概述
软件安全特点
- 攻防性:攻防技术交替改进
- 配角性:安全是属性,安全不能脱离系统、应用或业务,安全是个形容词!
- 相对性:安全性是相对的,相对主题的需求而言
软件安全缺陷
- 软件自身缺陷,设计者故意或无意而导致
- 软件漏洞是基本形态、恶意代码则是延伸的形态
- 软件中的客观存在
软件安全威胁
- 外在的因素,过去曾经是或将来会成为攻击来源的个人、团体、组织或外部势力
- 威胁的例子包括:黑客、内部人员、罪犯、竞争情报从业者、恐怖分子和信息战士等
- 软件外主观存在
软件安全风险
- 内在的缺陷暴露在外在威胁下的状态即为风险
- 内在的缺陷遭遇外在威胁则形成安全事件
其它相关概念
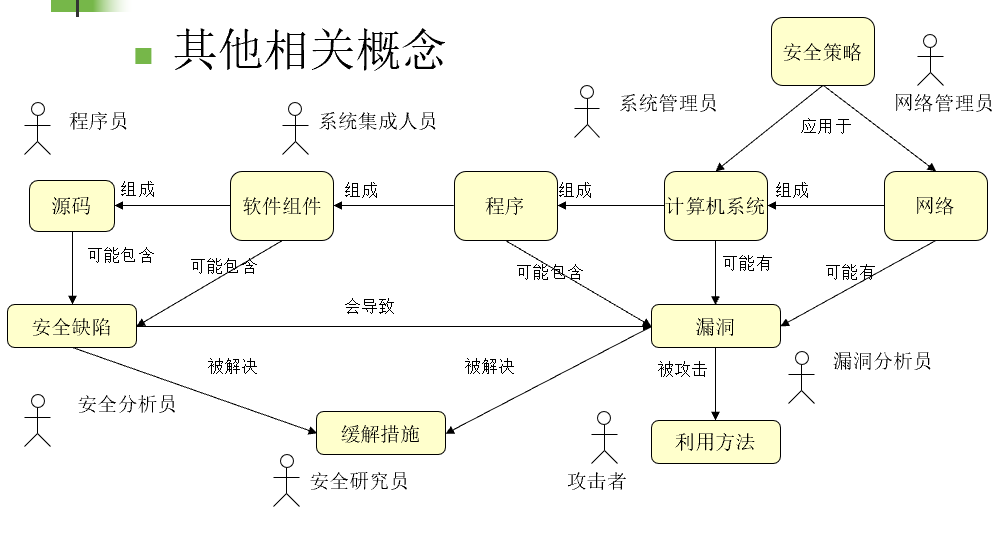
软件安全范围
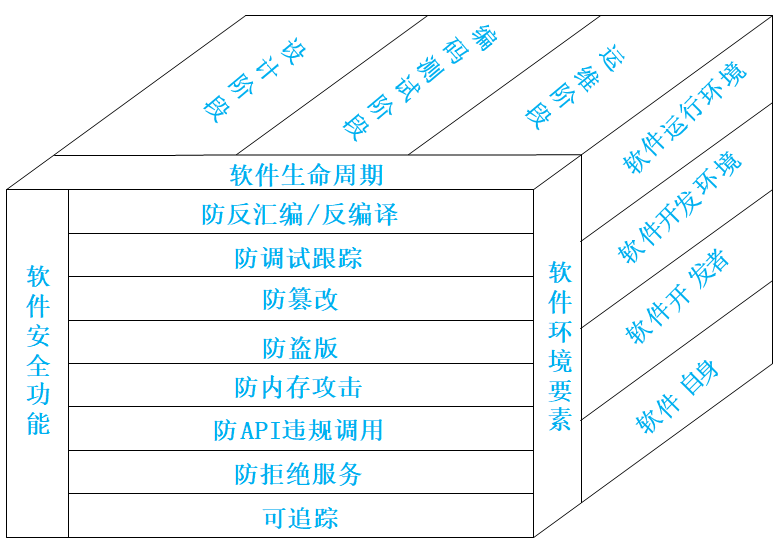
软件保护
- 软件分析(破解)
- 静态分析:控制流分析、数据流分析、数据依赖分析、别名分析、切片、抽象解析
- 动态分析:调试、剖分、跟踪、代码注入、HOOK、沙箱技术、反反调试
- 软件保护(反破解)
- 防逆向分析:代码混淆、软件水印、原生代码保护、资源保护、加壳、资源及代码加密
- 防动态调试:函数检测、数据检测、符号检测、窗口检测、特征码检测、行为检测、断点检测、功能破坏、行为占用
- 运行环境检测、反沙箱
- 数据校验:文件校验、内存校验
- 软件水印:静态水印、动态水印
软件风险
GaryMcgraw软件漏洞分类:
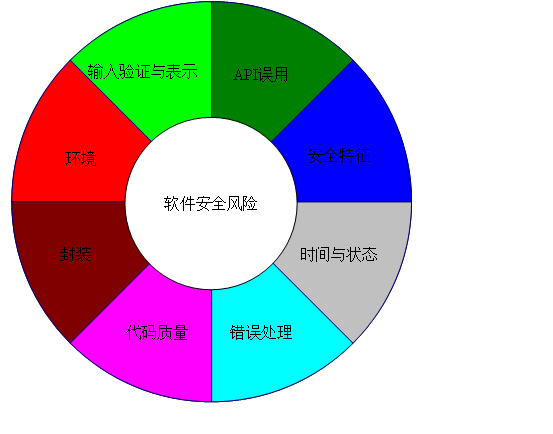
-
输入验证与表示
输入验证和表示问题通常是由特殊字符、编码和数字表示所引起的,这类安全问题的发生是对输入的信任所造成的
一些较严重的安全问题往往都是由于对输入的信息过度信任造成的,主要问题包括:





-
API误用
API误用是调用者与被调用者之间的一个约定,大多数的API误用是由于调用者没有理解约定的目的所造成的
API误用包括以下方面:
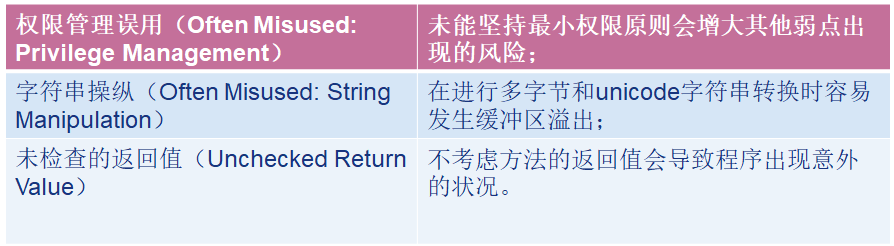
-
安全特征
安全特征主要是指认证,访问控制,机密性,密码,权限管理等方面的内容:
-
时间与状态
分布式计算是与时间和状态有关的。也就是说,为了让多个部件之间交互,需要状态共享,而这要花费时间。
大多数程序员将他们的工作人格化。他们认为控制器的一个线程会按照他们所想的方式来执行整个程序。然而,现在的计算机能在多任务之间快速切换,采用多核、多CPU或者说分布式系统,两个事件甚至能在同一时间发生。
这样一来,在程序员所想的程序执行模式和实际发生的情况之间就会产生问题。这些问题可能涉及到线程、进程、时间和信息之间的非法交互。这些交互通过共享的状态产生:如信号量、变量、文件系统以及任何能够存储信息的东西。
包括以下方面:
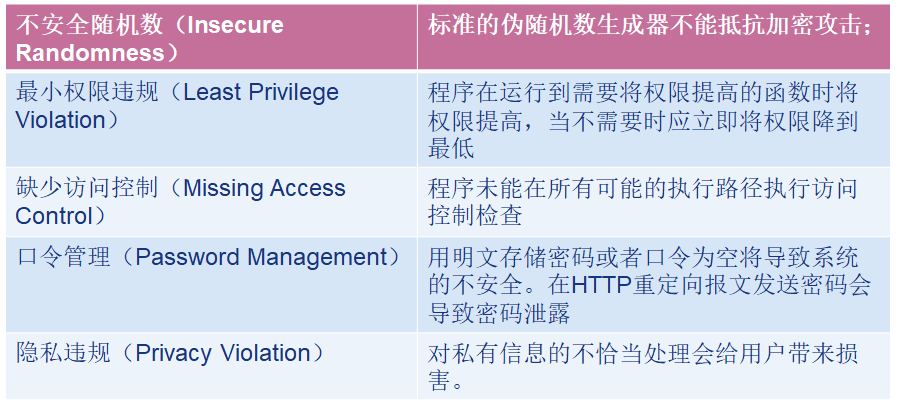
-
错误处理
错误和错误处理代表了一类API。与错误处理有关的错误是很常见的。与API误用相比,和错误处理相关的安全漏洞一般是两种方式造成的:
- 第一种是根本忘记处理错误或者只是简单的处理,并没有彻底解决
- 第二种则是程序对可能的攻击者泄露了过多的信息或者涉及面太广没有人愿意去处理这些问题
包括以下方面:
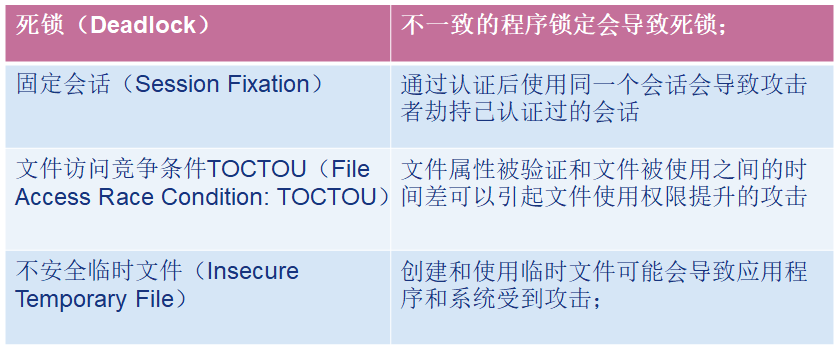
-
代码质量
低劣的代码质量会导致不可预测的行为。
从用户的角度来看,这通常会表现为低劣的可用性
对于攻击者而言,低劣的代码使他们可以以意想不到的方式威胁系统:
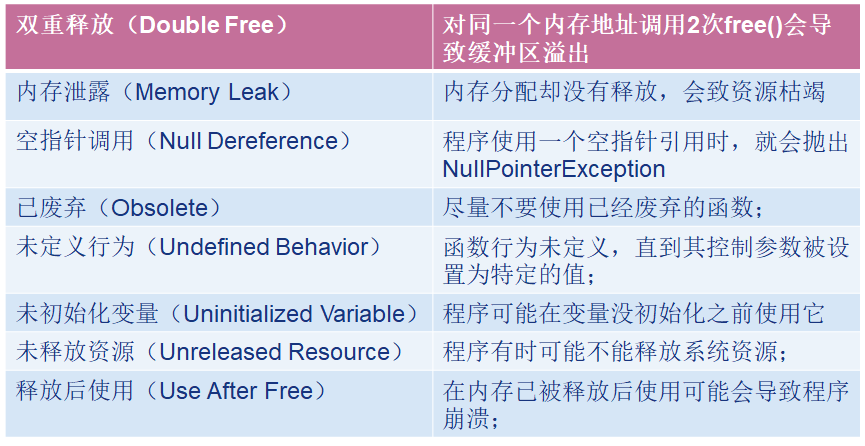
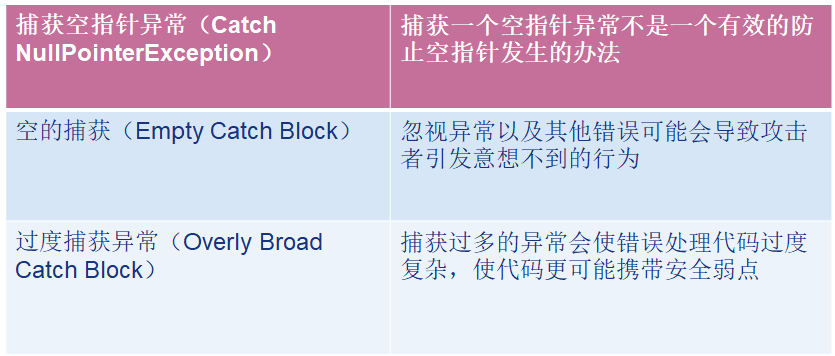
-
封装
封装就是划定强力的分界线。
在Web浏览器中,这就意味着你的代码模块不能被其它代码模块滥用。
在服务端,这意味着要区分校验过的数据和未经校验的数据,区分不同用户的数据,或者区分用户能看到的和不能看到的数据
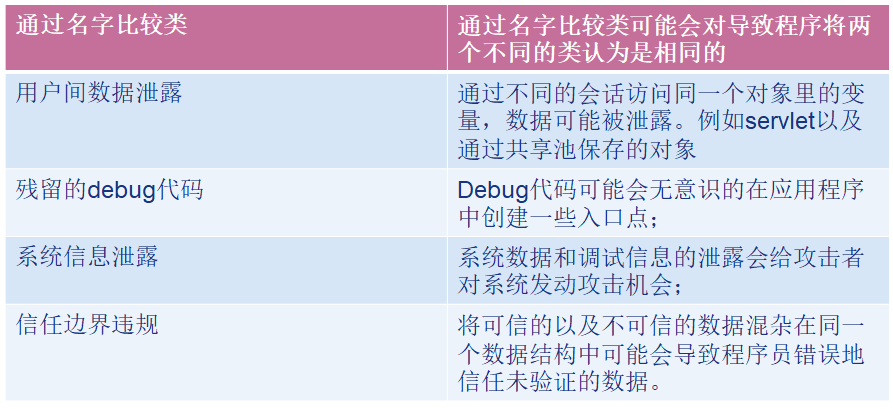
-
环境
环境包括的内容虽然是源代码之外的,但它们对产品的安全性仍然至关重要。因为其覆盖的内容并不与源代码直接相关,所以我们将它与其它内容分割开来
环境中可能存在风险例如:
- 不安全的编译器优化(Insecure Compiler Optimization)
- 不安全的传输(J2EE Miconfiguration:Insecure Transport)
- 弱访问许可(J2EE Misconfiguration: Weak Access Permissions)
- 配置文件中的密码(Password Management:Password in Configuration)
软件基础
计算机引导
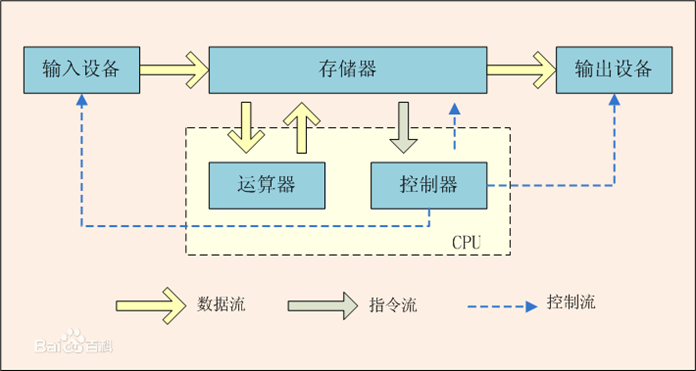
冯·诺依曼体系
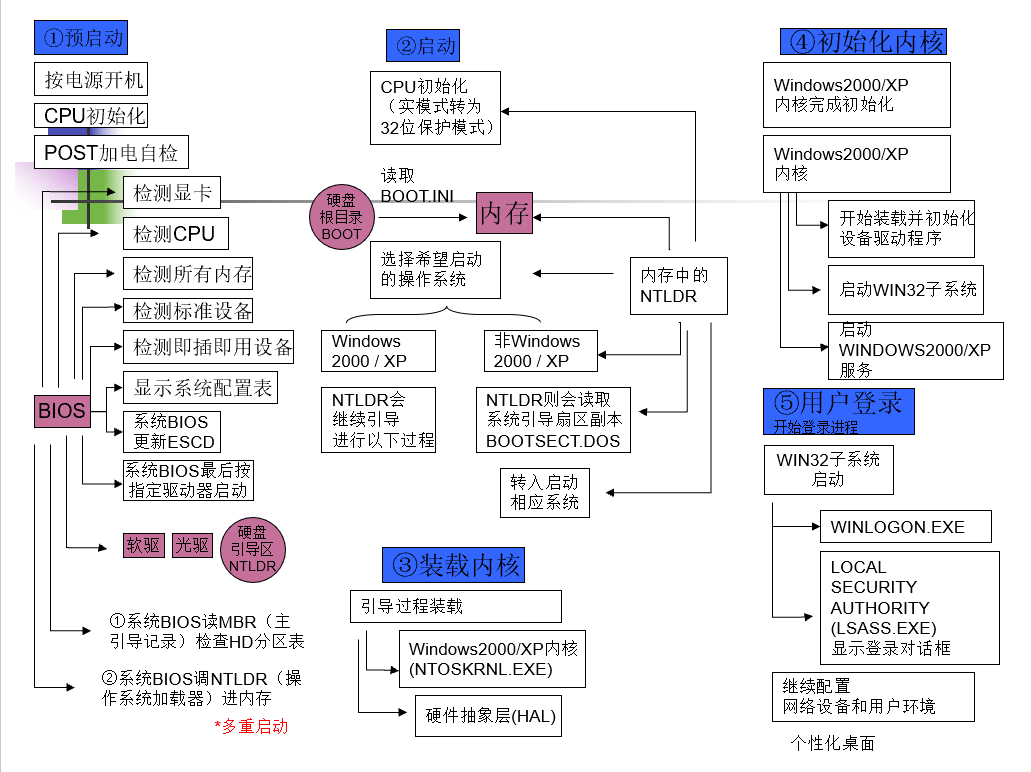
BIOS启动程序
-
打开计算机电源开关,处理器进入复位(Reset)状态
-
将所有内存清零,并执行内存同位测试
-
将段寄存器CS的内容设为FFFFH
-
其它寄存器都清零,IP=0000H
因此第一个要执行的指令是位于CS:IP中的指令,物理地址为0FFFF0H,所以将存储器的高地址分配给ROM BIOS,作为BIOS的入口地址
-
-
随后BIOS启动一个程序,进行主机自检
- 确保系统的每个部分都得到了电源支持,内存储器、主板上的其它芯片、键盘、鼠标、磁盘控制器及一些I/O端口正常可用
-
自检程序将控制权还给BIOS
- BIOS 读取 BIOS 设置,得到引导驱动器的顺序,依次检查
- BIOS 将所检查磁盘的第一个扇区(512B)载入内存,放在0x0000:0x7c00处,如果这个扇区的最后两个字节是”55AAH”,那么这就是一个引导扇区,磁盘也就是一块可引导盘,调用该驱动器上磁盘的引导扇区进行引导
-
系统加载程序
- 一旦BIOS将控制权移交给操作系统后,就可以向操作系统申请运行程序了
- 可执行的程序有两种:
*.com程序和*.exe程序
Windows系统启动过程
Win32内存体系
win32内存体系可以分为4大层次,速度由低到高分别是:外存、内存、高速缓存、寄存器
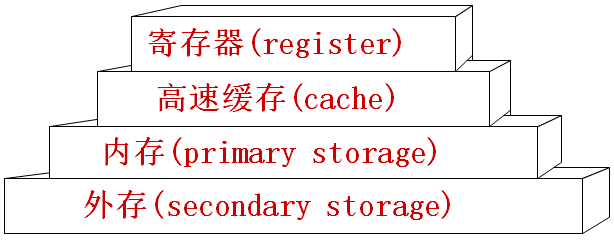
寄存器
Intel x86的寄存器可以分为以下几类:
- 32位通用寄存器有EAX、EBX、ECX、EDX、ESP、EBP、ESI和EDL
- 段寄存器:段寄存器被用于指向进程地址空间不同的段;CS指向一个代码段的开始;SS是一个堆段;DS、ES、FS、GS和各种其它数据段
- 程序流控制寄存器
- 其它寄存器
在通用寄存器里面有很多寄存器虽然他们的功能和使用没有任何的区别,但是在长期的编程和使用中,在程序员习惯中已经默认的给每个寄存器赋上了特殊的含义,比如:
- EAX一般用来做返回值
- ECX用于记数
- EIP:扩展指令指针
- ESP:扩展堆栈指针。这个寄存器指向堆栈的当前位置,并允许通过使用push和pop操作或者直接的指针操作来对堆栈中的内容进行添加和移除
- EBP:扩展基指针。主要用与存放在进入call以后的ESP的值,便于退出的时候回复ESP的值,达到堆栈平衡的目的
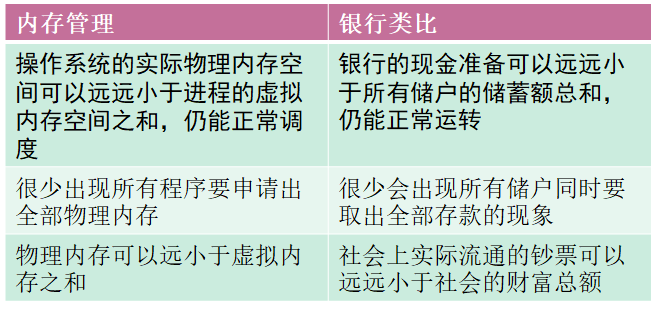
虚拟内存
Windows内存被分为两个层面:物理内存和虚拟内存。其中物理内存比较复杂,需要进入Windows内核级别ring0才能看到。
通常在用户模式下,我们用调试器看到的地址都是虚拟内存
虚拟内存与物理内存的映射
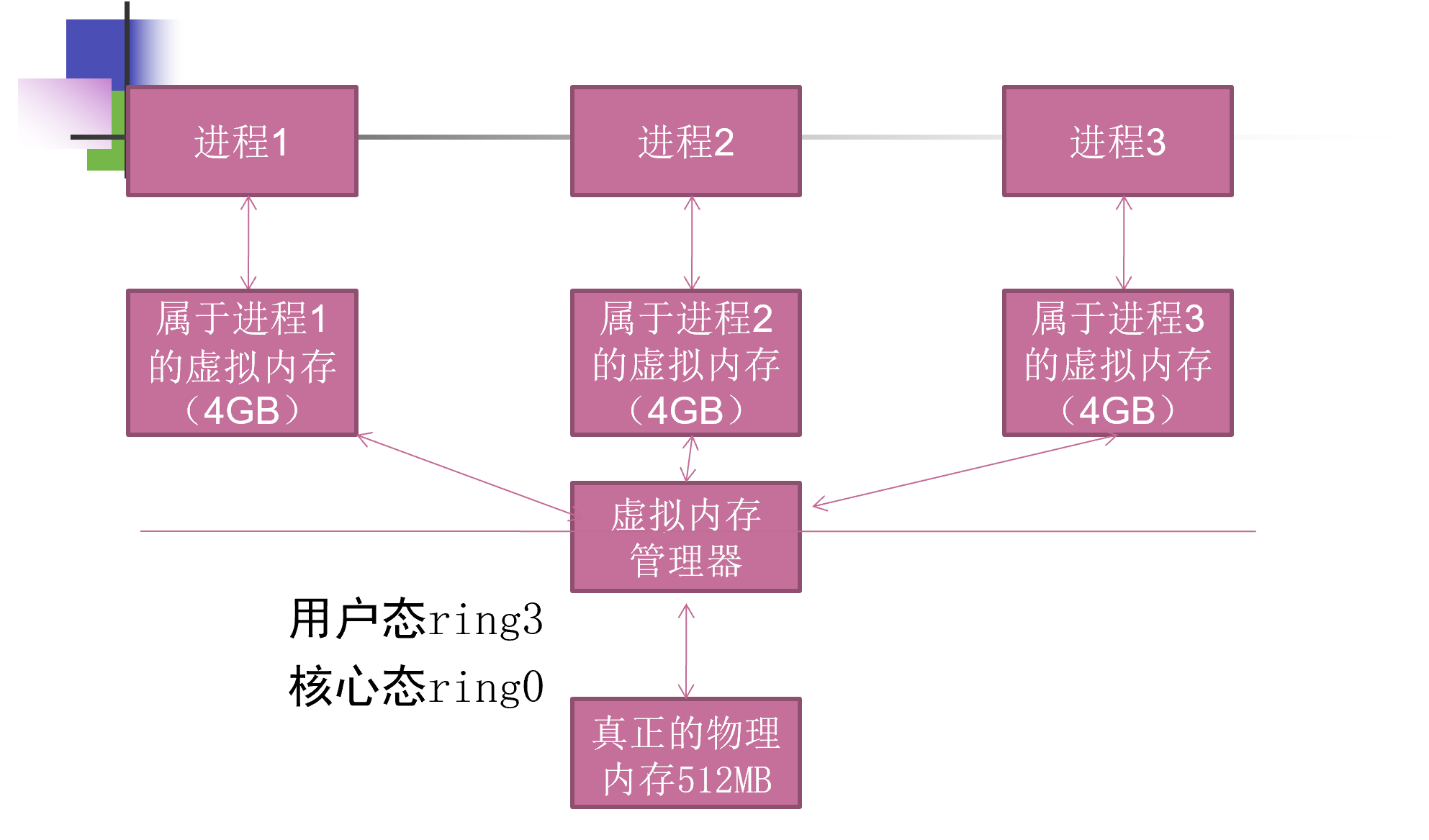
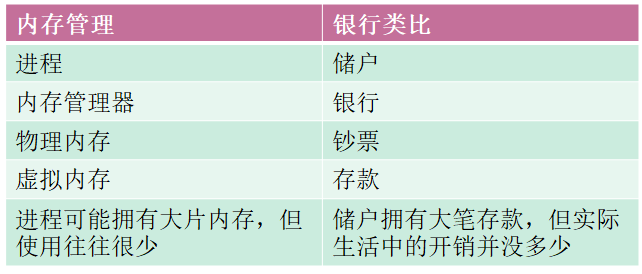
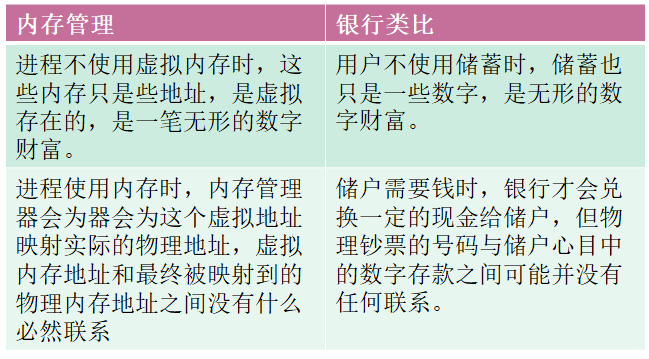
内存管理与银行的类比
PE文件结构
定义
PE(Portable Executable)是Win32平台下可执行文件遵守的数据格式。常见的可执行文件(如*.exe文件和*.dll文件)都是典型的PE文件。
作用
一个可执行文件不光包含了二进制的机器代码,还包含了许多其它信息如字符串、图标、位图等。
PE文件格式规定了所有的这些信息在可执行文件中如何组织。在程序被执行时,操作系统会按照PE文件格式的约定去相应的地方准确地定位各种类型的资源,并分别装入内存的不同区域
PE文件格式
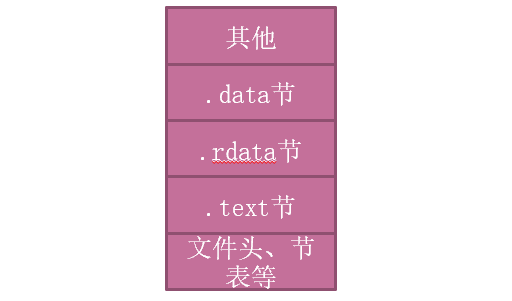
PE文件格式把可执行文件分成了若干个数据节(section),不同的资源被放在不同的节中。一个典型的PE文件包含的节如下:
-
.text 由编译器产生,存放着二进制的机器代码,也是我们反汇编和调试的对象
-
.data 初始化的数据块,如宏定义、全局变量、静态变量等
-
.idata 可执行文件所使用的动态链接库等外来函数与文件的信息
-
.rsrc 存放程序的资源,如图标、菜单等
-
除此之外,还可能出现的节包括“
.reloc”、“.edata”、“
.tls”、“.rdata”等
简单构成:
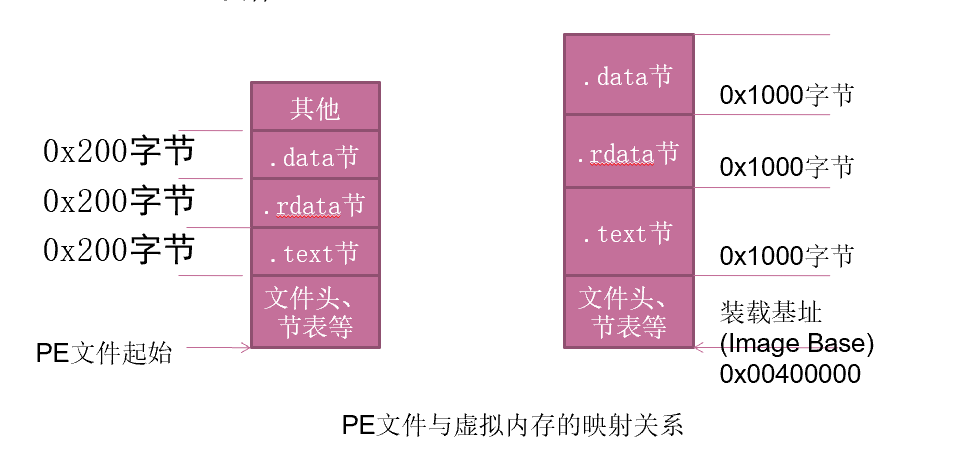
PE文件与虚拟内存之间的映射
静态反汇编工具看到的PE文件中某条指令的位置是相对于磁盘文件而言的,即所谓的文件偏移,我们可能还需要知道这条指令在内存中所处的位置,即虚拟内存的位置
反之,在调试时看到的某条指令的地址是虚拟内存地址,我们也经常需要回到PE文件中找到这条指令对应的机器码
我们首先要清除几个概念:
-
文件偏移地址(File Offset)
数据在PE文件中的地址叫做文件偏移地址。这是文件在磁盘上存放时相对于文件开头的偏移
-
装载基址(Image Base)
PE装入内存时的基地址。默认情况下,EXE文件在内存中的基地址是0x00400000,DLL文件是0x10000000。这些可以通过修改编译选项更改
-
虚拟内存地址(Virtual Address,VA)
PE文件中的指令被装入内存后的地址
-
相对虚拟地址(Relative Virtual Address,RVA)
相对虚拟地址是内存地址相对于映射基址的偏移量
-
VA = Image Base + RVA
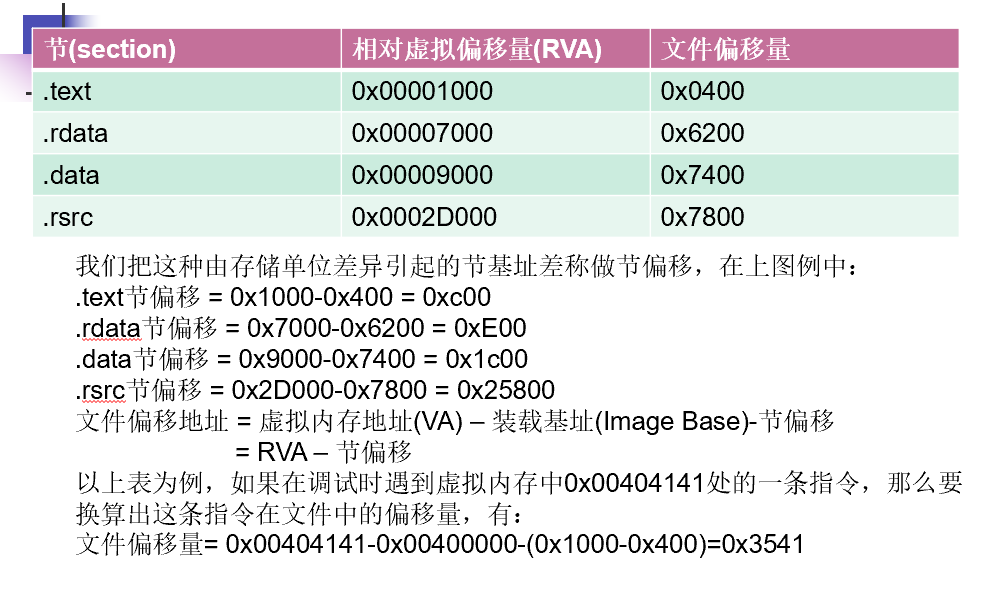
文件偏移地址在与它们计算时还需要考虑存放方式的不同:
-
当代码装入内存后,将按照内存数据标准存放,并以0X1000字节为基本单位进行组织。类似的,不足将被补全,若超出将分配下一个0x1000为其所用。因此,内存中的节总是0x1000的整数倍
-
节偏移:由上可得,节偏移就是基本单位中补全的块大小。补全用了多少字节,就说明下一节相对于原来的位置偏移了多少字节!
就拿上面的例子来说,
.text字段的文件偏移量为0x0400,但是RVA却为0x01000,这说明前面0x1000字节有0x1000-0x400=0xc00字节数据是用来补全的,目的就是为了让一个存储单位的大小是0x1000的整数倍!
进程空间分区
进程空间的功能分区

