shellcode是什么
shellcode是一段用于利用软件漏洞而执行的代码,shellcode为16进制的机器码,因为经常让攻击者获得shell而得名。shellcode常常使用机器语言编写。 可在暂存器eip溢出后,塞入一段可让CPU执行的shellcode机器码,让电脑可以执行攻击者的任意指令。 ——维基百科
1996 年,Aleph One 在 Underground 发表了著名论文 Smashing the Stack for Fun and Profit,其中详细描述了 Linux 系统中栈的结构和如何利用基于栈的缓冲区溢出。在这篇具有划时代意义的论文中,Aleph One 演示了如何向进程中植入一段用于获得 shell 的代码,并在论文中称这段被植入进程的代码为“shellcode”。
后来人们干脆统一用 shellcode 这个专用术语来通称缓冲区溢出攻击中植入进程的代码。这段代码可以是出于恶作剧目的的弹出一个消息框,也可以是出于攻击目的的删改重要文件、窃取数据、上传木马病毒并运行,甚至是出于破坏目的的格式化硬盘等。 ——0day第二版
shellcode与exploit
我们还会经常看到另一个术语——exploit。
exploit 一般以一段代码的形式出现,用于生成攻击性的网络数据包或者其他形式的攻击性输入。expliot的核心是淹没返回地址,劫持进程的控制权,之后跳转去执行shellcode。与shellcode具有一定的通用性不同,exploit 往往是针对特定漏洞而言的。
exploit 关心的是怎样淹没返回地址,获得进程控制权,把 EIP 传递给 shellcode 让其得到执行并发挥作用,而不关心 shellcode 到底是弹出一个消息框的恶作剧,还是用于格式化对方硬盘的穷凶极恶的代码。
机器码与字节码
机器码:

机器码(machine code),学名机器语言指令,有时也被称为原生码(Native Code),是电脑的CPU可直接解读的数据。通常意义上来理解的话,机器码就是计算机可以直接执行,并且执行速度最快的代码。
字节码:
字节码(英语:Bytecode)通常指的是已经经过编译,但与特定机器代码无关,需要解释器转译后才能成为机器代码的中间代码。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。
字节码主要为了实现特定软件运行和软件环境、与硬件环境无关。字节码的实现方式是通过编译器和虚拟机。编译器将源码编译成字节码,特定平台上的虚拟机将字节码转译为可以直接运行的指令。字节码的典型应用为Java bytecode。
shellcode分类
shellcode常见的分类大致可以分为以下几大类。
具体分类可参考维基百科中文版中的维基百科英文版(先进入中文版)
获取远程shell类
利用软件漏洞获得特定的shellcode,再经由C或Python编写远程攻击程序,进而取得远程主机的shell访问控制权限
修改系统配置类
该类别shellcode执行后可以修改系统配置,从而直接或间接的为攻击者获取系统控制权服务,比如可以添加系统管 理员账户
中转类
该类别shellcode是一种攻击辅助者的角色,不直接对系统造成杀伤,更像是一个中转者的角色,通过执行它将杀 伤性武器“引狼入室”。 比如,从攻击者提供的特定网址下载恶意程序并执行,从而实现更加丰富的攻击效果
验证类
该类别shellcode,仅仅是攻击者或者漏洞研究人员,为了证明其已经具备利用该漏洞执行任意代码的能力
shelcode原理
shellcode调试基础:如何把shellcode放置到内存,让程序跳转到该段内存执行?
