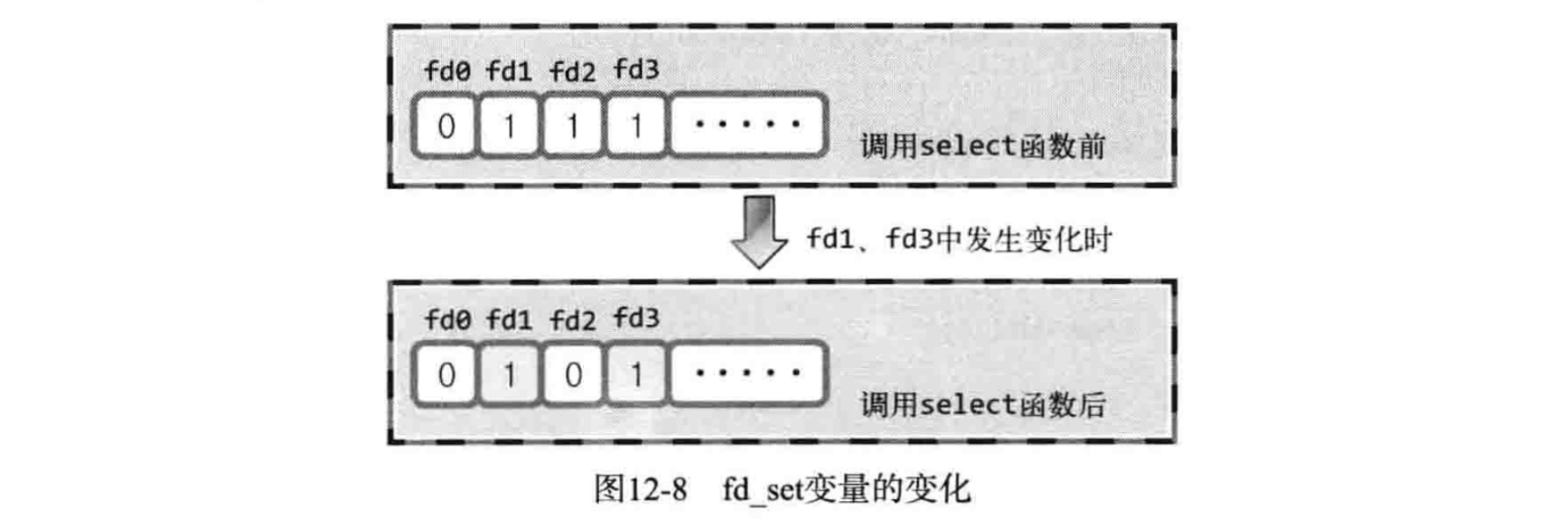
我们发现,调用 select() 函数后 fd_set 中的文件描述符除了发生变化的以外,其它的都被置为了 0,因此select() 函数就认为调用函数后值仍然为 1 的位置的文件描述符发生了变化。
select 成功时返回就绪(可读、可写、异常)的文件描述符的总数(三个参数的总数之和)。如果在超时时间内没有任何文件描述符就绪,那么 select 返回 0。如果 select 调用失败 那么返回 -1 并设置 errno。如果在 select 等待期间,程序接收到信号,则 select 立即返回 -1,并设置 errno 为 EINTR。
使用select()实现I/O复用服务端


select()的优缺点
优点
- 可移植性好
- 提供的超时值精度高(微妙级别)
- 相比于 fork(),select() 在一个进程里就可以完成与多个用户的交互,更轻量
缺点
- 单个进程可监视的文件描述符太少了,默认是 1024
- 需要维护一个用来存放大量fd的数据结构,而由于 select 会更改传入的 fd_set 集合,因此传入前需要复制一个副本用于传入,这样会使得用户空间和内核空间在传递该结构时复制开销大。
- select() 函数的超时参数在返回时也是未定义的,考虑到可移植性,每次在超时之后在下一次进入到 select 之前都需要重新设置超时参数。
- select 只能检测 fd 集合中是否发生变化,而不会反馈是哪个 fd 发生变化,因此 select 返回后需要依次遍历 fd_set 一一检查 fd 是否发生变化
- 找到发生变化的 fd 后的处理还是阻塞的,也就是处理当前 fd 时,后面的 fd 遍历就得暂停
文件描述符就绪条件
哪些情况下文件描述符可以被认为是可读、可写或者是出现异常,对于 select 的使用非常关键。在网络编程中,下列情况下 socket 可读:
- socket 内核接收缓冲区中的字节数大于或等于其低水位标记 SO_RCVLOWAT。此时我们可以无阻塞地读该 socket,并且读操作返回的字节数大于 0。
- socket 通信的对方关闭连接。此时对该 socket 的读操作将返回 0。
- 监听 socket 上有新的连接请求。
- socket 上有未处理的错误。此时我们可以使用 getsockopt 来读取和清除该错误。
下列情况下 socket 可写:
- socket 内核发送缓冲区中的可用字节数大于或等于其低水位标记 SO_SNDLOWAT。此时我们可以无阻塞地写该 socket,并且写操作返回的字节数大于 0。
- socket 的写操作被关闭。对写操作被关闭的 socket 执行写操作将触发一个 SIGPIPE 信号。
- socket 使用非阻塞 connect 连接成功或者失败(超时)之后。
- socket 上有未处理的错误。此时我们可以使用 getsockopt 来读取和清除该错误。
而 select 能处理的异常情况只有一种:socket 上接收到带外数据。
参考资料
- https://blog.csdn.net/zhougb3/article/details/79792089
- https://baike.baidu.com/item/select%E5%87%BD%E6%95%B0
- https://baike.baidu.com/item/select/12504672
- 《TCP/IP网络编程》第12章(I/O复用)