把计算机类比成一个工厂

栈区
从计算机科学的角度来看,栈指的是一种数据结构,是一种先进后出的数据表。
栈的最常见操作有两种:压栈(PUSH)、弹栈(POP);
用于标识栈的属性也有两个:栈顶(TOP)、栈底(BASE)。

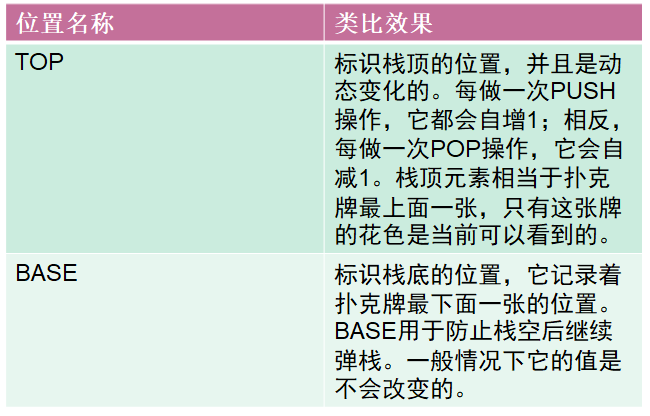
系统栈
内存的栈区实际上指的就是系统栈。系统栈由系统自动维护,它用于实现高级语言中函数的调用。对于类似C语言这样的高级语言,系统栈的PUSH/POP等堆栈平衡细节是透明的。
一般说来,只有在使用汇编语言开发程序的时候,才需要和它直接打交道。
系统栈工作
栈帧
每一个函数独占自己的栈帧空间。当前正在运行的函数的栈帧总是在栈顶。Win32系统提供两个特殊的寄存器用于标识位于系统栈顶端的栈帧:
- ESP:栈指针寄存器(extended stack pointer),其内存放着一个指针,该指针永远指向系统栈最上面的一个栈帧的栈顶
- EBP:基址指针寄存器(extended base pointer),其内存放着一个指针,该指针永远指向系统栈最上面的一个栈帧的底部


ESP与EBP的使用:
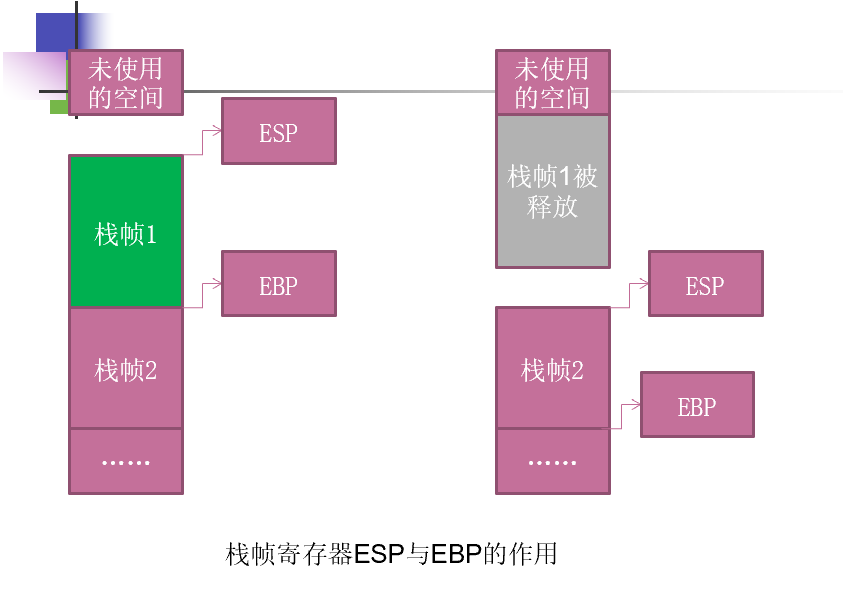
在函数栈帧中,一般包含以下几类重要信息:
- 局部变量:为函数局部变量开辟的内存空间。
- 栈帧状态值:保存前栈帧的底部,前栈帧的顶部可以通过堆栈平衡计算得到,用于在本帧被弹出后恢复出上一个栈帧。
- 函数返回地址:保存当前函数调用前的“断点”信息,也就是函数调用前的指令位置,以便在函数返回时能够恢复到函数被调用前的代码区中继续执行指令。
一个至关重要的寄存器
EIP:指令寄存器(Extended Instruction Pointer),其内存放着一个指针,该指针永远指向一条将要执行(当前运行指令的下一条指令)的指令地址。
可以说如果控制了EIP寄存器的内容,就控制了进程—我们让EIP指向哪里,CPU就会去执行哪里的指令。
函数调用
函数调用大致包括以下几个步骤:
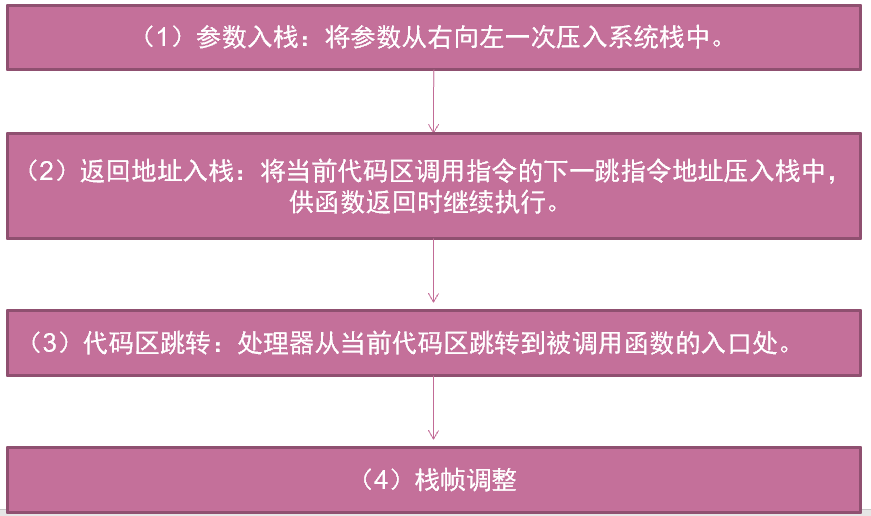
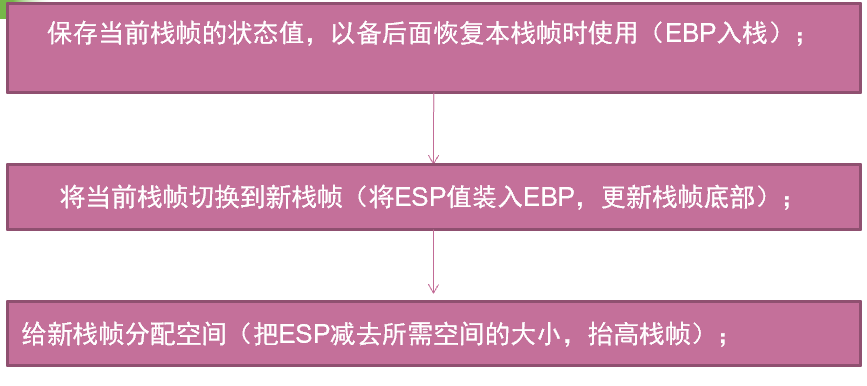
其中,第四步栈帧调整具体又分为如下几个步骤:
stdcall调用约定
对于stdcall调用约定,函数调用时用到的指令序列大致如下:
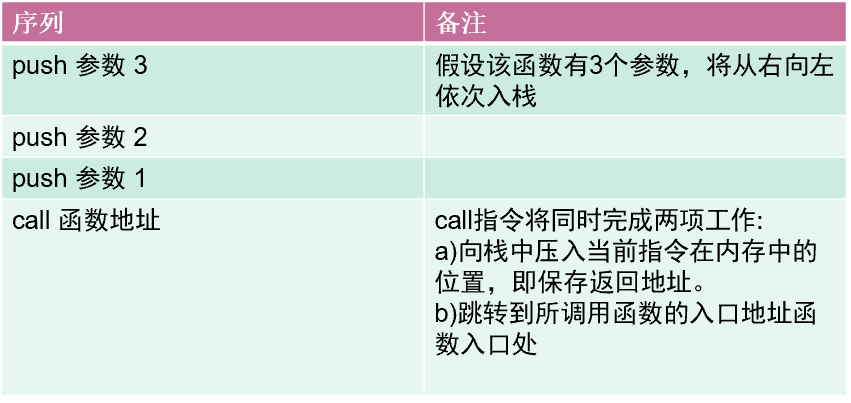