- 指向函数的指针
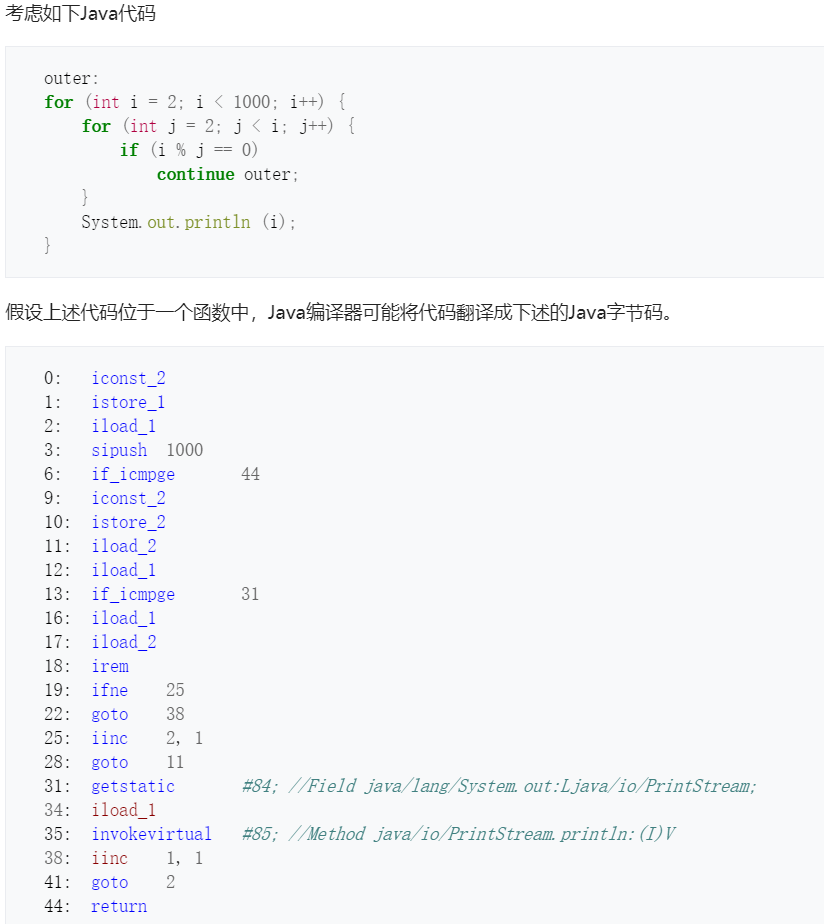
- evil数组中存储的是一段shellcode,该shellcode 功能属于验证类,其在windows_xp sp2系统环境下执行后,可以弹出计算器
#include<stdio.h>
char evil[] = "\xeb\x54\x31\xf6\x64\x8b\x76\x30\x8b\x76\x0c\x8b\x76\x1c\x8b\x6e"
"\x08\x8b\x36\x8b\x5d\x3c\x8b\x5c\x1d\x78\x85\xdb\x74\xf0\x01\xeb"
"\x8b\x4b\x18\x67\xe3\xe8\x8b\x7b\x20\x01\xef\x8b\x7c\x8f\xfc\x01"
"\xef\x31\xc0\x99\x02\x17\xc1\xca\x04\xae\x75\xf8\x3b\x54\x24\x04"
"\xe0\xe4\x75\xca\x8b\x53\x24\x01\xea\x0f\xb7\x14\x4a\x8b\x7b\x1c"
"\x01\xef\x03\x2c\x97\xc3\x68\xe7\xc4\xcc\x69\xe8\xa2\xff\xff\xff"
"\x50\x68\x63\x61\x6c\x63\x8b\xd4\x40\x50\x52\xff\xd5\x68\x77\xa6"
"\x60\x2a\xe8\x8b\xff\xff\xff\x50\xff\xd5";
int main(int argc, char **argv)
{
_asm{
lea eax, evil; //(1)
call eax; //(2)
}
return 0;
}
- (1)处使用汇编指令lea把指针evil赋值给eax
- (2)处使用汇编指令call直接调用寄存器eax所指向的evil函数
- Windbg & 相关shellcode自动执行工具 (scer.exe)
- 手工编写程序调试shellcode有一个大的弊端,即每次shellcode发生改动,均需要重新修改并编译调试程序
- 现成的调试工具,可以大大提高shellcode调试的效率
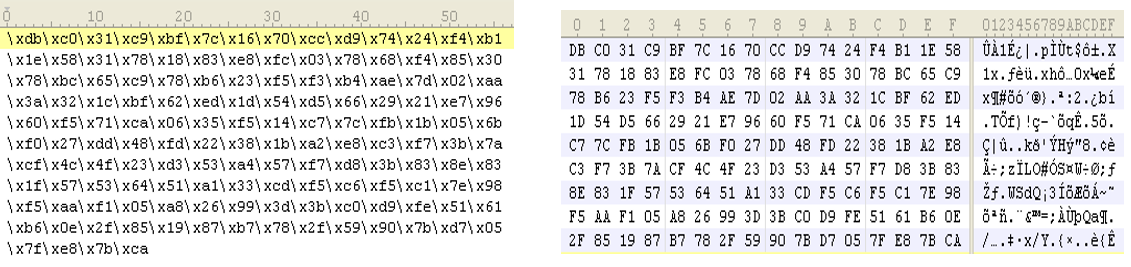
scer.exe的 2 个功能:
1. 把字符形式的shellcode,转换为字节码形式的shellcode:
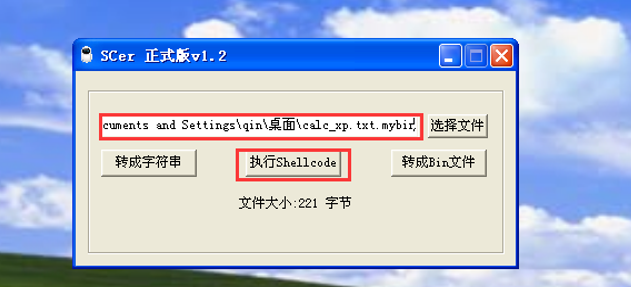