函数调用时系统栈的变化过程
- 压参数入栈
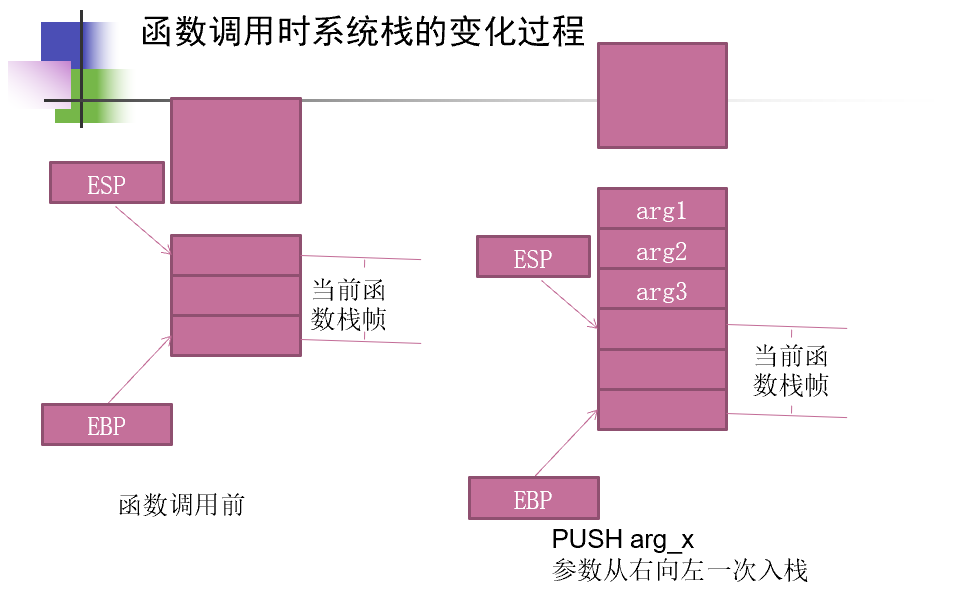
- call指令和push ebp
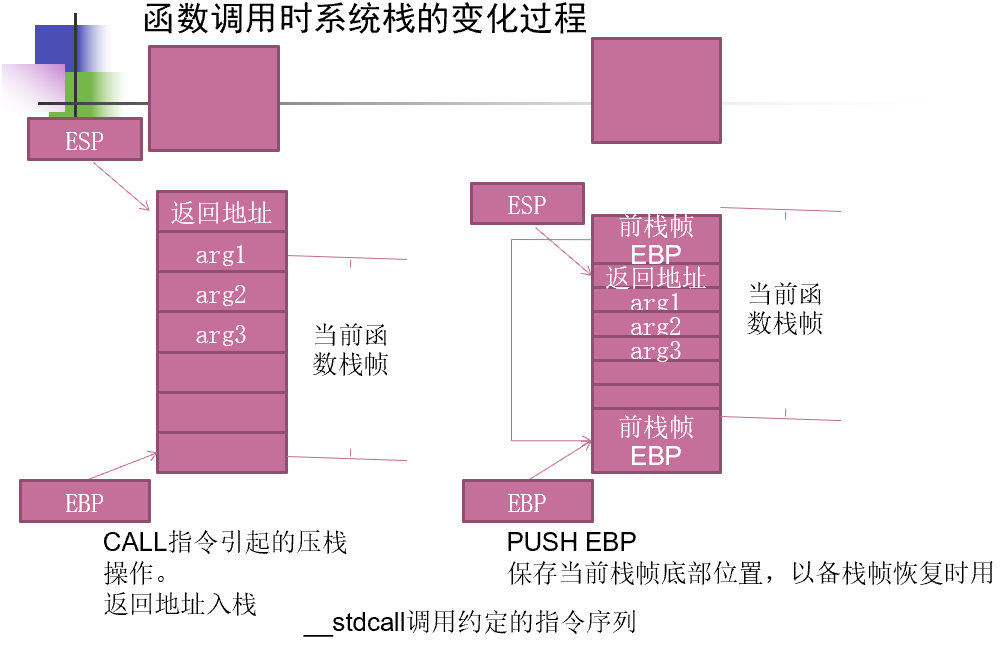
- 保存旧栈帧,开辟新栈帧
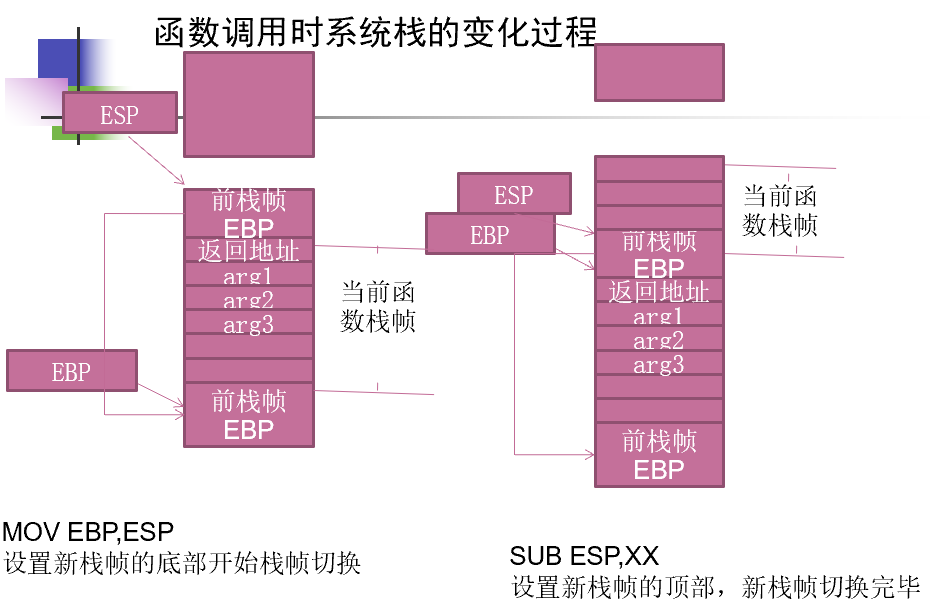
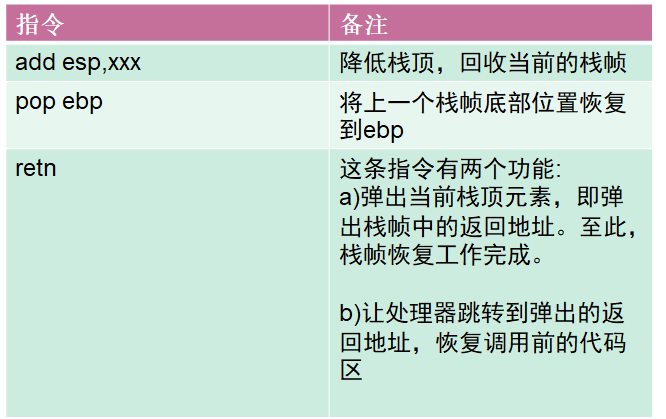
函数返回
与函数调用类似:
- 保存返回值:通常将函数的返回值保存在寄存器EAX中。
- 弹出当前栈帧,恢复上一个栈帧,具体包括:
- 在堆栈平衡的基础上,给ESP加上栈帧的大小,降低栈顶,回收当前栈帧的空间
- 将当前栈帧底部保存的前栈帧EBP值弹入EBP寄存器,恢复上一个栈帧
- 将函数返回地址弹给EIP寄存器
- 跳转:按照函数返回地址跳回母函数中继续执行。
相关指令
字符串安全
字符串基础
C-风格的字符串
在软件工程中,字符串是一个基本的概念,但它并不是C或C++的内建类型。

C++字符串

常见的字符串操作错误
在C和C++中,使用C风格的字符串编程很容易产生错误。最常见的错误有:
-
无界字符串复制
从一个无界数据源复制数据到一个定长的字符数组时
问题:

解决:利用strlen() 测试输入字符串的长度然后动态分配内存
-
空结尾错误
字符串末尾没有空字符
NULL
-
截断
当目标字符数组的长度不足以容纳一个字符串的内容时,就会发生字符串截断。
字符串截断会丢失数据,有时也会导致软件漏洞
解决:一些限制字节数的函数通常用来防止缓冲区溢出漏洞:
- strncpy() 代替strcpy()
- fgets()代替 gets()
- snprintf()代替 sprintf()
-
差一错误
差一错误(英语:Off-by-one error,缩写OBOE)是在计数时由于边界条件判断失误导致结果多了一或少了一的错误

-
数组写入越界

-
不恰当的数据处理
字符串漏洞
缓冲区溢出
什么是缓冲区溢出
当向为某特定数据结构分配的内存空间边界之外写入数据时, 就会发生缓冲区溢出。
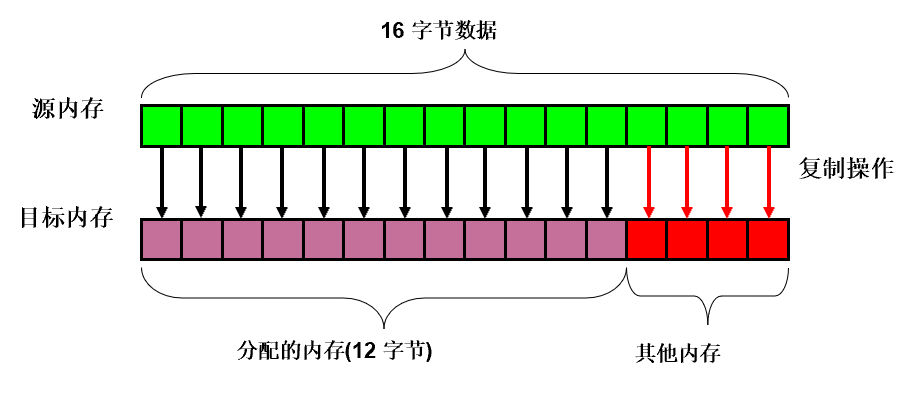
可通过修改下列参数来利用缓冲区溢出:
- 变量
- 数据指针
- 函数指针
- 栈返回地址
栈粉碎
这是一种很严重的漏洞,因为它会对程序的可靠性和安全性造成严重的后果
当缓冲区溢出覆写分配给执行栈内存中的数据时,就会导致栈粉碎
成功的利用这个漏洞能够覆写栈返回地址,从而在目标机器中执行任意代码
弧注入(return-into-libc)
- 弧注入将控制转移到已经存在于程序内存空间中的代码中
- 弧注入的利用方式是在程序的控制流“团”中插入一段新的“弧”(表示控制流转移),而不是进行代码注入
- 可以安装一个已有函数的地址(如system()或exec()),用于执行已存在于本地系统上的程序
代码注入
-
攻击者创建一个恶意参数
一个蓄意构造的字符串,其中包含一个指向某些恶意代码的指针,该代码也由攻击者提供。
- 当函数返回时,控制就被转移到了那段恶意代码
- 注入的代码就会以与该有漏洞的程序相同的权限运行
- 攻击者通常都以“以root或其他较高权限运行”的程序为目标
- 恶意参数的特征
- 必须被漏洞程序作为合法输入接受
- 参数,以及其他可控输入必定导致了漏洞代码路径的执行
- 在控制权转移到恶意代码之前,参数不能导致程序非正常终止。
- 恶意参数的目的是把控制权转移给恶意代码,出于这个原因, 被注入的恶意代码通常被称为shellcode
缓解措施
缓解措施包括:
- 预防缓冲区溢出
- 侦测缓冲区溢出并安全地恢复,使得漏洞利用的企图无法得逞
防范策略:
- 静态分配空间
- 动态分配空间
静态方法

-
输入验证:确保输入数据的大小不超过其存储的最小缓冲区
-
采用一个更不容易出错的方式来复制和连接:
strlcpy()和strlcat()


-
ISO/IEC “Security” TR 24731


目标:

动态方法

防范策略:SafeStr


示例:

管理字符串

黑名单

白名单

指针安全
定义
指针安全是通过修改指针值来利用程序漏洞的方法的统称
可以通过覆盖函数指针将程序的控制权转移到攻击者提供的外壳代码
对象指针也可以被修改,从而执行任意代码
缓冲区溢出覆写指针的条件
- 缓冲区与目标指针必须分配在同一个段内
- 缓冲区必须位于比目标指针更低的内存地址处
- 该缓冲区必须是界限不充分的,因此容易被缓冲区溢出利用
UNIX可执行文件包含data段和BSS段;
data段包含了所有已初始化的全局变量和常数;
BSS( Block Started by Symbols )段包含了所有未初始化的全局变量;
已初始化的全局变量和未初始化变量分开是为了让汇编器不将未初始化的变量内容写入目标文件
示例:

修改指令指针

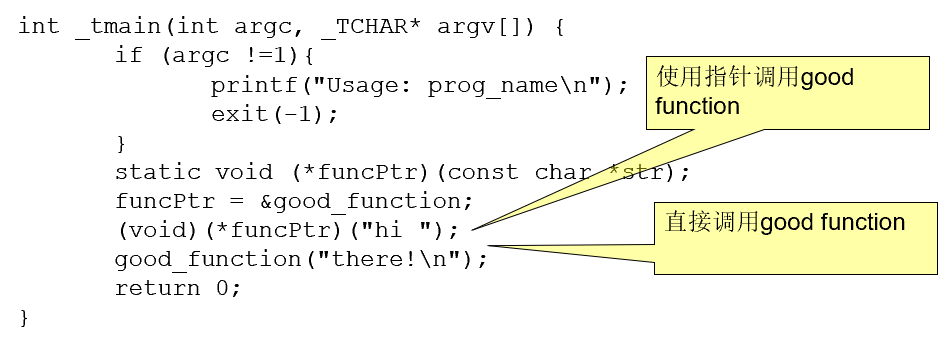



全局偏移表
Global Offset Table(GOT)
- 被包含在ELF的二进制文件的进程空间里
- GOT表存放绝对地址
- 对动态链接起至关重要的作用
- 程序首次使用一个函数前,GOT入口项包含运行时连接器RTL(runtime linker)的地址
- 如果该函数被程序调用,则程序的控制权被转移到RTL,然后函数的实际地址被确定且被插入到GOT中
- 接下来就可以通过GOT中的入口项直接调用函数

如何利用GOT
-
攻击者需要有自己的shellcode
-
攻击者需要能够向任意地址写入任意值
-
开始攻击:
攻击者用自己的shellcode地址覆写将要被调用的GOT地址
.ctors区 & .dtors区


- 攻击者可以通过覆写.dtors区中的函数指针的地址从而将程序控制权转移到任意的代码
- 如果攻击者能够读取到目标二进制文件,那么通过分析ELF映像,很容易就能确定要覆写的确切位置
- 即使没有指定任何析构函数.dtors区仍然存在
- 在这种情况下,.dtors区中只含有头、尾标签而中间没有函数地址
- 仍然可以通过将尾标签0x00000000覆写为攻击者提供的外壳代码的地址,从而将控制转移过去
- 如果外壳代码返回,则进程将会继续调用接下来的函数直到遇到尾标签或发现错误为止
覆写.dtors区的优缺点
对于攻击者而言,覆写.dtors区的好处在于:
- 该区总是存在并且会映射到内存中
然而:
- .dtors仅存在于用GCC编译和链接的程序中
- 有时候,很难找到合适的外壳代码注入点,使得在main()退出后外壳代码仍然能够驻留在内存中
虚函数
定义
虚函数是在某基类中声明为 virtual 并在一个或多个派生类中被重新定义的成员函数
虚函数是:
- 类成员函数
- 用virtual关键字声明
- 可由派生类中的同名函数重写
- 函数调用在运行时解析
实现
虚函数表VTBL:
- 虚函数表Virtual Function Table 是一个函数指针数组,用于在运行时派发虚函数调用
- VTBL含有指向虚函数的每一个实现的指针
虚指针VPTR:
- 在每一个对象的头部,都包含一个指向VTBL的虚指针VPTR(Virtual Pointer)
攻击
攻击者可以:
- 覆写VTBL中的函数指针或者
- 改写VPTR使其指向其它任意的VTBL
攻击者可以通过任意内存写或者利用缓冲区溢出直接写入对象实现这一操作
atexit() & on_exit()
atexit()
- C99定义的通用工具函数
- 可以注册无参函数,并在程序正常结束后调用该函数
- C99要求实现支持至少32个函数的注册
on_exit()
- 在SunOS下的相似功能
- 也存在libc4,libc5,glibc
用法
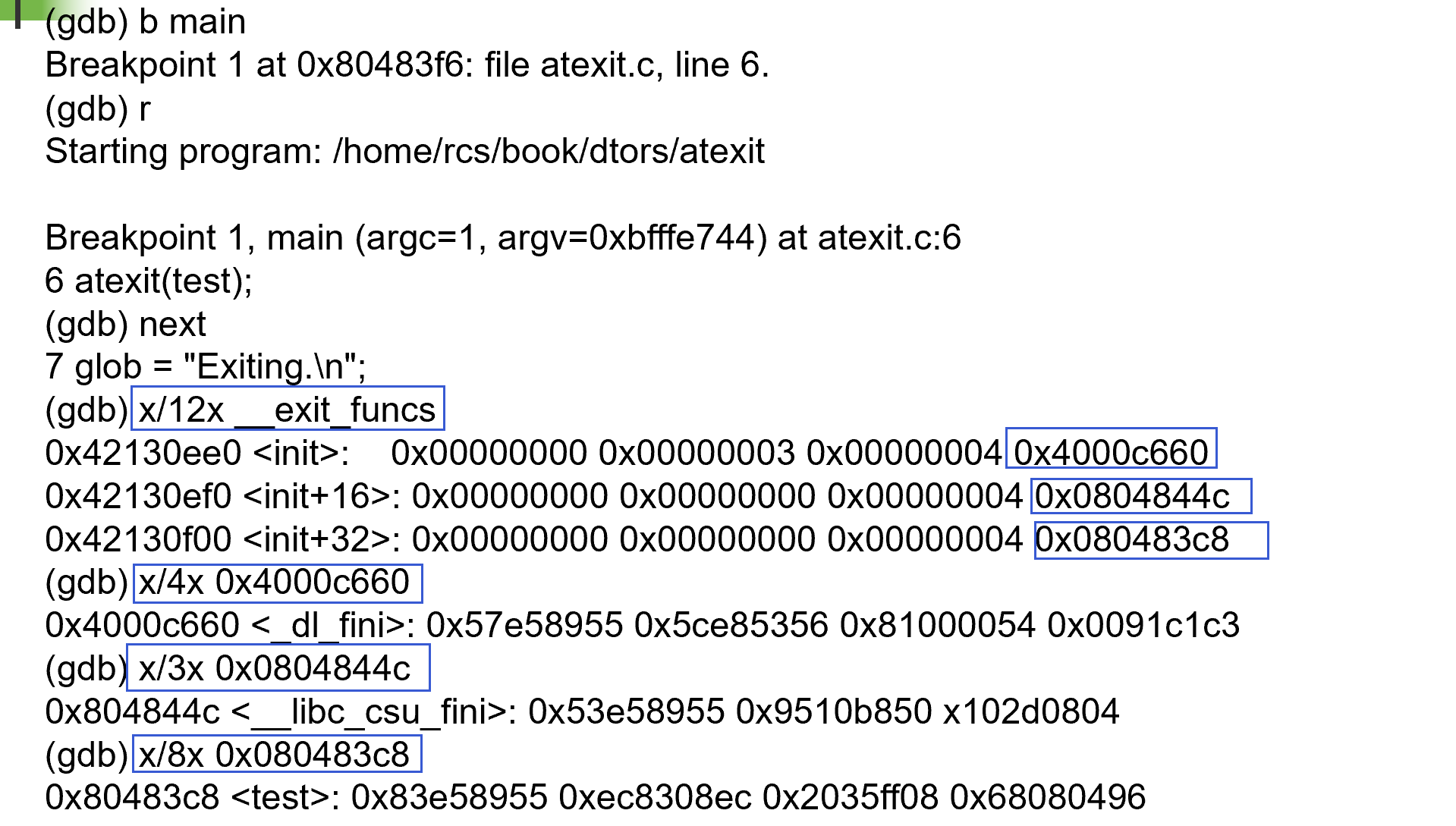
- atexit()通过向一个退出时将被调用的已有函数数组中添加指定的函数完成工作
- exit()以后进先出(Last-in, First-out, LIFO)的顺序调用函数
- 数组被分配为全局性的符号
__atexitin BSD__exit_funcsin Linux
示例



longjump()

异常处理
异常是指函数操作中发生的意外情况
Windows提供了3种形式的异常处理程序:
- 向量化异常处理 Vectored Exception Handling (VEH)
- Windows XP增加了对这种异常处理程序的支持
- VEH首先调用以重写SEH
- 构化异常处理 Structured Exception Handling (SEH)
- 被实现为每函数或每线程的异常处理程序
- 系统默认异常处理 System Default Exception Handling
SEH

栈帧初始化

攻击者可以:
-
覆写异常处理程序地址
-
替换Thread Environment Block(TEB)中的指针
-
TEB包含已注册的异常处理程序列表
攻击者仿造一个列表入口作为攻击代码的一部分;利用任意内存写技术修改第一个异常处理程序域
-
尽管最新Windows已经加入了列表入口有效性检验功能,但似乎仍可能攻击成功
-
-
Windows为进程提供了一个全局异常处理过滤器和处理程序,往往为整个进程实现一个未处理异常过滤器,如果攻击者利用任意内存写技术覆写了某特定内存地址,则未处理异常过滤器可以被重定向去执行任意代码
动态内存管理
动态内存的程序员视角
动态内存函数




动态内存管理器


内存分配的不同算法
- 连续匹配:从当前指针位置开始查询匹配的第一个空闲区域
- 最先匹配:从内存开始位置寻找第一个空闲区域
- 最佳匹配:有m个字节的区域被选中,其中m是(或其中一个)可用的最小的等于或大于n个字节的连续存储的块
- 最优匹配:对空闲块取样,选取第一个比样本更合适的块
- 最差匹配:挑最大的空闲块
- 伙伴系统:伙伴系统只分配 $2^i$大小的块。若需要m大小的块,则分配$2^{[log_bm]+1}$或者更大的块;当块返回时,尝试和它相邻的同样大小的块合并
- 隔离:保持单独的大小一致的块的列表
常见错误
初始化错误


未检查返回值




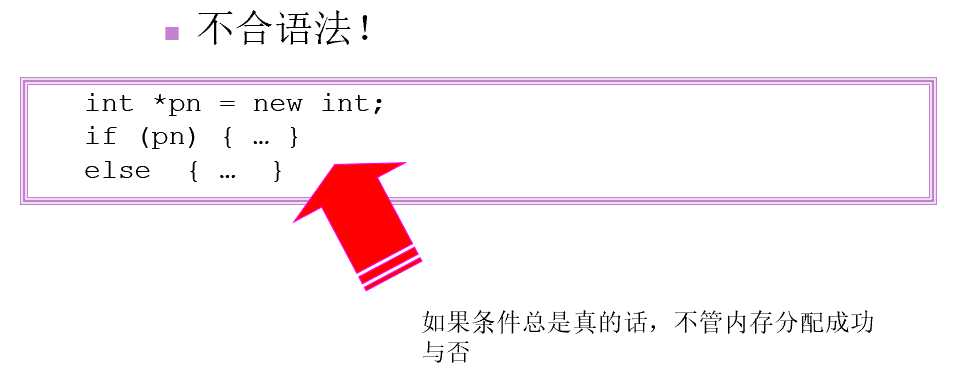
引用已释放内存

对同一块内存释放多次


不正确配对的内存管理函数

未能区分标量和数组

分配函数使用不当

Doug Lea内存分配器
该分配器在gcc和大多数的Linux版本中都是默认;表述均针对dlmalloc 2.7.2版。但是其中包含的安全缺陷原理是所有版本都具有的
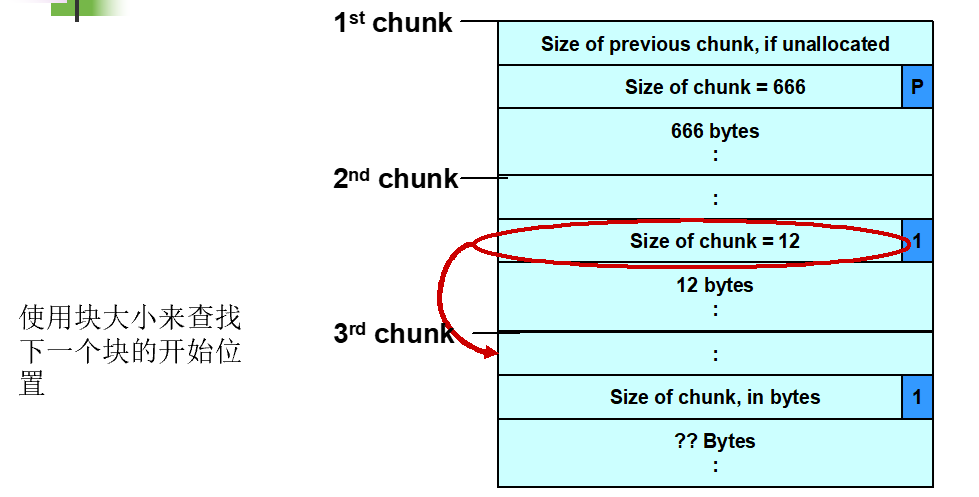
内存块结构
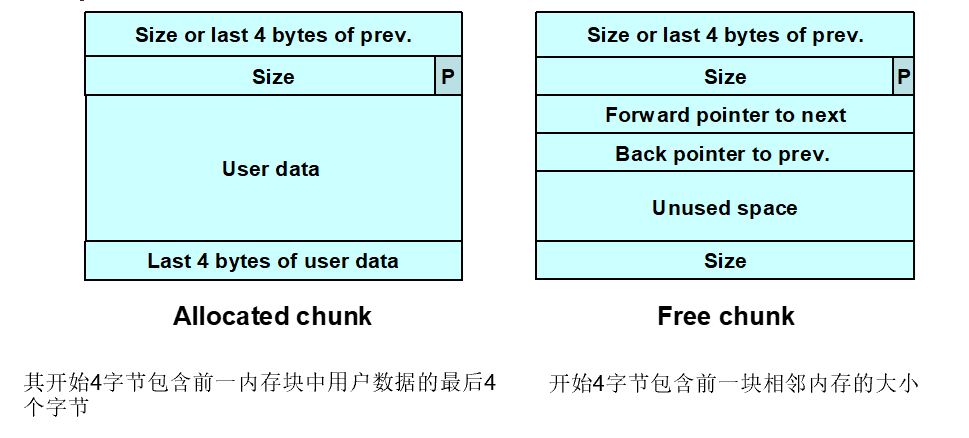
空闲块
- 以双链表形式组织起来
- 包含指向下一块的前向指针和指向上一块的后向指针
- 最后4字节存有该块的大小
已分配块和空闲块都使用一个PREV_INUSE位区分:
- 块大小总是偶数,PREV_INUSE位被存储于块大小的低位中
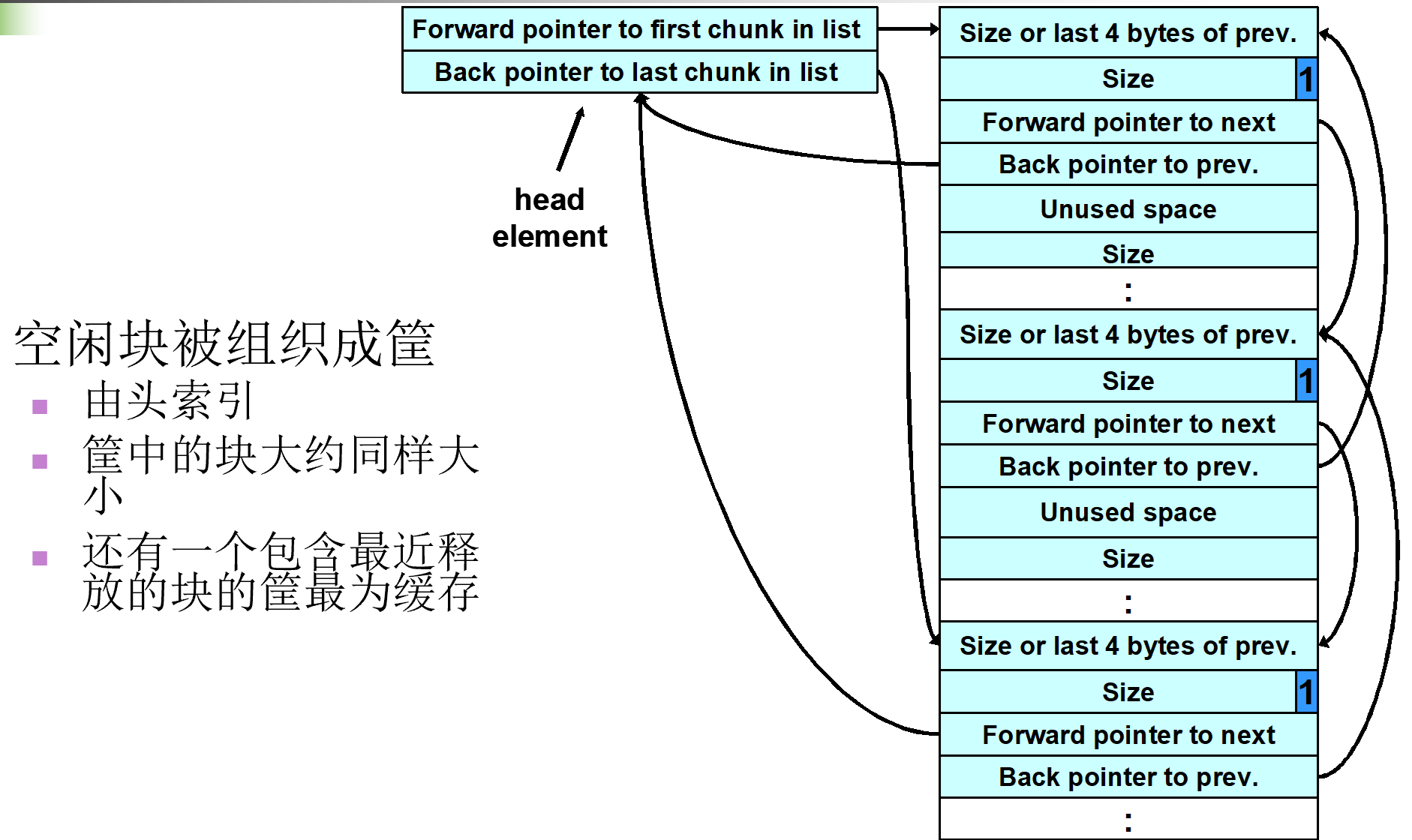
Unlink技术
在free()时,内存块如果满足条件会被合并:
- 被释放块的上一块为空闲块:上一块被从空闲双链表中解开,与被释放的块合并
- 被释放的下一块为空闲块:也从双链表中解开,并于被释放块合并
Unlink宏
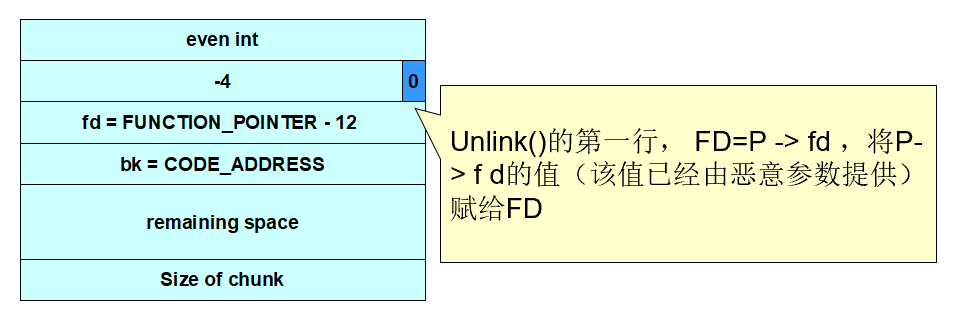
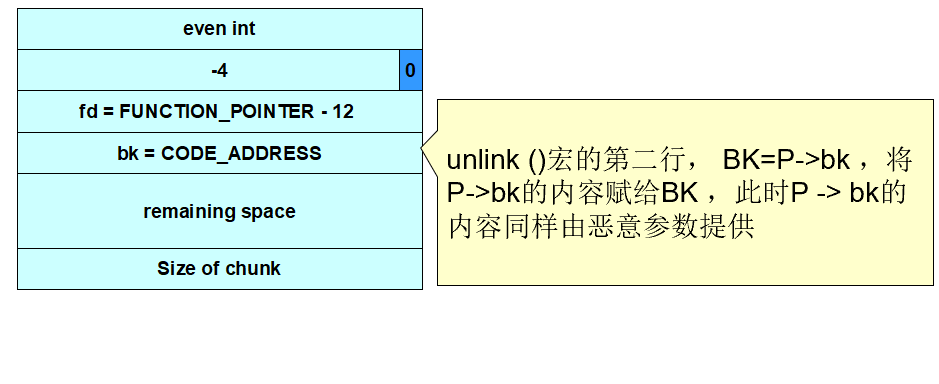
#define unlink(P, BK, FD) {
FD = P->fd;
BK = P->bk;
FD->bk = BK;
BK->fd = FD;
}
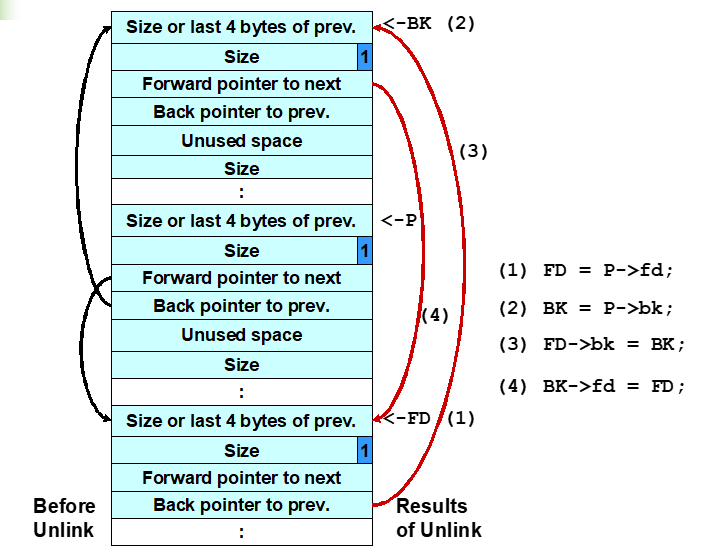
解链技术
即unlink技术,由Solar Designer提出,被成功用来攻击多个版本的Netscape浏览器、traceroute和slocate这些使用了dlmalloc的程序
利用缓冲区溢出来操作内存块的边界标志:
- 欺骗unlink宏向任意地址写入4字节数据
漏洞程序示例
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[]) {
char *first, *second, *third;
first = malloc(666);//内存分配块1
second = malloc(12);//内存分配块2
third = malloc(12);//内存分配块3
strcpy(first, argv[1]); //无界strcpy操作引发缓冲区溢出
free(first);
free(second);
free(third);
return(0);
}
分析:
-
程序第9行释放第一块内存块。如果此时第二块内存处于未分配状态,free()操作会试图将其与第一块合并
-
我们的目的是要调用unlink宏,所以必须要合并,但是第二块却是已分配的内存块,咋办呢
-
继续分析,为了判断第二块内存是否处于空闲状态,free()会检查第3块的PREV_INUSE标志位
-
如果我们改写该标志位呢?改写后就可以欺骗free()了,如何改写?
-
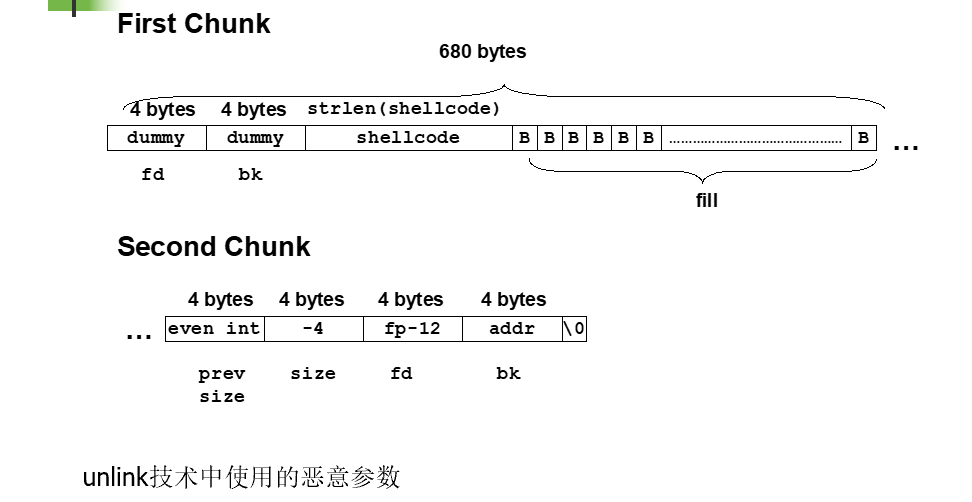
在程序开始时,内存是连续分配的,所以内存地址逻辑上是连续的,而第一块内存又存在缓冲区溢出,所以可以覆写第二块内存块
-
把第2块内存的size覆写为-4,这样当free()需要确定第3块内存地址时,就会将第2块内存起始地址加上其大小,导致得到的值是其位置减4,同时标志位也被置空
-
Doug Lea的malloc此时会错误地认为下一连续内存块是自第2块内存前面4字节开始(把第2块当作第3块)
-
输入字符串进行缓冲区溢出
-
执行unlink宏
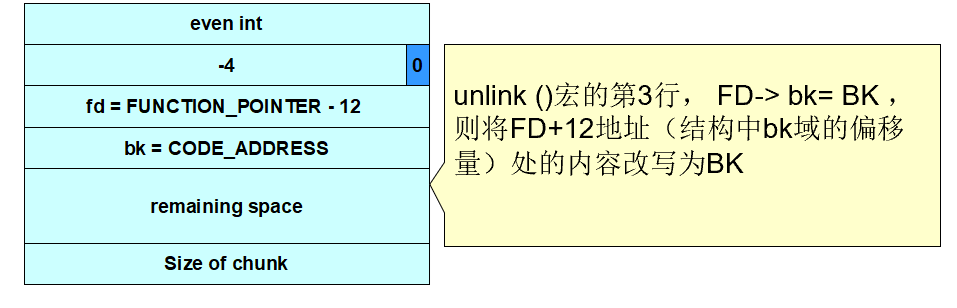
此时覆写已经完成,不用管第4步的结果了
-
unlink()宏将攻击者提供的4个字节的数据(CODE_ADDRESS)写到同样是由攻击者指定的4个字节的地址(FUNCTION_POINTER)处
一旦攻击者可以在任意地址处写入4字节数据,利用该漏洞程序本身的权限执行任意代码就变得简单多了
- 攻击者可能会提供栈中指令指针的地址,然后利用unlink()宏将该地址覆写为恶意代码的地址
- 将漏洞程序调用的函数的地址替换为恶意代码的地址
- 攻击者可以检查程序的可执行映像,找到free()函数的调用跳槽(jump slot )地址
- address-12处的值包含在恶意参数中,因此unlink()宏会将free()库函数调用地址覆写为shellcode的地址
- 每当程序调用free()时都会转而执行shellcode
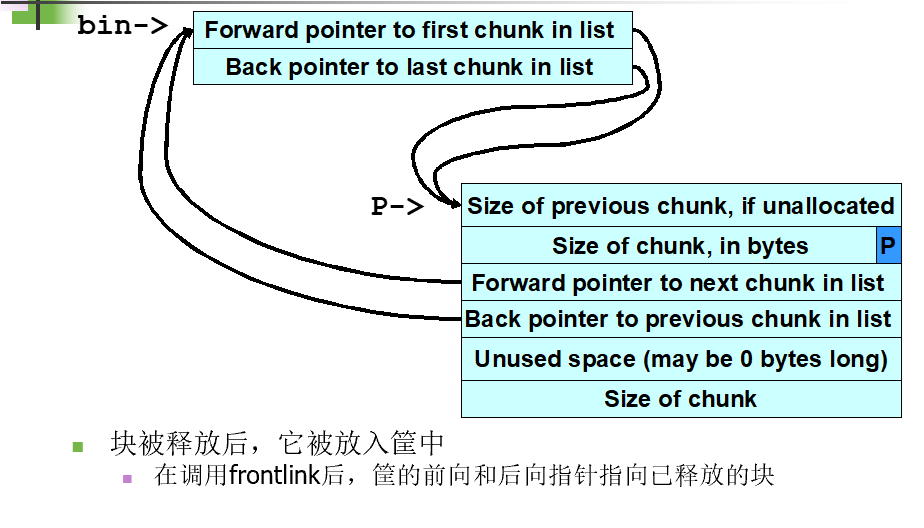
Frontlink技术
与unlink是解链相比,frontlink则相反,是构造链表,但是却更难以利用也更危险!
当一块内存被释放时,它必须被正确地链接进双链表中。而在dlmalloc的某些版本中,此项操作是由frontlink()代码段来完成的
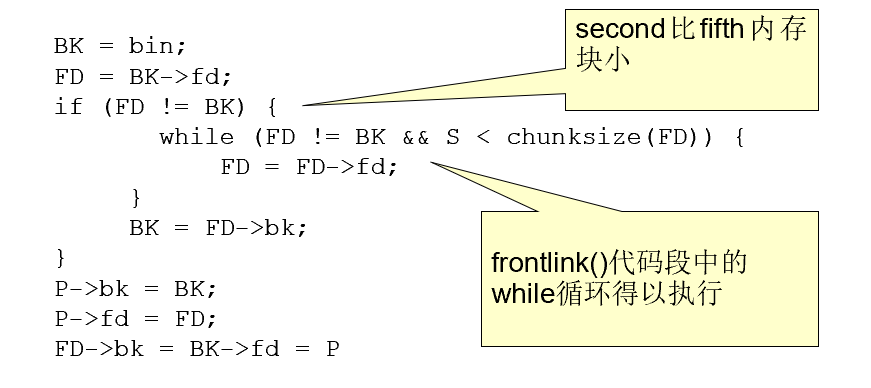
代码段
BK = bin;
FD = BK->fd;
if (FD != BK) {
while (FD != BK && S < chunksize(FD)) {
FD = FD->fd;
}
BK = FD->bk;
}
P->bk = BK;
P->fd = FD;
FD->bk = BK->fd = P
漏洞程序示例
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
int main(int argc, char *argv[])
{ if (argc !=3){
printf("Usage: prog_name arg1 \n");
exit(-1);
}
char *first, *second, *third;
char *fourth, *fifth, *sixth;
first = malloc(strlen(argv[2]) + 1);
second = malloc(1500);
third = malloc(12);
fourth = malloc(666);
fifth = malloc(1508);
sixth = malloc(12);
strcpy(first, argv[2]); //无界copy
free(fifth);
strcpy(fourth, argv[1]);//无界copy
free(second);
return(0);
}
-
首先攻击者提供恶意实参