2. 执行shellcode的功能。将shellcode字节 码文件拖入到工具输入框中,点击“执行 Shellcode”按钮,shellcode便可以得到执行:
shellcode编写
Shellcode编写方式基本有3种:
- 直接编写十六进制操作码(不现实);
- 采用像C这样的高级语言编写程序,编译后,进行反汇编以获取汇编指令和十六进制操作码。
- 编译汇编程序,将该程序汇编,然后从二进制中提取十六进制操作码。
注意事项
写shellcode的需要注意的两个重要问题:
-
系统调用的问题。
一般来说,shellcode都是由十几或是几十个字节组成,这样的小程序如果要像linux服务程序一样,引入头文件,导入符号表,调用系统函数,这样的步骤的话;那么短短的几十个字节根本就不能满足需求,这就需要利用系统最核心的调用机制,即通过软中断的方式获取需要的资源,以此来绕开系统调用。
-
坏字符问题
Shellcode如果存储在堆或是栈的内存中,这样在shellcode执行时就不能出现\x00这样的阶段字符,这就需要我们在构造shellcode时防止此类坏字符的出现。
shellcode编码
为什么要对 shellcode 编码? 在很多漏洞利用场景中,shellcode 的内容将会受到限制:
- 首先,所有的字符串函数都会对 NULL 字节进行限制。通常我们需要选择特殊的指令来避免在 shellcode 中直接出现 NULL 字节(byte,ASCII 函数)或字(word,Unicode 函数);
- 其次,有些函数还会要求 shellcode 必须为可见字符的 ASCII 值或 Unicode 值。在这种限制 较多的情况下,如果仍然通过挑选指令的办法控制 shellcode 的值的话,将会给开发带来很大困 难。毕竟用汇编语言写程序就已经不那么容易了;
- 最后,除了以上提到的软件自身的限制之外,在进行网络攻击时,基于特征的 IDS 系统往往也会对常见的 shellcode 进行拦截。
那么如何绕过以上限制呢?
我们可以先专心完成 shellcode 的逻辑,然后使用编码技术对 shellcode 进行编码,使其内容达到限制的要求,最后再精心构造十几个字节的解码程序,放在 shellcode 开始执行的地方。
当 exploit 成功时,shellcode 顶端的解码程序首先运行,它会在内存中将真正的 shellcode 还原成原来的样子,然后执行之。这种对 shellcode 编码的方法和软件加壳的原理非常类似。