-
代码第17行将argv[2]复制到first内存块
-
代码第18行当fifth内存块被释放时,它被放入一个匡中(大于1024)
-
代码第19行出现缓冲区溢出,fourth被精心设计的数据(argv[1]) 填满,并且fifth的前向指针指向了一个假的内存块
-
这个假的内存块的后向指针为一个函数指针的地址减8(一个合适的函数指针是存储于程序
.dtors区中的第一个析构函数的地址,这个地址可以通过检查可执行映像获得) -
第20行当second块被释放时,程序将调用frontlink()代码段将其插入到与fifth块相同的匡中(因为大于1024)
-
执行frontlink代码

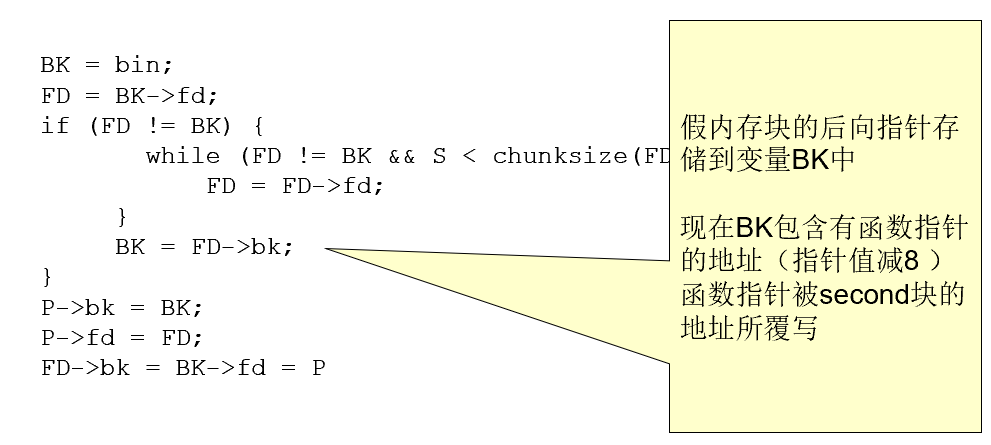
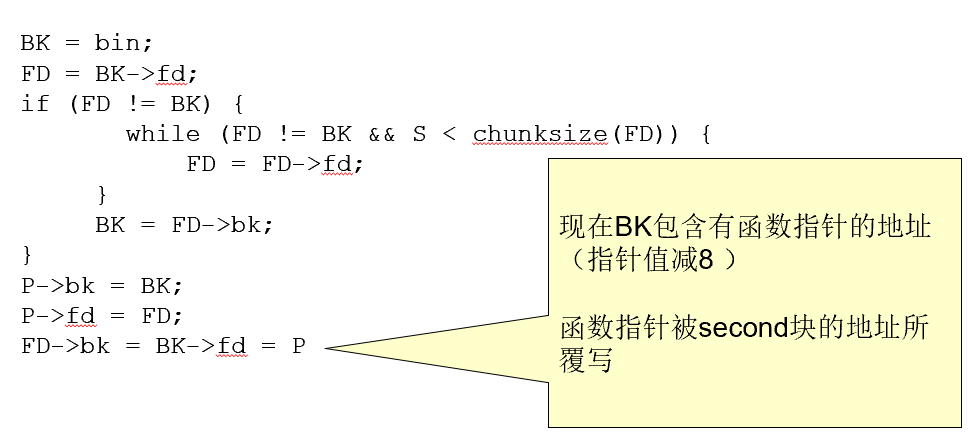
此时frontlink已经完成了地址覆写的任务(覆写析构函数为shellcode)
-
程序调用return(0)触发析构函数

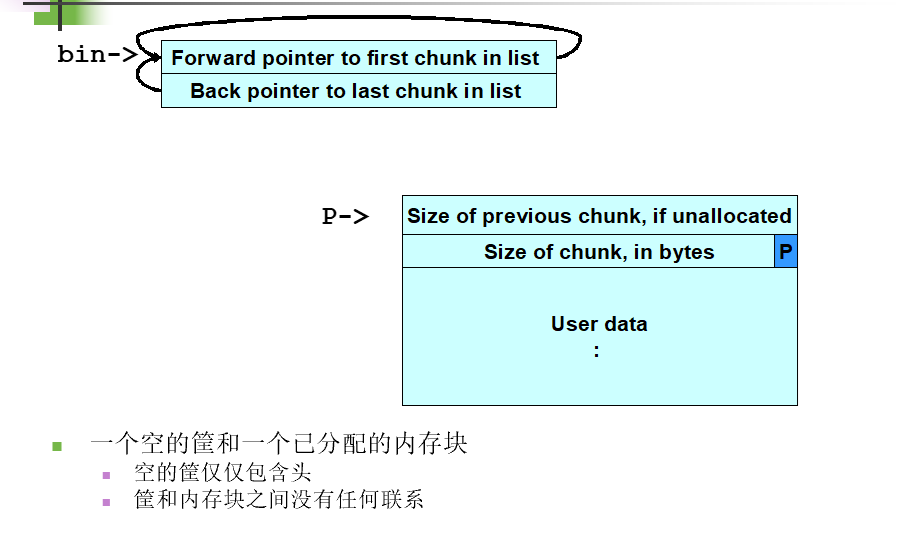
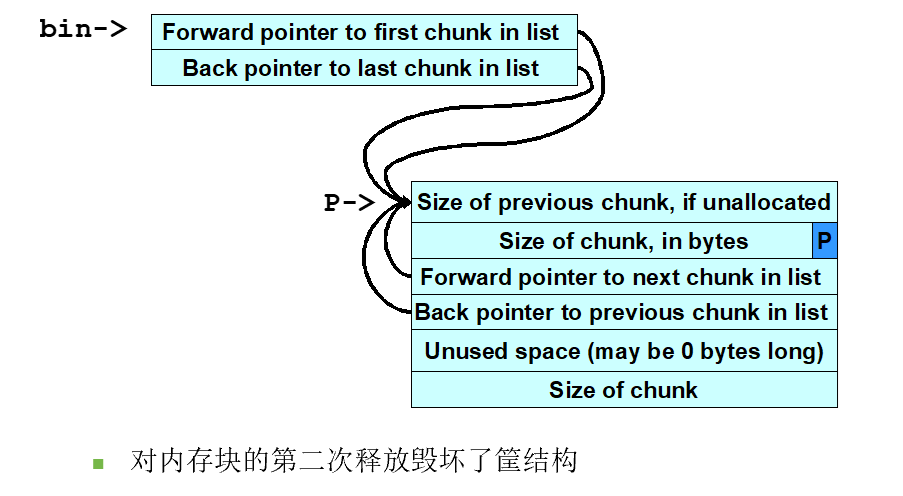
双重释放漏洞
这种类型的漏洞是由于对同一块内存释放两次所造成的(在这两次释放之间没有对内存进行重新分配)
要成功地利用双重释放漏洞,有两个条件必须满足:
- 被释放的内存块必须在内存中独立存在
- 该内存所被放入的筐(bin)必须为空
漏洞原理

RtlHeap
-
RTL – Run Time Library
-
使用虚拟内存API
-
实现了更高级的局部、全局和CRT内存函数
Win32内存管理API
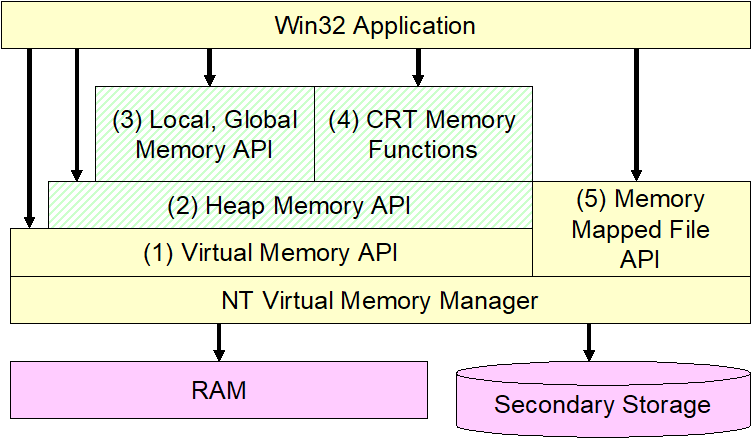
虚拟内存API
-
32位地址
-
4KB页
-
用户地址空间分区域
保护方式、类型以及每页的基分配方式
堆内存API
- 允许用户建立多个动态堆
- 每一个进程都有一个默认堆
局部内存API和全局内存API
- 需要向后兼容Windows 3.1
CRT内存函数
- C 运行时
内存映射文件API
- 内存映射文件允许一个应用程序将其虚拟地址空间直接映射到磁盘上的一个文件
需要理解的RTL数据结构:
- 进程环境块
- 空闲链表、look-aside链表
- 内存块的结构
进程环境块

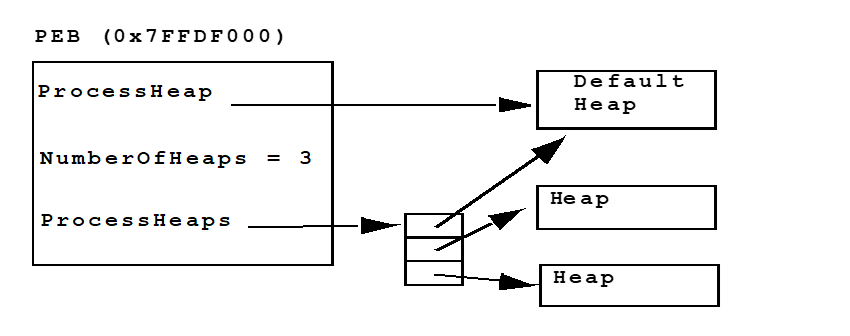
空闲链表
-
有128个双向链表的数组
- 位于堆起始(也就是调用HeapCreate()返回的地址)偏移0x178处
-
这个链表被RtlHeap用来跟踪空闲内存块
-
Freelist[]是一个LIST_ENTRY结构的数组
-
每一个LIST_ENTRY表示一个双链表的头部
LIST_ENTRY结构定义于winnt .b中
由一个前向链接( flink )和一个后向链接( blink )组成
-
空闲链表举例


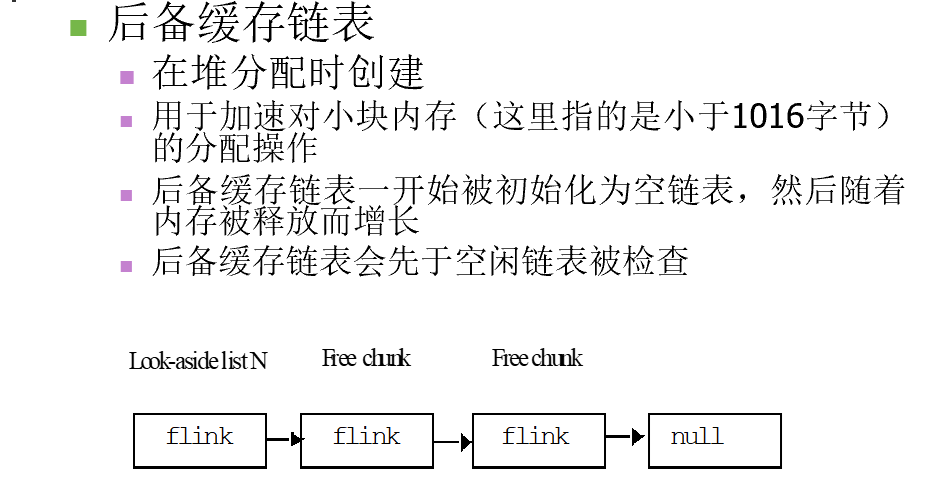
后备缓存链表

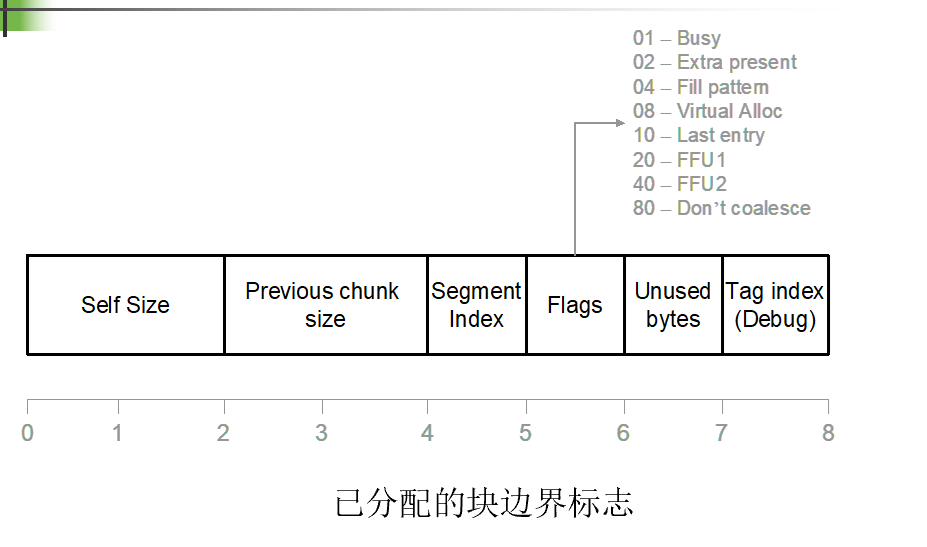
边界标志



基于堆的缓冲区溢出攻击
- 通常需要改写双链表结构中的前向和后向指针
- 在正常的堆处理过程中覆写地址,从而修改程序的执行流程
更容易的方法
- 通过覆写异常处理器地址获取控制
- 引发异常
缓解策略








整数安全
整数表示方法
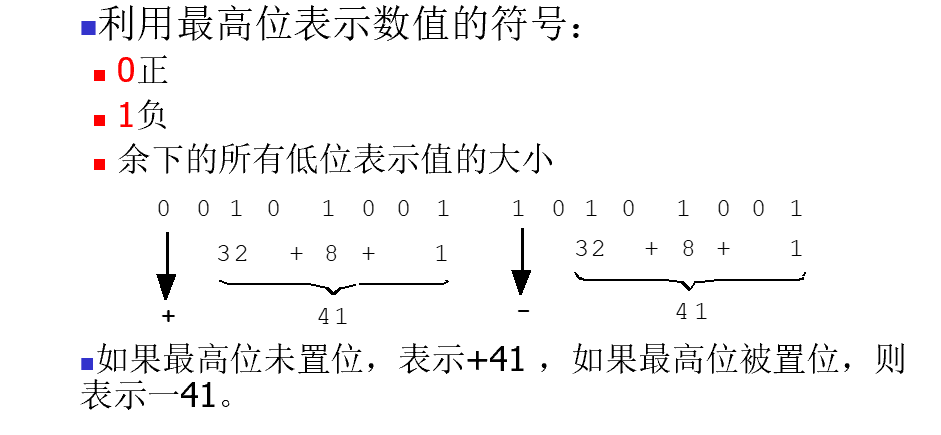
- 原码表示法
- 反码表示法
- 补码表示法
- 对整数表示法而言,需要考虑的问题主要就是负数的表示
原码表示法
反码表示法
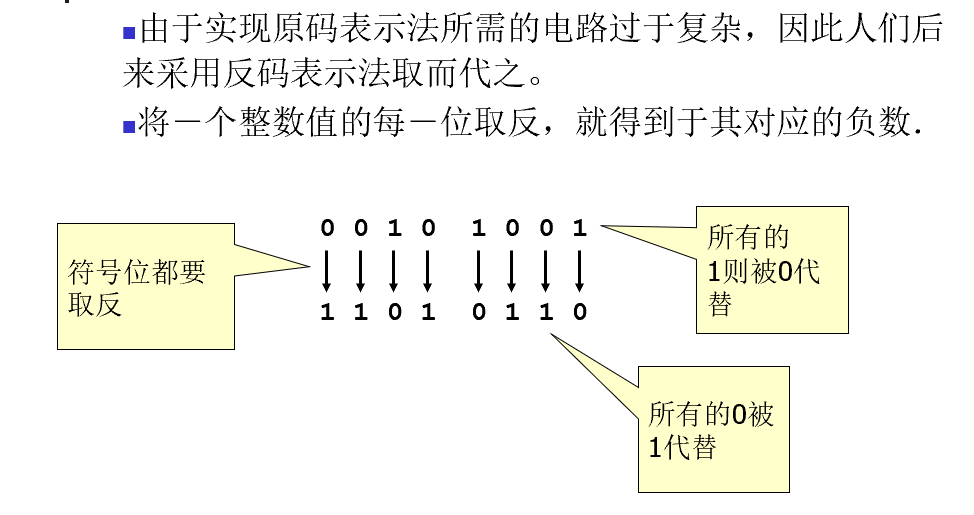
补码表示法
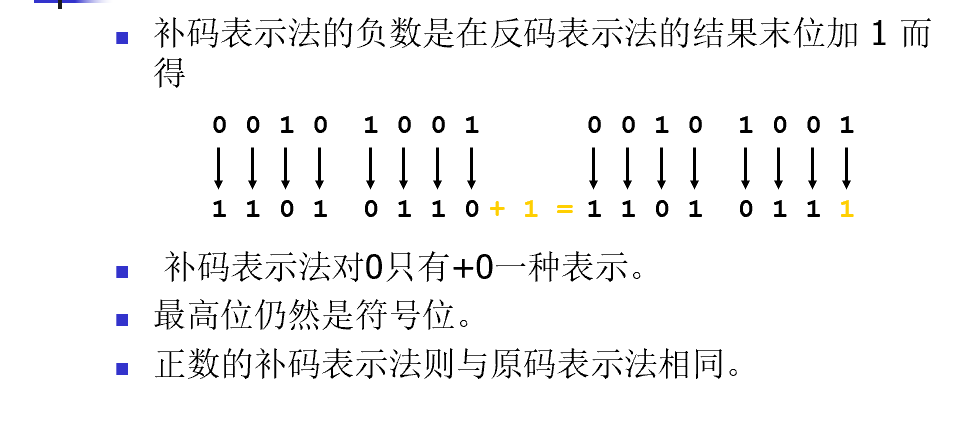
带符号和无符号
- C和C++ 中的整数分为带符号和无符号两种。
- 每一种带符号类型都有对应的无符号类型。
- 带符号整型用来表示正值和负值
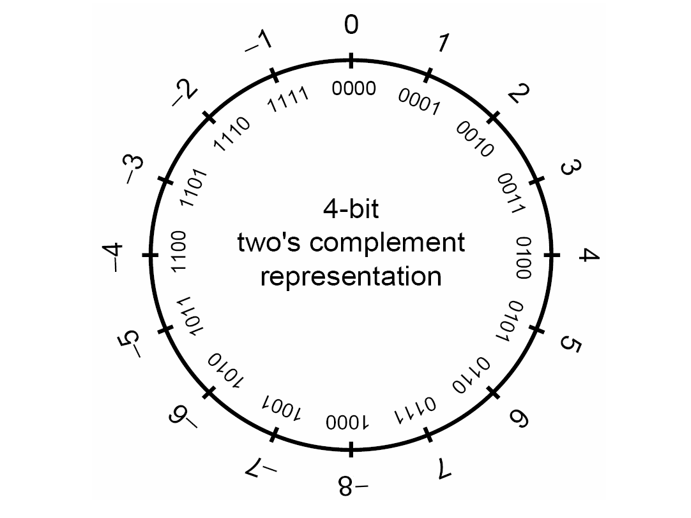
- 在一个使用补码表示法的计算机上,带符号整数的取值范围是 $-2^{n-1}$ 到 $2^{n-1}-1$
4位的有符号补码表示法
4位无符号补码表示法
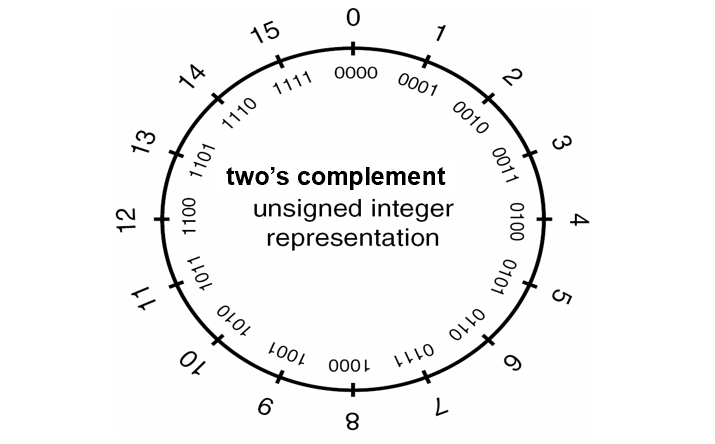
整型类型
整数类型可以分为两大类:标准整型和扩展整型



整数取值范围

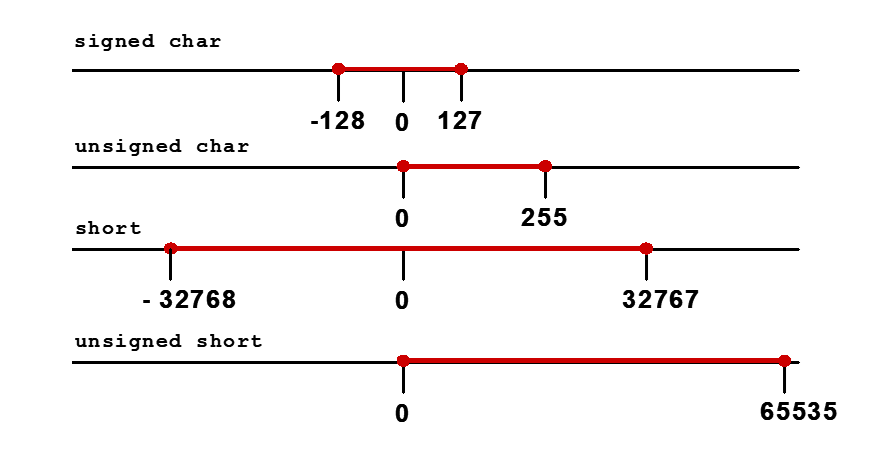
整型转换



整数转换级别
- 每一种整散类型都有一个相应的整型转换级别(integer conversion rank),决定了转换操作将会如何执行
- 没有任何两种不同的带符号整型具有相同的级别,即使它们的(内存)表示法相同
- 低精度的带符号整型的级别比高精度的带符号整型类型的级别低
- long long int类型的级别比long int 高,long int的级别比int高, int的级别比short int高, short int的级别比signed char高
- 无符号整型的级别与对应的带符号整型的级别相同。
从无符号整型转换


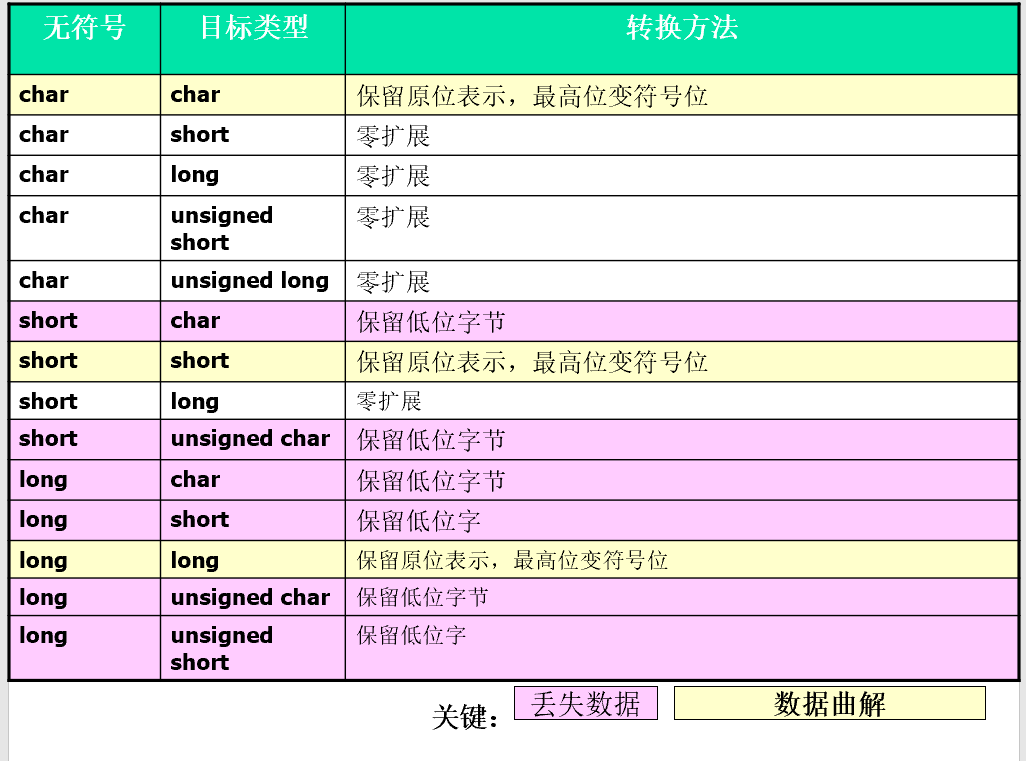
带符号整型转换


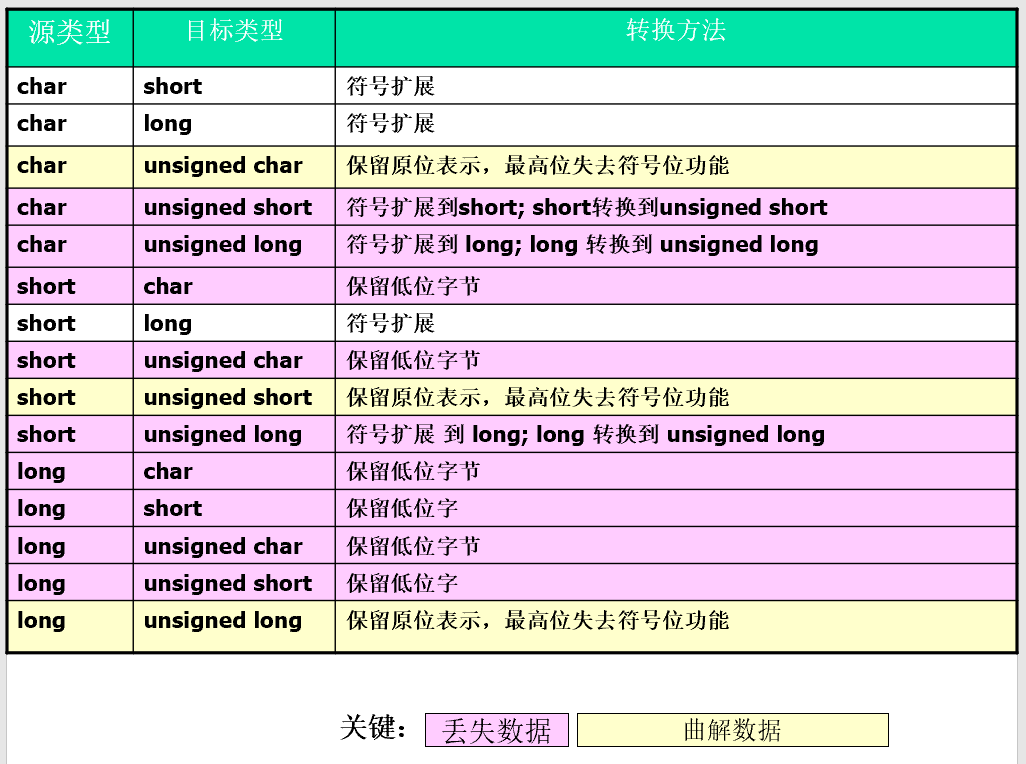
普通算术转换
- 如果两个操作数具有同样的类型,则不需要进一步的转换。
- 如果两个操作数拥有同样的整型(带符号或无符号),具有较低整数 转换级别的类型的操作数会被转换到拥有较高级别的操作数的类型。
- 如果具有无符号整型操作数的级别大子或等于另一个操作数类型的级别,则带符号整型操作数将被转换为无符号整型操作数的类型。
- 如果带符号整型操作数类型能够表示无符号整型操作数类型的所有可能值,则无符号整型操作数将被转换为带符号整型操作数的类型。
- 否则,两个操作数都被转换为与带符号整型操作数类型相对应的无符号整型。
整数错误
整数溢出
- 当一个整数披增加超过其最大值或被减小小于其最小值时即会发生整数溢出
- 带符号和无符号的数都有可能发生溢出
符号错误
从无符号整型转换到带符号整型,它们是
- 相同大小-位模式保留不变; 最高位变成符号位
- 更大- 进行符号扩展,然后才执行转换
- 更小-保留低位
如果无符号整数的最高位
- 没被设置- 值不变
- 被设置 – 变成负值
带符号整型转换到无符号整型,它们是
- 相同大小-位模式保留不变; 最高位变成符号位
- 更大- 进行符号扩展,然后才执行转换
- 更小-保留低位
如果带符号整数的值是
- 非负的- 值不变
- 负的 -结果通常是一个很大的正值
截断错误
截断错误发生于
- 将一个较大整型的数转换到较小的整型
- 该数的原值超出较小类型的表示范围
原值的低位被保留下来而高位则被丢弃。
整数错误侦测
通过硬件


先验条件

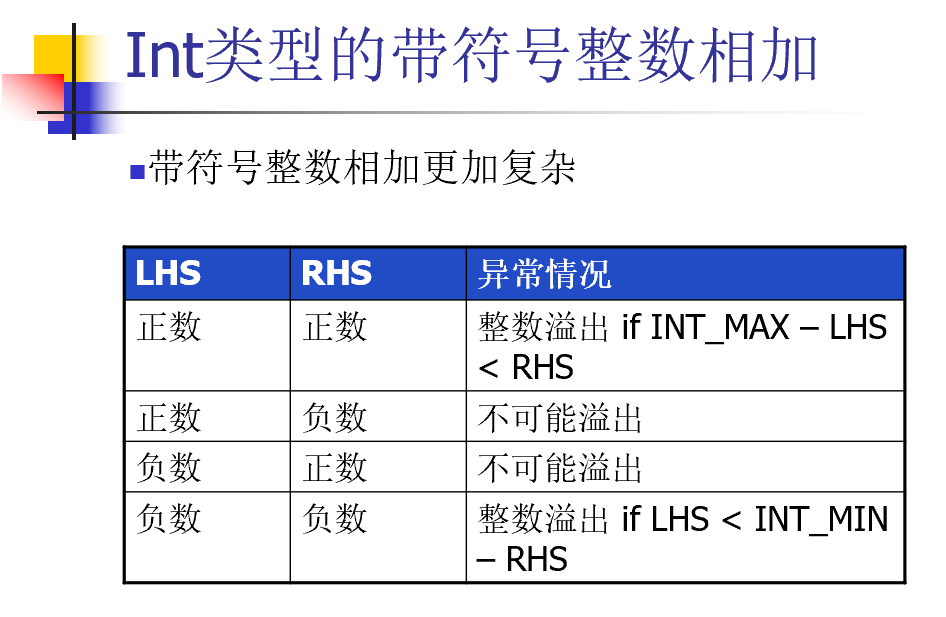



后验条件



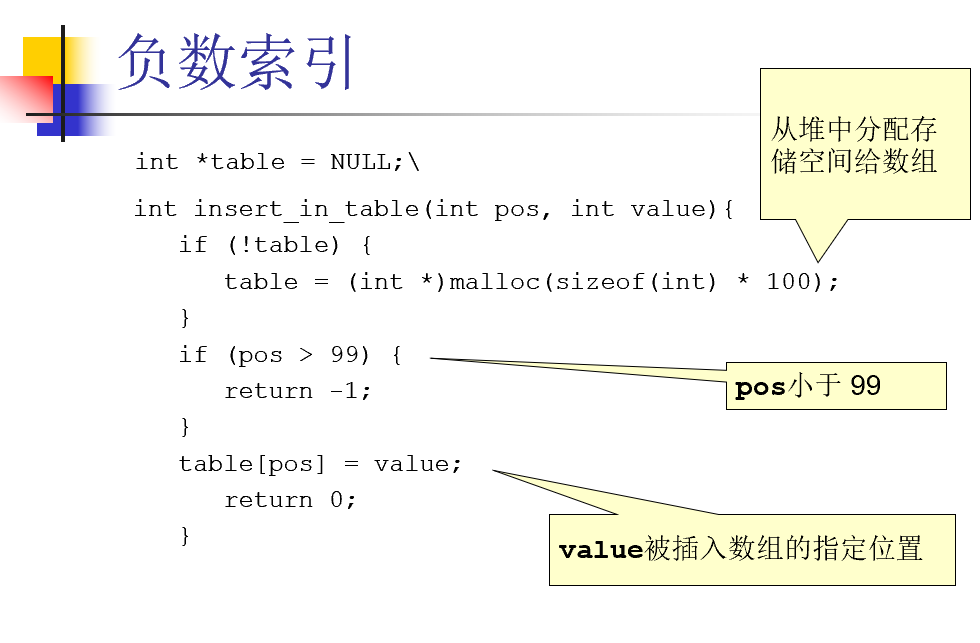
漏洞
1.JPEG例子


2.内存分配例子


3.符号错误例子

4.截断漏洞
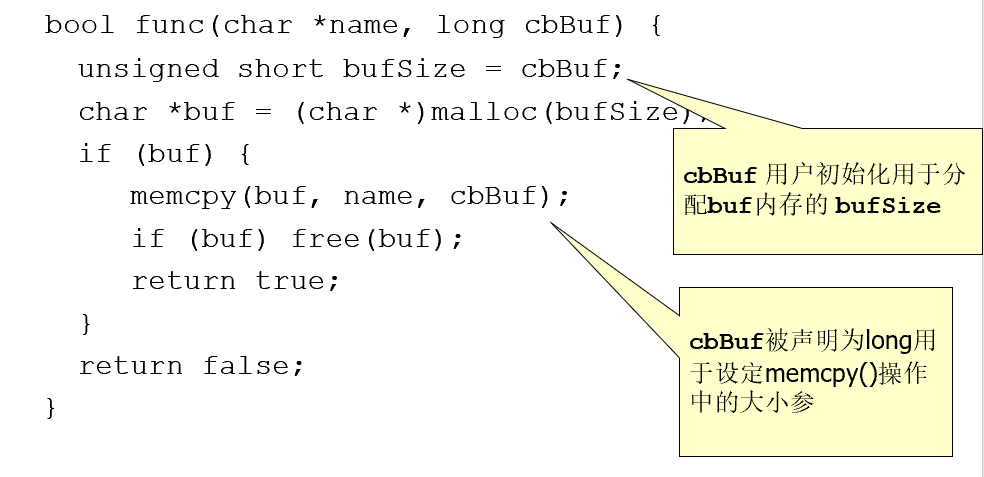


5.非异常的整数逻辑错误

缓解策略
范围检查


强类型

抽象数据类型

SafeInt类


格式化输出
格式化输出函数
格式化输出函数是由一个格式字符串和可变数目的参数构成
- 格式化字符串提供了一组可以由格式化输出函数解释执行的指令
- 用户可以通过控制格式字符串的内容来控制格式化输出函数的执行
格式化输出函数
- fprintf()按照格式字符串的内容将输出写入流中。流、格式字符串和变参列表一起作为参数提供给函数。
- printf()等同于fprintf(),除了前者假定输出流为stdout外。
- sprintf()等同于fprintf() ,但是输出不是写入流而是写入数组中。
- snprintf()等同于sprintf() ,但是它指定了可写入字符的最大值n。当n非零时,输出的字符超过“n-1”的部分会被舍弃而不会写入数组中。并且,在写入数组的字符末尾会添加一个空字符。
格式字符串
- 格式字符串是由普通字符(包括%)和转换规范构成的字符序列。
- 普通字符被原封不动地复制到输出流中。
- 转换规范根据与实参对应的转换指示符对其进行转换,然后将结果写入输出流中。转换规范通常以%开始按照从左向右的顺序解释。
%[flags] [width] [.precision] [{length-modifier}] conversion-specifier.- 当参数过多时,多余的将被忽略。
- 而当参数不足时,则结果是未定义的。
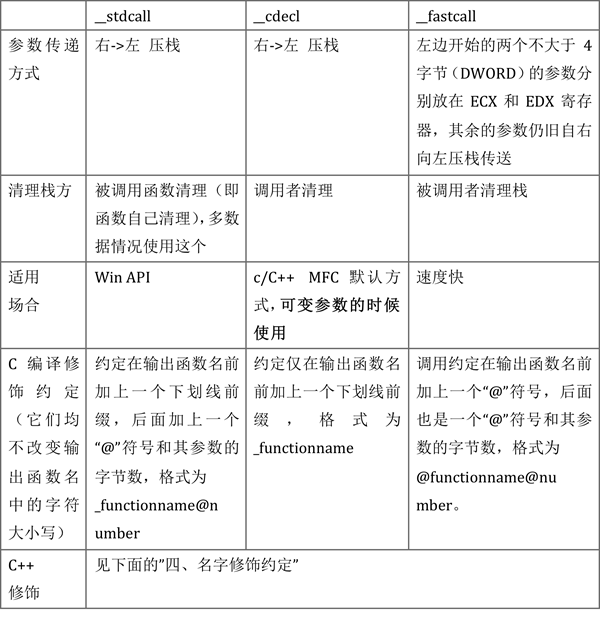
函数调用约定
漏洞利用
使程序崩溃
原理
- 在UNIX系统中,存取无效的指针会引起进程收到SIGSEGV信号。除非能够捕捉并处理,否则程序将会非正常终止并导致核心转储(dump core )
- 与之类似,在Windows中读取一个未映射的地址将会导致系统的一般保护错误并导致程序非正常终止。
构造
当用以下格式字符串调用格式化输出函数时,就会触发无效指针存取或未映射的地址读:
printf("%s%s%s%s%s%s%s%s%s%s%s%s");
转换指示符%s显示执行栈上相应参数所指定的地址的内存。
由于在这个例子中没有提供字符串参数,因此printf()可以依次读取栈中该格式字符串开始后的内存位置,直到格式字符串耗尽或者遇到一个无效指针或未映射地址为止。
查看栈内容
printf("%08x%08x%08x%08x")
格式字符%08x%08x%08x%08x指示函数printf()从栈中取回4个参数并将它们以8位十六进制数的形式显示出来。
同理可以把%x换成%s来查看内存内容,同时可以使用%x来占位,向前推进%s使其达到想要查看的地址
覆写内存
printf("\xdc\xf5\x42\x01%08x.%08x.%08x%n”);
利用%08x推进%n使其对应我们构造的地址0x0142f5dc,然后printf执行后会将输出的字符个数写入到该地址达到覆写内存的目的
缓解策略
- 限制字节写入来控制缓冲区溢出
- 使用具有增强的安全性的函数
- C++可以使用iostream库,这个库提供了通过流来实现输入输出的功能
并发
并发机制
并发是一种系统属性,是指系统中几个计算同时执行,并可能彼此交互。
多线程与并发
- 多线程不一定是并发的,一个多线程程序可以以不并发的方式执行。
- 一个多线程程序分成可以并发执行的两个或更多线程。每个线程都作为一个单独的程序,但所有线程都在相同的内存中工作,并共享相同的内存。
- 线程之间的切换速度比进程间切换更快,多个线程可以在多个CPU 上并行执行,以提高性能收益。
- 单CPU支持多线程(超线程,hyperthreading)
多线程安全
- 多线程因执行次序易产生潜在灾难性问题
- 一个单线程的程序是完全不会产生任何额外线程的程序。
- 单线程程序通常并不需要担心同步,并可以受益于强大的单核处理器
- 单线程不能从多核的性能中受益,因为所有的指令必须在一个处理器的单个线程上按顺序运行。
- 单线程程序可能有并发问题
并行与并发
- 并行就是物理上的同时运行,多个处理器同时运行同一个任务
- 并发则是逻辑上的”同时运行”,是一个处理器在一个任务处于等待状态去运行另一个任务,然后再回来执行该任务,cpu始终处于忙碌状态,从而给人的感觉是同时执行了两个任务
数据并行与任务并行
并行包括数据并行(data parallelism)和任务并行(task parallelism)
- 数据并行把问题分解成数据段,且并行应用于一个函数。是高性能计算的基础
- 任务并行是指将一个问题分解成可以共享数据的不同任务,各任务在同一时间执行,但执行不同的功能
并行的性能目标
并行的性能目标是并行度(parallelism)
- 用来表示工作(所有指令花费的总时间)跨度(执行最长的并行执行路径或关键路径所花费的时间)比
- 其值表示沿关键路径的每个步骤完成的平均值,并且是任意数量的处理器可能获得的最大加速比
- 可实现的并行度受限于程序结构,依赖于它的关键路径和工作量
例一:
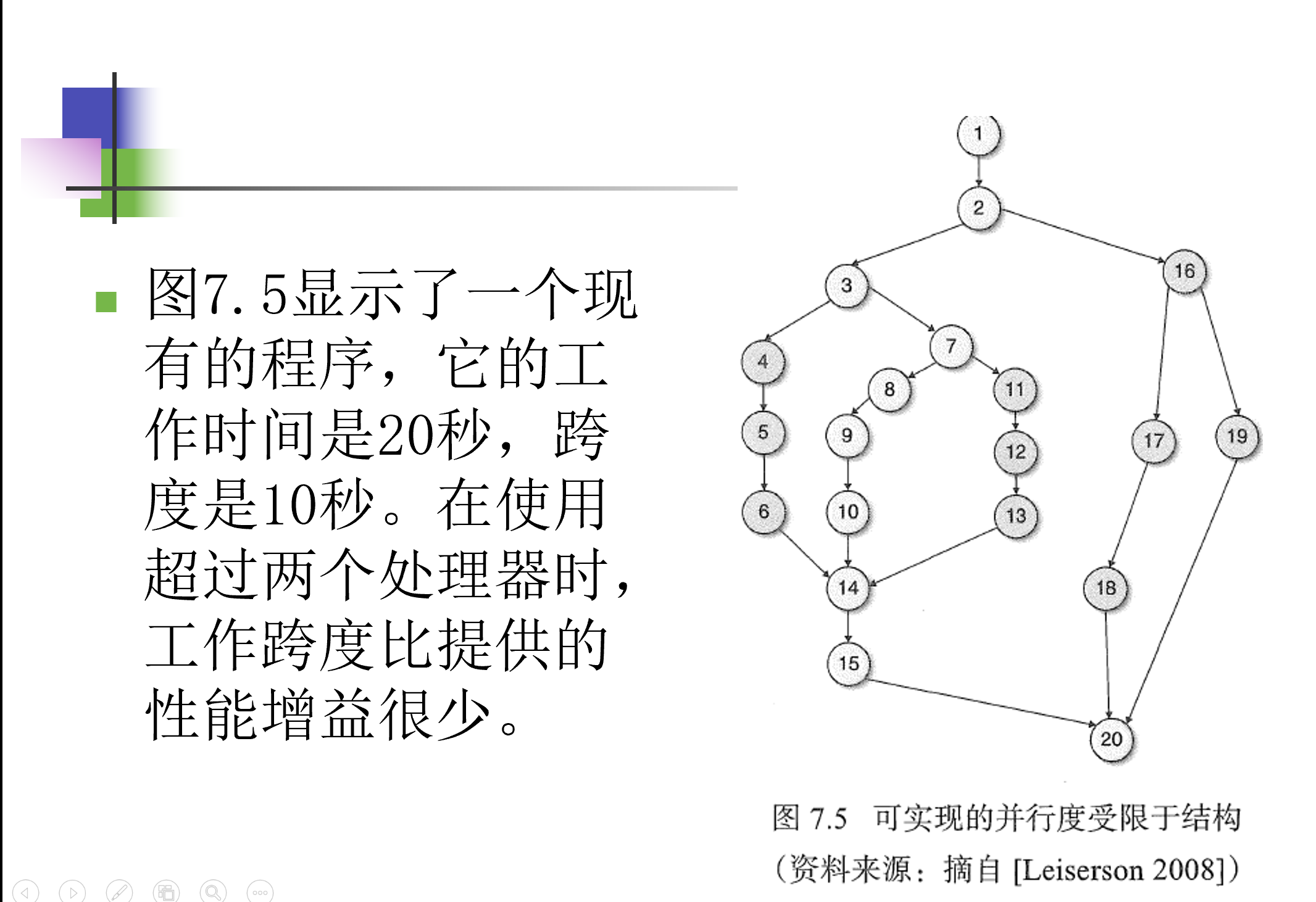
例二:
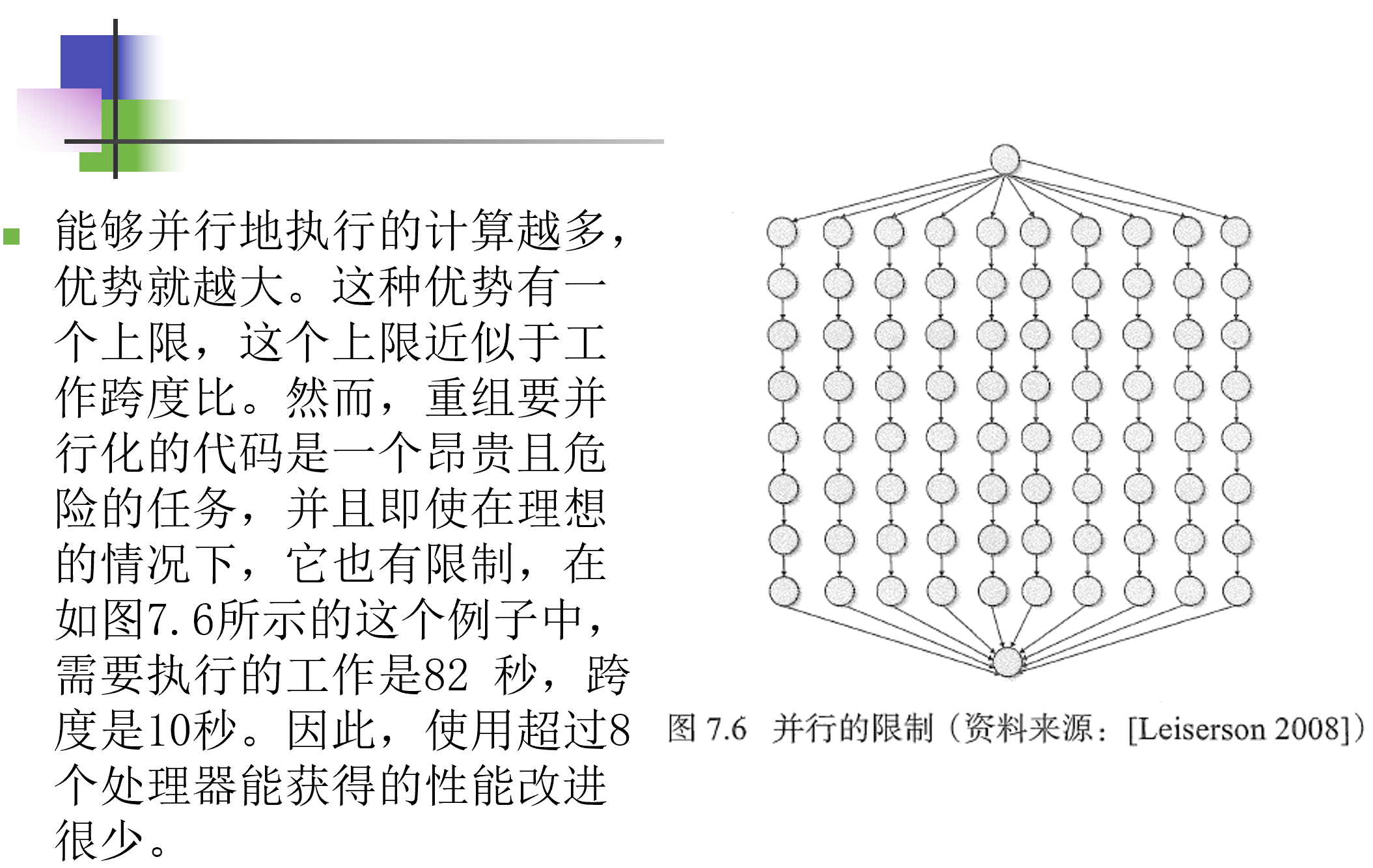
常见错误
竞争条件
竞争条件难以察觉、重现和消除,并可能导致错误,如数据损坏或崩溃
成因:竞争条件是运行时环境导致的,这个运行时环境包括必须对共享资源的访问进行控制的操作系统,特别是通过进程调度进行控制的
损坏的值
如8位存储平台上写入16位数值
易变的对象

缓解策略
同步原语
在竞争窗口之前获取同步对象,然后在窗口结束后释放它,使竞争窗口中关于使用相同的同步机制的其他代码是原子的。
竞争窗口最终成为一个代码临界区。所有临界区对执行临界区的线程以外的所有适当的同步线程都是原子的。
锁机制
防止临界区并发执行的策略中,大多数涉及锁机制
锁机制导致一个或多个线程等待,直到另一个线程退出临界区。
互斥量
最简单的一种锁机制是称为互斥量的一个对象。
- 互斥量有两种可能的状态:锁定和解锁。
- 一个线程锁定一个互斥量后,任何后续试图锁定该互斥量的线程都将被阻止,直到此互斥量被解锁为止。
- 当互斥量解锁后,阻塞线程可以恢复执行,并锁定互斥量以继续。
- 互斥量可确保一次只有一个线程可以运行花括号内的代码,从而使程序是线程安全的。互斥量不与任何其他数据关联,只是作为锁对象。
原子操作
原子操作是不可分割的。一个原子操作不能被任何其他的操作中断,当正在执行原子操作时,它访问的内存,也不可以被任何其他机制改变。因此,必须在一个原子操作运行完成后,其他任何事物才能出问该操作所使用的内存,
原子操作不能被划分成更小的部分。简单的机器指令,例如,装载一个寄存器,可能是不可中断的。被一个原子加载访问的内存位置不可以由其他任何线程访问,直到此原子操作完成。
原子对象是保证它执行的所有操作都是原子的任何对象。通过对某个对象上的所有操作施加原子性,一个原子对象不会被同时读取或写人破坏。原子对象不存在数据竞争,虽然它们仍然可能会受到竞争条件的影响。
不可变数据结构
提供线程安全的一种常用的方法是简单地防止线程修改共享数据,在本质上,即是使数据只读。保护不可改变的共享数据不需要锁。
在C 和C++中一种常见的战术是声明一个共享对象为const(常量)。
另一种方法是复制一个线程可能要修改的任何对象。在这种情况下,所有共享对象都是只读的,任何需要修改一个对象的线程都创建一个共享对象的私有副本,其后只能用它的副本工作。因为副本是私有的,所以共享的对象仍然是不变的。
线程安全
线程安全函数的使用可以帮助消除竞争条件。根据定义,一个线程安全函数通过锁或其他互斥机制来防止共享资源被并发访问。因此,一个线程安全的函数可以同时被多个线程调用,而不用担心。
如果一个函数不使用静态数据或共享资源,它明显是线程安全的。然而,使用全局数据引发了线程安全的红旗,且任何对全局数据的使用必须同步,以避免竞争条件。为了使一个函数成为线程安全的,它必须同步访问共享资源。特定数据的访问或整个库可以锁定。然而,在库上使用全局锁会导致争用(contention)
可重入
可重入(reentrant) 函数也可以减轻并发编程错误。函数是可重入的,是指相同函数的多个实例可以同时运行在相同的地址空间中,而不会创建潜在的不一致的状态。
IBM定义的可重入函数,是指它在连续调用时不持有静态数据,也不会返回一个指向静态数据的指针。因此,可重入函数使用的所有数据都由调用者提供,并且可重人函数不能调用不可重人函数。可重人函数可以中断,并重新进入(reentered) 而不会丢失数据的完整性,因此,可重人函数是线程安全的[IBM 2012b] 。
缓解陷阱
并发实现的常见错误
- 没有用锁保护共享数据(即数据竞争)
- 当锁确实存在时,不使用锁访问共享数据
- 过早释放锁
- 对操作的一部分获取正确的锁,释放它,后来再次取得它,然后又释放它,而正确的做法是一直持有该锁
- 在想要用局部变量时,意外地通过使用全局变量共享数据
- 在不同的时间对共享数据使用两个不同的锁
- 由下列情况引起死锁
- 不恰当的锁定序列(加锁和解锁序列必须保持一致)
- 锁定机制使用不当或错误选择
- 不释放锁或试图再次获取已经持有的锁
- 缺乏公平——所有线程没有得到平等的机会来获得处理。
- 饥饿——当一个线程霸占共享资源、阻止其他线程使用时发生。
- 活锁——线程继续执行,但未能获得处理。
- 假设线程将
- 以一个特定的顺序运行
- 不能同时运行
- 同时运行
- 在一个线程结束前获得处理
- 假设一个变量不需要锁定,因为开发人员认为只有一个线程写人它且所有其他线程都读取它。这还假定该变量上的操作是原子的。
- 使用非线程安全库。如果一个库能保证由多个线程同时访问时不会产生数据竞争,那么认为它是线程安全的。
- 依托测试,以找到数据竞争和死锁。
- 内存分配和释放问题。当内存在一个线程中分配而在另一个线程中释放时,这些问题可能出现,不正确的同步可能会导致内存仍然被访问时被释放。
死锁
- 同步原语的不正确使用可能会导致死锁
- 当两个或多个控制流以彼此都不可以继续执行的方式阻止对方时,就会发生死锁。
- 特别是,对于一个并发执行流的循环,如果其中在循环中的每个流都已经获得了导致在循环中随后的流悬停的同步对象,则会发生死锁。
- 死锁(和其他的数据竞争)可能对以下条件敏感:
- 处理器速度
- 进程或线程调度算法的变动
- 在执行的时候,强加的不同内存限制
- 任何异步事件中断程序执行的能力
- 其他并发执行进程的状态
著名漏洞
- 在多核动态随机访问存储器系统中的DoS攻击
- 系统调用包装器中的并发漏洞
文件输入输出
文件I/O基础
文件系统
程序与文件系统交互方式的不规则性是文件IO漏洞的根源
UNIX
- UFS,即UNIX File System
- 多数厂商改写了UFS以适应自己的用途,增加了可能不被其它厂商的UNIX版本认可的专有扩展
Linux
- 早期的MINIX、MS-DOS和ext2文件系统
- 较新的日志文件系统,如ext4、日志文件系(Joumaled File System, JFS) 和ReiserFS等
- 加密文件系统(Cryptographic File System, CFS)和虚拟文件系统/proc
Mac OS X
- HFS+:Hierarchical File System Extended Format,分层文件系统扩展格式
- UPS:BSD标准文件系统格式
- NFS:Network File System,网络文件系统
- AFP:AppleTalk文件协议[Mac OS文件共享]
- UDF:Universal Disk Format,通用磁盘格式
- ……
文件
文件是由块(通常在磁盘上)的集合组成
目录
目录是由目录条目的列表组成的特殊文件。
目录条目的内容包括目录中的文件名和相关的i-节点的数量
i-节点
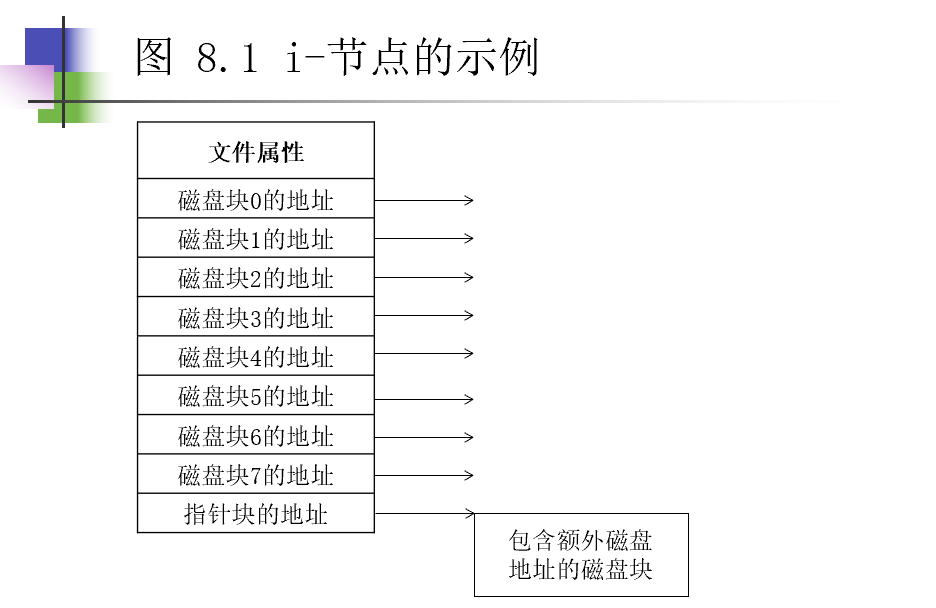
MS-DOS 文件名
- 用路径(path)名来代替一个文件名
- 路径名包含文件、目录的名称,以及如何浏览文件系统来找到该文件的信息
- 路径名分为绝对路径和相对路径,多个路径名可以解析到同一个文件
文件IO接口
C中的文件IO接口在
IO操作的安全性依赖于具体的编译器实现、操作系统和文件系统
字节输入函数
- fgetc()
- fgets()
- getc()
- getchar()
- fscanf()
- scanf()
- vfscanf()
- vscanf()
字节输出函数
- fputc()
- fputs()
- putc()
- putchar()
- fprintf()
- vfprintf()
- vprintf()
宽字节输入函数
- fgetwc()
- fgetws()
- getwc()
- getwchar()
- fwscanf()
- wscanf()
- vfwscanf()
- vwscanf()
宽字节输出函数
- fputwc()
- fputws()
- putwc()
- putwchar()
- fwprintf()
- wprintf()
- vfwprintf()
- vwprintf()
C文本流
标准C程序在启动时,预定义了3个文本流,操作前不必打开它们:
- stdin:标准输入(用于读常规输入)
- stdout:标准输出(用于写常规输出)
- stderr:标准错误(用于写入诊断输出)
文本流stdin、stdout和stderr是FILE指针类型的表达式。在最初打开时,标准错误流不是完全缓冲的。如果流不是一个交互设备,那么标准输入和标准输出流是完全缓冲的
C++文件IO
- C++中提供与C相同的系统调用和语义,只有语法是不同的。C++的
库包括了 ,后者是 的C++版本。因此, C++支持所有的C的IO函数调用以及 对象。 - C++中的文件流不使用FILE,而使用ifstream 处理基于文件的输入流,用ofstream处理基于文件的输出流,用iofstream同时处理输入和输出的文件流。所有这些类都继承自fstream 并操作字符(字节)。
- 对于使用wchar_t的宽字符IO,使用wofstream、wifstream、wiofstream、wfstream来处理。
C++提供下列的:
- cin取代stdin用于标准输入
- cout取代stdout用于标准输出
- cerr取代stderr用于无缓冲标准错误
- clog用于缓冲标准错误,对记录日志有用流来操作字符(字节)
- 对于宽字符流,使用wcout、wcin、wcerr、wclog
打开、关闭文件
文件打开
fopen()函数打开一个文件,其名称是由文件名指向的字符串,并把它与流相关联。
FILE *fopen(
const char* restrict filename,
const char* restrict mode,
);
参数mode 指向一个字符串,如果该字符串是有效的,那么该文件以指定的模式打开;否则,其行为是未定义的。
C99支持以下模式:
- r:打开文本文件进行读取(只读文件)
- w: 截断至长度为零或创建文本文件用于写入
- a: 追加;打开或创建文本文件用于在文件结束处写入
- rb:打开二进制文件进行读取
- wb: 截断至长度为零或创建二进制文件用于写入
- ab: 追加;打开或创建二进制文件用于在文件结束处写入
- r+: 打开文本文件用于更新(读取与写入)
- w+: 截断至零长度或创建文本文件用于更新
- a+: 追加;打开或创建文本文件用于在文件结束处更新和写人
- r+b或rb+: 打开二进制文件用于更新(读取与写入)
- w+b或wb+: 截断至长度为零或创建二进制文件用于更新
- a+b或ab+: 追加;打开或创建二进制文件用于在文件结束处更新和写入
C11增加的独占模式:
- wx:创建独占文本文件用于写入
- wbx:创建独占的二进制文件用于写入
- W+X:创建独占的文本文件用于更新
- w+bx或wb+x:创建独占的二进制文件用于更新
文件关闭
- fclose()函数用来关闭文件流,任何未写入的缓存数据流被传递到主机环境,并被写入到该文件中。任何未读的缓存数据将被丢弃
- 关闭相关文件(包括标准文本流)后,一个指向FILE对象指针的值是不确定的。引用一个不确定的值是未定义的行为
- 长度为零的文件(在它上面没有已写人输出流的字符)是否确实存在是实现定义的
- 关闭的文件可能随后被相同或另一个程序的执行重新打开,并且其内容被回收或修改。
- 如果main() 函数返回到原来的调用者或如果调用exit() 函数时,所有打开的文件在程序终止之前关闭(且所有的输出流被刷新)。
- 其他终止程序的路径,如调用abort()函数,不必正确地关闭所有文件。因此,尚未写入到磁盘中的缓冲数据可能会丢失。
- Linux保证,甚至在程序异常终止时,这个数据也被刷新到磁盘文件。
文件访问控制
UNIX文件权限
权限与特权
- 特权( privilege)是通过计算机系统委派的权限,特权位于用户、用户代理或替代,如UNIX 进程中。相对主体而言!
- 权限(permission)是访问资源所必要的特权,因此它与资源(如文件)相关。相对客体而言!
- 特权模型往往是特定于系统且复杂的。在管理特权和权限中的错误往往直接导致安全漏洞。
用户与认证
- 用户名用一个用户ID(User ID, UID) 来确定
- 把一个用户名映射到一个UID所需的信息保存在/etc/passwd文件中
- 超级UID(root) 的UID为0,它可以访问任何文件
- 每个用户都属于一个组,因此也有一个组ID,或GID。用户还可以属于补充组。
- 用户提供自己的用户名和密码给UNIX 系统作身份验证。login程序检查/etc/passwd或shadow文件/etc/shadow来确定用户名是否对应到该系统上的有效用户,并检查提供的密码是否与该UID 所关联的密码对应。
文件的特权与权限
-
UNIX文件系统中的每个文件都有一个所有者(UID)和一个组(GID)。所有权用于决定了哪些用户和进程可以访问文件,所有权属于文件的所有者或root,这种特权不能被委派或共享。
-
文件权限包括
- 读:读一个文件或列出一个目录的内容
- 写:写入到一个文件或目录
- 执行:执行一个文件或递归一个目录树
-
文件权限对于下列每种用户类别可以授予或撤销:
- 用户:该文件的所有者
- 组:属于文件的组成员的用户
- 其他:不是文件的所有者或组成员的用户
-
文件权限表示
文件权限一般都是用八进制的向量表示,八进制从左到右分别表示读、写和执行的权限
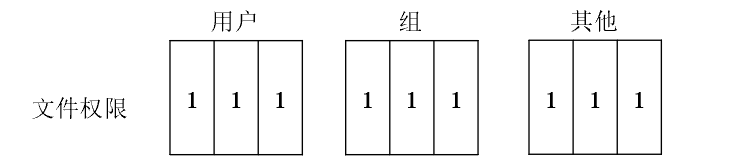
-
文件访问控制
当访问一个文件时,进程的有效用户ID(Effective User ID,EUID)与文件所有者的UID进行比对,如果该用户不是所有者,那么再对GID进行比较,然后再测试其他
文件鉴定
目录遍历
特殊文件名
- “.” 表示当前目录
- “..” 表示当前目录的上一级目录。但是如果当前目录是根目录,则其上一级目录仍然是根目录
- 在Windows系统上,还可能提供驱动器盘符(例如C:),以及其他特殊文件名,如“…”,它相当于“../..”
目录遍历漏洞
如果服务器接收如”../“形式的输入而没有适当的验证,那么就会允许攻击者遍历文件系统来访问任意文件,例如:/home/../etc/shadow会被解析成/etc/shadow
等价错误
当一个攻击者提供不同但等效名字的资源来绕过安全检查时,就会发生路径等价漏洞
例如
- “
http://host/./admin/”在功能上等价于http://host/admin,但遗憾的是,在这种情况下,它绕过验证。 - 等价错误的另一大类来自区分大小写的问题:
/home/PRIVATE==/home/private(注意Apache区分大小写) - 其它等价错误包括前导或尾随空白、前导或尾随文件分隔符、内部空格或星号通配符等
符号链接
符号链接(symbolic link)是一个方便的解决文件共享的方案
符号链接实际上创建了一个具有特殊的i-节点(i-node)的新文件。符号链接是特殊的文件,其中包含了实际文件的路径名
如果路径名称解析过程中遇到符号链接,则用符号链接的内容替换链接的名称。例如:一个路径名/usr/tmp,其中tmp是一个指向../var/tmp的符号链接,那么它就被解析成/usr/../var/tmp,由于..这进一步又被解析为 /var/tmp
竞争条件
检查时间和使用时间
文件I/O期间可能出现检查时间和使用时间(Time Of Check, Time Of Use , TOCTOU)竞争条件。首先测试(检查)某个竞争对象属性,然后再访问(使用)此竞争对象,TOCTOU竞争条件形成一个竞争窗口。
TOCTOU漏洞可能是首先调用stat(),然后调用open(),或者它可能是一个被打开、写入、关闭,并被一个单独的线程重新打开的文件,或者它也可能是先调用一个access(),然后再调用fopen()

创建而不替换

如果在open()调用执行时file_name已经存在,那么打开该文件,并截断它。如果file_name是一个符号链接,那么该链接引用的目标文件被截断。攻击者所有需要做的事就是在此调用之前在file_name创建一个符号链接。假设这个有漏洞的过程有相应的权限,那么目标文件将被覆写。
独占访问
由独立的进程产生的竞争条件不能用同步原语来解决,因为这些过程不可能访问共享的全局数据(如一个互斥变量)。
通过将文件当作锁来使用,仍可以同步这类并发控制流。例8.15包含两个函数,它们实现了一个Linux文件锁机制。对lock()的调用用于获得锁,而对unlock()的调用则可以释放锁
int lock(char *fn) { //例8.15
int fd;
int sleep_time = 100;
while (((fd = open(fn, O_WRONLY | O_EXCL |
O_CREAT, 0)) == -1) && errno ==EEXIST) {
usleep(sleep_time);
sleep_time *= 2;
if (sleep_time > MAX_SLEEP)
sleep_time = MAX_SLEEP;
}
return fd;
}
void unlock(char *fn) {
if (unlink(fn) == -1) {
err(1, “file unlock”);
}
}
共享目录
- 当两个或更多用户,或一组用户都拥有对某个目录的写权限时,共享和欺骗的潜在风险比对几个文件的共享访问情况要大得多。
- 程序员经常在对所有用户都是可写(如UNIX上的/tmp和/var/tmp目录和Windows上的C:\TEMP)并可以定期清除(例如,每天晚上或重启时)的目录中创建临时文件。
- 这是一个危险的做法,因为一个在共享目录中的众所周知的文件很容易被攻击者劫持或操纵。缓解策略包括以下内容:
- 使用其他低级别的IPC (进程间通信)机制,如套接字或共享内存
- 使用更高级别的IPC 机制,如远程过程调用。
- 使用只能被应用实例(确保在同一平台上运行的应用程序的多个实例不存在竞争)访问的安全目录或jail
- 在共享目录创建临时文件没有完全安全的方式。为了降低风险,可以把文件创建为具有独特并且不可预知的文件名、仅当文件不存在时打开(原子打开)、用独占访问模式打开、用适当权限打开,并在程序退出之前删除。
缓解策略
关闭竞争端口
互斥缓解方案
UNIX和Windows支持很多能够在一个多线程应用程序中实现临界区的同步原语,包括互斥变量、信号量、管道、命名管道、条件变量、CRITICAL_SECTION(临界区)对象以及锁变量等。
线程间的同步可能引入死锁的潜在威胁。当进程从饥饿状态转变为恢复执行时,存在相关联的活锁( live lock) 问题。
避免死锁的标准措施是要求资源的获取按照特定的顺序进行。从概念上说,所有要求互斥的资源都可以被编号为r1、r2、…、rn。只要保证进程在捕获资源rk之前已经捕获了所有的资源 rj (其中j < k) ,就可以避免死锁。
线程安全的函数
在多线程应用程序中,仅仅确保应用程序自己的指令内不包含竞争条件是不够的,被调用的函数也有可能造成竞争条件。当宣告一个函数为线程安全的时候,就意味着作者相信这个函数可以被并发线程调用,同时该函数不会导致任何竞争条件问题。不应该假定所有函数都是线程安全的,即使是操作系统提供的API。当要使用的函数必须为线程安全时,最好去查阅它的文档以确认这一点。
如果必须调用一个非线程安全的函数,那么最好将它处理为一个临界区,以避免与任何其他代码调用冲突。
使用原子操作
同步原语依赖于原子(不可分割的)操作。当调用了Enter 'CriticalRegion()或pthreadmutex-lock()之后,本质上直到函数运行完成为止,该函数都不会被中断。如果一个EnterCriticalRegion()调用允许与另一个EnterCriticalRegion()调用(也许是由另一个线程调用的)重叠,或者与一个LeaveCriticalRegion() 调用重叠,那么这些函数内部可能会存在竞争条件。正是这种原子属性使得这些函数在同步操作中非常有用。
重新打开文件
重新打开一个文件流一般应避免,但对于长期运行的应用程序,这可能是必要的,以避免消耗可用文件描述符。由于文件名在每次打开时重新与文件关联,因此无法保证重新打开的文件就是原始文件。
检查符号链接
消除竞争对象
软件开发人员也应该消除对系统资源不必要的使用,以尽量减小漏洞的暴露。比方说,Windows的ShellExecute()函数尽管是为打开一个文件提供了便利的方式,但是这个命令依赖于注册表来选择一个将要应用于文件的应用程序。显而易见,调用CreateProcess()并显式指定应用程序的做法比依赖注册表更可取。
使用文件描述符而非文件名

控制对竞争对象的访问
最小特权原则
可以通过减少进程的特权来消除竞争条件,而其他时候减少特权仅仅可以限制漏洞的暴露。无论如何,最小特权原则都是一种缓解竞争条件以及其他漏洞的明智策略
暴露
避免通过用户接口或其他的API 暴露你的文件系统的目录结构或文件名
一个更好的方法可能是让用户指定一个键作为标识符。然后,此键可以通过一个哈希表或其他数据结构映射到文件系统中一个特定的文件,而不把文件系统直接暴露给攻击者。
竞争检测工具
静态分析
静态分析工具并不通过实际执行软件来进行竞争条件软件分析。这种工具对软件源代码(或者,在某些情况下,二进制执行行文件)进行解析,这种解析有时依赖于用户提供的搜索信息和准则。静态分析工具能报告那些显而易见的竞争条件,有时还能根据可察觉的风险为每个报告项目划分等级。
动态分析
动态分析工具通过将侦测过程与实际的程序执行相结合,克服了静态分析工具存在的一些问题。这种方式的优势在于可以使工具获得真实的运行时环境。只分析实际的执行流具有一个额外的好处,即可以减少必须由程序员进行分析的误报情况。
动态侦测的主要缺点包括:(1) 动态工具无法侦测未执行到的路径; (2) 动态检测通常会带来巨大的运行时开销。
软件安全实践
基本没讲,可以忽略
安全生命周期
安全需求
安全设计
安全实现
安全验证
参考资料
- 课件:https://pan.baidu.com/s/1yHB1R2J2Uc1EVV-T8JQHAw
- https://zh.wikipedia.org/wiki/%E5%B7%AE%E4%B8%80%E9%94%99%E8%AF%AF
- https://baike.baidu.com/item/%E8%99%9A%E5%87%BD%E6%95%B0